粗看长尾,细辨幂律:跨世纪的无标度网络研究纷争史

维弗雷多·帕累托(Vilfredo Pareto ,1848—1923),福利经济学先驱;乔治·金斯利·齐普夫(George Kingsley Zipf,1902-1950),计量语言学先驱;德里克·普莱斯(Derek John de Solla Price,1922-1983),科学计量学之父;赫伯特·亚历山大·西蒙(Herbert Alexander Simon,1916-2001),人工智能先驱;波努瓦·曼德布罗特(Benoit B. Mandelbrot,1924-2010),分形之父;艾伯特-拉斯洛·巴拉巴西(Albert-László Barabási,1967-),当今网络科学研究代表人物、无标度网络概念提出者。
如果能够把这些横跨三个世纪、来自不同领域的科学先驱组织在一起召开主题论坛的话,他们讨论甚至争论的主题也许只有一个:幂律(Power Law)分布。本文通过围绕网络科学中的核心概念——无标度网络、幂律分布以及偏好链接机制的“多次重复发现”和“多轮争议”的故事,与读者分享网络科学研究的曲折而又动人的历程。
一、无标度网络研究的兴起——巴拉巴西的发现
二、生成幂律分布的随机框架之路
三、生成幂律分布的优化框架之路
四、西蒙与曼德布罗特的七轮大战
五、偏好链接:随机还是优化?
六、无标度网络“危机”
七、结束语

本文首发自集智斑图
https://pattern.swarma.org/path?id=83&from=wechat
在科学发展史上,同一个科学发现,以不同的形式、在不同的时间和不同的地点、被不同的科学家重新发现并引起争议的例子是屡见不鲜的,其中的原因包括:一是由于交流不够广泛,使得不少学术成果难以为更多的研究人员所了解。二是由于认识不够深入,开始以为是不同的东西,逐渐才能揭示出共同的本质。
无标度网络无疑属于网络科学过去二十年发展中最重要的概念之一,甚至不少人觉得可以把“之一”两字去掉。而无标度网络及其对应的幂律分布和偏好链接的“多次重复发明”和“多轮争议”作为体现科学发展历程的生动例子确实值得一说。
从网络科学的眼光看,这些研究和争议本身就串成了一个网络,本文希望能够让更多的读者体验到这一网络的精彩纷呈。需要事先声明的是,关于无标度网络研究的文献众多,从经验验证到建模、从特征分析到控制等等。即使是关于其定义本身的研究也有包括我国学者史定华教授在内的一些学者的工作。本文远非无标度网络研究历史的完整记录,而只是围绕着本文的主题,选取其中我们认为有关联的少数节点加以阐述。
一、无标度网络研究的兴起
——巴拉巴西的发现
1999年9月,当时在美国圣母大学任教的巴拉巴西及其学生和博士后在《Nature》上发表了一篇题为“万维网的直径(Diameter of the world-wide web)”的一页纸短文,指出万维网中任意两个网页之间的平均距离为19[1]。
但是,读者稍花时间看一下这篇文章就会发现,文章的核心内容其实是文中唯一的一幅插图,该图显示了万维网的出度和入度分布都服从幂律分布,从而具有无标度(Scale-Free)特征(图1)。
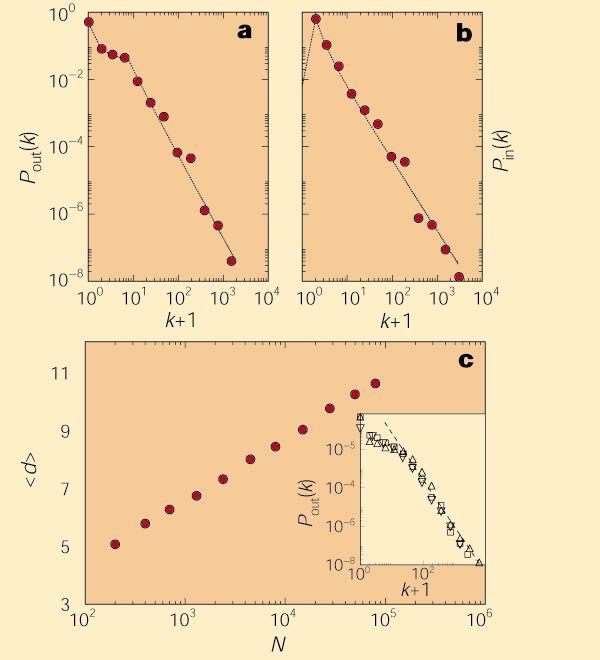
图1:万维网的度分布和平均距离(取自[1])
巴拉巴西自己也承认,取这样的标题是采用了特洛伊木马的策略以引起杂志编辑的兴趣,因为“无标度”在当时还并非一个人们觉得有意义的概念[2]。文章的最后一段指出,网络的无标度特征需要有超越传统随机图模型的新的建模机制。
这篇文章是巴拉巴西团队在网络科学领域打响的第一枪,而且也已经为他们的下一篇更具标志性的文章埋下了伏笔。
这里对幂律和无标度概念稍作解释:
所谓幂律度分布是指网络中一个节点的度为k的概率P(k)是一个幂函数,即P(k)=Ck^-⍺,其中⍺称为幂指数,度是指这个节点与其它节点相连的连边数。假如你的微信中有100个好友,你在微信好友网络中的度就是100。幂律的典型特征就是在双对数坐标系下为一条直线(如图1所示)。这条直线的斜率就是-⍺。
所谓网络的无标度特征是指网络中大部分节点的度值都相对较小,而少部分节点的度值相对很大,这就导致平均值不再具有典型意义。过去20年,人们发现许多实际的生物网络、技术网络和社会网络等都具有这样的特征。典型的例子包括经济网络中的少数巨头企业、航空网络中的少量枢纽节点、社交网络中的少量大V节点等等。
在这些年的网络科学研究中,往往把两者合二为一,即无标度网络就是具有幂律度分布的网络,这也是导致争议或歧义的一个因素。
一个月后,巴拉巴西和他的博士生阿尔伯特就在《Science》上发表了关于无标度网络模型的文章[3]。这篇文章被公认为是推动网络科学兴起的两篇标志性文章之一(另一篇是瓦茨和斯托加茨于1998年在《Nature》上发表的关于小世界网络模型的文章[4])。
巴拉巴西和阿尔伯特的这篇文章指出,包括万维网和电影演员合作网络在内的不同的实际网络,之所以都具有无标度特征,是基于两个很简单的机制:i)网络是不断增长的;ii)增长过程中服从偏好链接(Preferential Attachment),即新加入的节点倾向于与网络中度大的已有节点相连接。这一简洁的模型现在一般称为BA无标度网络模型,简称BA模型。
现在的问题是:在巴拉巴西之前,是否有人发现实际网络的度分布服从幂律?如果是的话,那么是否有人已经提出过产生幂律分布的优先链接机制?
近年来,科学文献引用关系网络在分析科学发展中的作用受到越来越多的关注[5,6]。2019年11月,《Nature》为纪念诞生150周年发行的特刊的封面就是一副在该杂志上发表的众多历史文章之间的关系网络图(图2)[7]。

图2:《Nature》出版150周年纪念刊的封面显示了论文共引关系网络(取自[7])
相关阅读:
因此,对上述两个问题答案搜寻的一个最直接的方法自然是去查看巴拉巴西团队的两篇论文[3][4]的参考文献。然而,我们从中并没有找到任何前人关于网络的幂律度分布和偏好链接机制相关的研究。
看来,巴拉巴西团队当时并没有注意到前人的相关工作,在巴拉巴西近年出版的网络科学著作[2]的一幅图中例举了历史上的一些代表性研究(图3)。本文关注的是图4所示的一些历史性研究节点之间的引用关系网络(其中A——>B表示B引用了A),以便读者更好理解幂律分布和无标度网络的研究历程,并通过这个例子更好理解科学的演化。
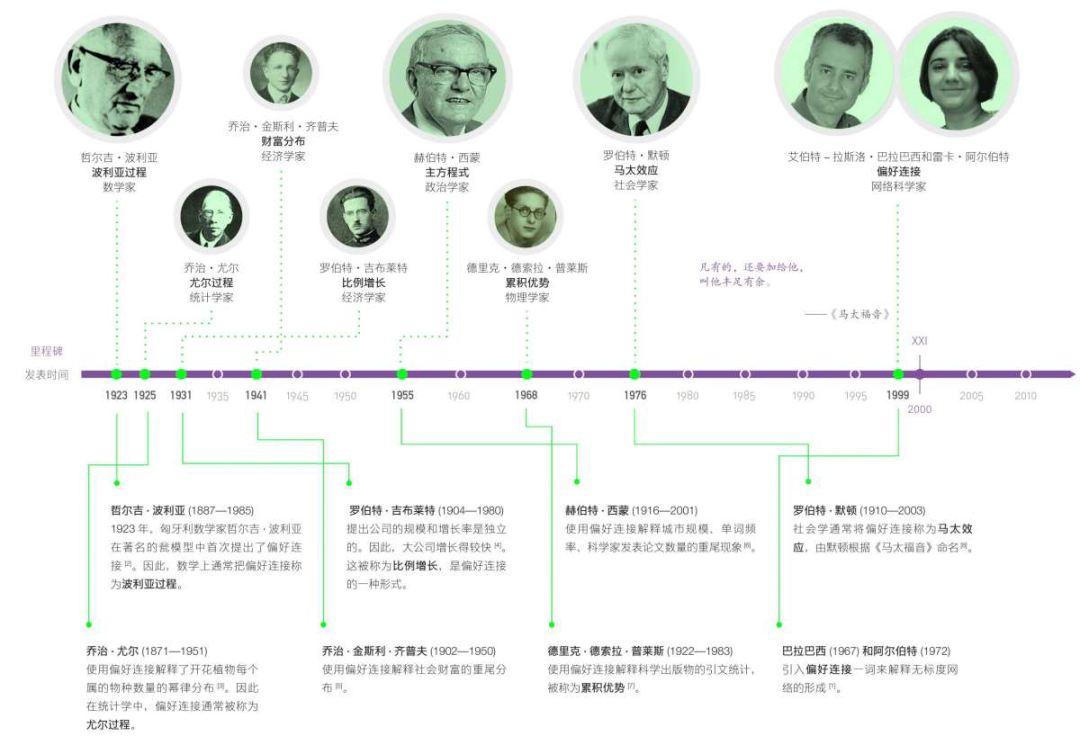
图3:偏好链接研究简史(取自[2])
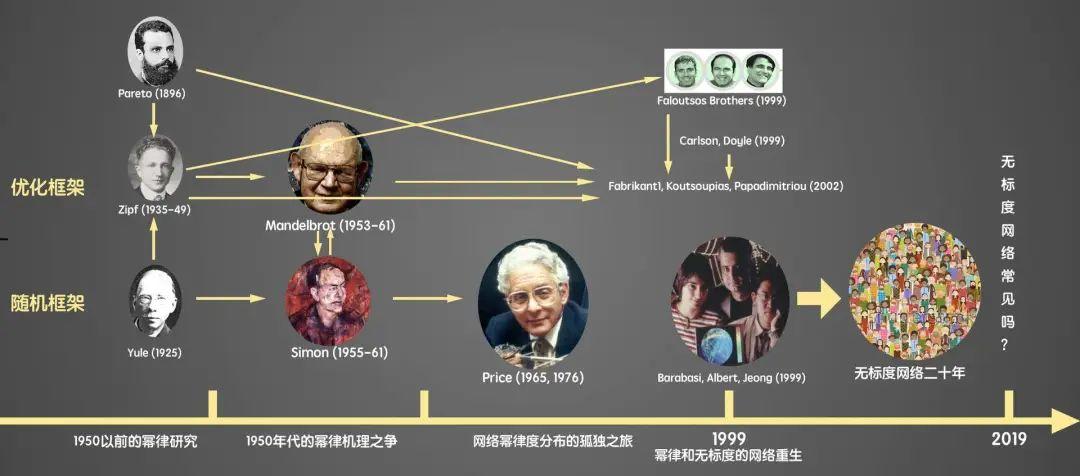
图4:幂律分布和无标度网络研究中一些历史性节点之间的引用关系网络
二、生成幂律分布的随机框架之路
一些读者也许对于科学计量学和普莱斯(Derek John de Solla Price)都不了解,但是大家应该都知道这些年炒的火热的期刊影响因子(Impact Factor),其发明人加菲尔德(Eugene Garfield)于1984年获得了首届普莱斯纪念奖,该奖是专门为了纪念于1983年去世的科学计量学的奠基人普莱斯而设立的。
在幂律研究征程上会遇到几位学术兴趣极为广泛的‘杂家’,普莱斯即为其中一位。普莱斯1941年从伦敦大学数学物理系本科毕业那年就发表了一篇关于横波解释的物理学论文;1942年即发表了属于科学学范畴的探讨科研未来的文章。他于1946年获得伦敦大学物理学博士学位,1954年又获得剑桥大学科学史博士学位,1962年起在耶鲁大学任教直至去世。
普莱斯曾于20世纪50年代与英国著名的科学史家李约瑟合作研究过中国的天文钟[8]。他于20世纪60年代初出版的《巴比伦以来的科学》[9]和《小科学,大科学》[10]两部著作被公认为是科学计量学的奠基之作。
普莱斯是1978年创办的《科学计量学》(Scientometrics)期刊的创刊主编之一,他在创刊词中感慨道:这不仅对科学计量学本身,而且对我本人,都开启了一个重要的历史新阶段。

图5:普莱斯和古希腊天文研究装置模型(图片来源网络)
加菲尔德曾在题为《献给普莱斯》的纪念文章中写道[11]:“我们的生命是有限的,如果在活着的时候继续研究这一领域(指科学计量学)的话,就不能不每天都要想起普莱斯给予的影响。因此,我们不必悲痛他的消逝。普莱斯是永生的。”
顺便剧透一下,在王大顺和巴拉巴西即将出版的《科学学》(Science of Science)著作[12]中会专门介绍普莱斯模型,彰显普莱斯的深远影响。
接下来我们就介绍一下普莱斯模型。
1965年,普莱斯在《Science》上发表了一篇题为“科学文献网络(Networks of Scientific Papers)”的文章[13],明确指出科学文献之间的引用构成一个有向网络,其出度和入度分布均服从幂律,并给出了相应的幂指数(图6)。请注意,当时普莱斯还没有使用双对数坐标系。
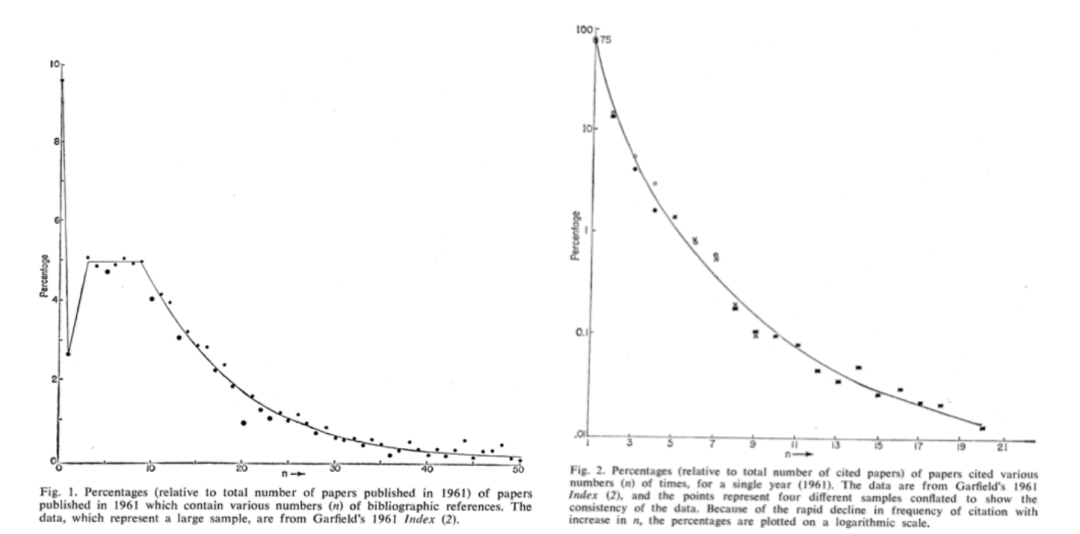
在此发现的基础上,普莱斯于1976年发表了一篇题为“文献计量和其它累积优势过程的通有理论(A General Theory of Bibliometric and Other Cumulative Advantage Processes)”的长文[14],摘要的第一句话就开宗明义的指出:本文提出了一个累积优势(Cumulative Advantage)分布,以从统计上建模成功孕育成功(success breeds success)的现象。
引言的第一段中也指出这一现象在文献计量和许多不同的社会现象中普遍存在。例如,被引用较多的文章相比于引用少的更容易获得新的引用;高产作者相比于低产作者更可能发表新作;常用的单词会更常使用,而少用的单词一直少用;富翁相比于乞丐能够更快更容易地获得财富等等。
今天看来,巴拉巴西的偏好链接机制与当年普莱斯关于累积优势的表述如出一辙。遗憾的是,普莱斯的这两篇文章成为了睡美人,而一直没有受到关注,直到2010年,纽曼(Mark Newman)在《Networks: An Introduction》这本网络科学教材里面才对普莱斯模型做了细致介绍[15]。
普莱斯对论文引用网络的增长和累积优势机制的观点可叙述如下:
上述普莱斯模型产生的有向网络的入度分布服从幂指数为2+a/m的幂律分布。如果把网络无向化,即每一条边都视为无向边,并且取a=m,那么就得到一个度分布服从幂指数为3的无向网络,这恰是BA无标度网络!
然而,普莱斯1965年的文章尽管是发表在顶级期刊《Science》上,并且普莱斯本人又是公认的科学计量学的奠基人,巴拉巴西团队在1999年的时候并未注意到普莱斯的相关工作。而且瓦茨和斯托加茨于1998年在《Nature》上发表关于小世界网络模型的文章时也同样没有注意到普莱斯的工作,否则他们稍许花点时间检验一下手上几个网络数据的度分布,也许网络科学过去二十年的发展又是另外一部历史了!
瓦茨在其著作《六度》(Six Degrees)中流露了深深的悔意[16]:“……我们犯了一个大的错误。我们没有检查!我们非常肯定的认为非正态分布是不可能的,因而从未想过要检查网络的度分布是否服从正态分布。数据在我们手上躺了近两年,我们只需花半个小时就能检查出结果,但我们就是一直没有做。”
B. 20世纪50年代:人工智能先驱西蒙登场
那么,普莱斯是从哪里得到的启发呢?从普莱斯的文章[14]中倒是不难发现这一点,在引言的第二段普莱斯就明确提出,在统计中这样的过程通常称为非对称的双曲函数,而这个函数的刻画者是赫伯特·亚历山大·西蒙(Herbert Alexander Simon)。
如果说对于普莱斯有些读者可能不知道的话,那么在如今的人工智能时代,西蒙作为一位人工智能先驱者无疑是大家都应该知道、并且值得膜拜的“前浪”。
前面提到普莱斯是一位‘杂家’,西蒙则更是如此了。西蒙在多个领域方面都取得了令绝大多数科学家望尘莫及的成就。作为一个政治学博士学位的持有者,西蒙在1975年获得计算机科学领域的最高奖——图灵奖,1978年获得诺贝尔经济学奖,1993年获美国心理学会的终身成就奖。这些跨界的荣誉“前不见古人,后不见来者”。西蒙还有一个中文名字叫“司马贺”,据说是他自己取的。
普莱斯的文章[14]引用的是西蒙在1955年发表的一篇题为“关于一类非对称分布函数(On a class of skew distribution)”的文章[17]。
西蒙在文中开门见山的指出,其目的就是要分析一类在社会、生物和经济等领域广泛存在的分布函数。这类分布的主要特征就是长尾,即尾部近似服从幂指数大于1的幂律分布,f(i)~ i^(p+1),p为一个大于零的常数。该文举证了五个具体数据:论著中的单词出现频次分布;科学家发表的文章数量分布;城市人口分布;收入多少分布;生物属的物种数量分布。
西蒙以写书为例给出了产生幂律分布的“偏好链接”假设。设想你正在写一本书并且已经写了k个单词,那么第k+1个单词是一个新单词的概率为a;第k+1个单词是一个已有单词的概率为1-a,并且一个已有单词被选中的概率与该单词已经出现的次数成正比。
基于西蒙模型,书中恰好出现i次的单词的数量的分布就会服从幂律分布。当然,西蒙模型中并未出现网络,因此普莱斯模型可以看作是西蒙模型的网络形式。
C. 20世纪20年代:统计学家尤尔的早期贡献
而正如西蒙在文中所指出的,西蒙模型可以追溯到20世纪20年代著名统计学家尤尔(George Udny Yule)的研究[18]。沿用今天的网络科学术语,尤尔试图解释达尔文的生命之树网络的无标度结构,即为什么生命之树上的某些分支要比其它分支扩张的快得多:大多数属(genus)只有一个物种,而大多数物种来自单个属。其解释即为偏好链接或者富者更富:一个属的物种越多,它就会产生更多的物种。
由于以上介绍的偏好链接机制是依照某个概率公式选取的机制,因此,增长和偏好链接机制也被称为产生幂律分布的随机框架。
上述对于随机框架中几个典型的历史性研究的介绍是不完整的,例如,出生于匈牙利的巴拉巴西就认为最先提出偏好链接的应该是匈牙利数学家波利亚(György Pólya)于1923年提出的URN模型[19]。相信有更多学者的贡献还没有被挖掘出来,也许有一天人工智能算法能够帮助解决科研工作中的睡美人现象[12]。
现在我们知道的是,其实可以有很多种产生幂律分布的方法[20],接下来要介绍的是其中的一类优化框架。
三、生成幂律分布的优化框架之路
在科学研究进程中,由于知识的积累和技术的进步等演化到了一定的阶段,不同的科学家往往在相近的时间开始研究相似的问题。1999年对于幂律分布及其产生机理而言就是这样一个年份,除了巴拉巴西团队的研究,至少还有如下两个值得一提的代表性工作。
在1999年的网络通信领域国际顶级会议ACM SIGCOMM上,计算机科学家法拉特三兄弟(Michalis Faloutsos、Petros Faloutsos和Christos Faloutsos)发表了一篇题为“关于互联网拓扑的幂律关系(On Power-Law Relationships of the Internet Topology)”的文章[21],推动了互联网拓扑发生器从1.0进入2.0时代。该文也获得了2010年ACM SIGCOMM的“经受时间检验奖(test of time award)”。
同样是在1999年,物理学家卡尔森(J. M. Carlson)和控制学者道尔(John Doyle)在物理学期刊上提出了设计系统中的幂律产生机制——高度优化容忍(Highly Optimized Tolerance),用以表征一些复杂互连系统可以有效地容忍某些不确定因素(即鲁棒性),也会对其它未被考虑到的不确定因素变得更敏感(即脆弱性)[22]。
2002年,理论计算机科学家克里斯特斯· 帕帕季米特里乌(Christos Papadimitriou)团队在上述两项研究的基础上,提出了互联网中幂律产生的一种优化框架:启发式优化折衷(Heuristically Optimized Trade-Offs),发表在International Colloquium on Automata, Languages and Programming上[23]。
以计算机网络为例,假如要把某地的一台路由器加入网络中,既希望离中心节点尽可能近,又希望铺设的线路成本尽可能低,如果我们同时考虑这两个因素的某种折衷,就会生成无标度特征的计算机网络。幂律分布正是来源于复杂的多目标优化。
B. 20世纪50年代:分形之父曼德布罗特登场
幂律产生的优化框架可以追溯到什么时候?文献[23]中指出“我们所提出的概念框架也包含了曼德布罗特(Mandlebrot)的经典而漂亮的模型。”
这里所指的是曼德布罗特于1953年发表的一篇题为“语言统计结构的信息论(An informational theory of the statistical structure of language)”的文章[24]。
经典的香农信息论问题研究的是对消息构造最小代价编码,而曼德布罗特指出语言的统计结构问题事实上是这一经典问题的逆问题,即用尽可能少的成本传递尽可能多的信息。这种目标优化会导致第j个使用最多的单词出现的频率服从幂律分布。
分形之父曼德布罗特与人工智能先驱西蒙一样也是一位杂家,他的研究范围极其广泛,从物理、天文、地理到经济学、生理学等。然而,他的前半生的学术生涯却较为坎坷,得不到学界的认可,直到1975年创建令人叹为观止的分形几何。
畅销书《黑天鹅》的作者纳西姆·尼古拉斯·塔勒布(Nassim Nicholas Taleb)曾与曼德布罗特有过合作研究,他于曼德布罗特去世后在自己的个人网站称其为“罗马人中的希腊人(A Greek among Romans)”。了解古希腊科学辉煌的读者应该知道,这是一个至高评价。
那么曼德布罗特又是继承了谁的想法呢?曼德布罗特在文[24]中提到了语言学家齐普夫(George Kingsley Zipf)20世纪30年代的工作。齐普夫发现,如果把英语单词的出现频率由大到小排序排列,那么每个单词出现的频率与它的排序位置之间的关系就服从幂指数为1的幂律分布,后人称之为齐普夫分布。
这一发现表明只有极少数的词被经常使用,而绝大多数的词很少被使用。而且多种语言都具有这一特征,它使得人们可以用尽可能少的单词表达尽可能多的语义。
齐普夫称之为“最小努力原则”,并于1949年出版专著《人类行为与最小努力原则:人类生态学引论》(Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology)对齐普夫分布做了更为广泛的介绍[25]。
此后,齐普夫分布被用于从社会到自然和物理等不同的系统。例如,城市人口按规模的分布服从齐普夫分布:大多数城市的规模相对较小,而少量城市的规模相对很大。这一规律甚至被迈克尔·巴蒂在《创造未来城市》一书中称为是城市发展的第一原则[26]。
诺贝尔经济学奖得主保罗·克鲁格曼(Paul R. Krugman)于1996年发表了一篇题为“直面城区层级化的奥秘(Confronting the Mystery of Urban Hierarchy)”文章[27],文中即以城市规模分布这一惊人简单的经验规则为例说明: “人们对于经济理论的常见抱怨就是觉得我们的模型过于简单、过份简洁的看待杂乱的现实……在另一类重要的情形下,事实可能恰恰相反:我们拥有杂乱的模型,而现实却是惊人的简洁。”
从齐普夫再往前追溯,就会遇到19世纪末意大利经济学家帕累托(Pareto)关于个人财富的经典研究[28]。帕累托发现个人收入X不小于某个特定值x的概率是x的幂函数,20%的人口占据了80%的财富。这一发现被后人称为帕累托法则(也称二八法则,80/20法则),而关于这一法则近年来有很多的介绍,这里就不再展开了。
四、西蒙与曼德布罗特的七轮大战
上面的介绍中已经提到,20世纪50年代的时候,人工智能先驱西蒙和分形之父曼德布罗特分别研究了幂律产生的随机框架和优化框架。这里我们要介绍的是两人在当时围绕幂律产生机理的一番论战。
1955年,西蒙39岁、曼德布罗特31岁,两人都是血气方刚之年,西蒙已在学界颇具名气而曼德布罗特则初出茅庐、尚未得到学界认可。由于观察角度、思维方式和处理方法等的不同,科学研究上的争论也是常见的。不过这两位极富个性的科学家围绕幂律的七轮大战却是堪称一绝。
西蒙于1955年发表的关于幂律产生的随机框架文章[17]引用了曼德布罗特1953年发表的优化框架文章[24],并且指出:“我倾向于给出一个利用平均而不是极大化假设的解释。”
尽管西蒙在文中的致谢部分对曼德布罗特表示了谢意,然而曼德布罗特并不领情,写了一篇批评西蒙的评论文章于1959年4月发表在《Information and Control》上,简称”A Note”[29]。文中指出:“西蒙提出的反驳我们的语言学法则理论的两个论点都站不住脚。”由此开启争吵之旅。
西蒙在其自传中专门有一章的标题即为“论战”,其中回忆了他和曼德布罗特的争论[30],而曼德布罗特的自传却对此争议只字未提[31]。
1960年,西蒙发现了曼德布罗特那篇批评他的注记,但是他说无论是作者还是期刊编辑部都没有告知他。于是西蒙写信给曼德布罗特,提议联合写篇文章阐明双方的异同点。两人起初都同意并交换了一些草稿。但是两人很快发现他们的争论在逐步升级,因此互相拉黑放弃了合写文章的打算。
西蒙单独写了一篇针对曼德布罗特的评论的回复文章,简称”Some Further Notes”[32]。该文于1959年7月即投稿到《Information and Control》,并于1960年3月正式发表。文中开宗明义指出曼德布罗特对他的模型的批评是不成立的。
针对西蒙的答复曼德布罗特又另写了一篇答复文章,简称”Final Note”[33]。既然是最后的注记,争论似乎到此就结束了。然而,编辑把这篇回复文章在发表前寄给了西蒙,西蒙显然也不愿意就此打住,于是针对性的又写了一篇”Reply to ‘Final Note'”[34]。这两篇文章于是就在《Information and Control》的同一期上同时发表出来。
曼德布罗特心想,我已经说是最后的注记了,你还不依不挠,难道怕了你不成,他就又写了一篇评论”Post Scriptum to ‘Final Note'”[35],而且,摘要只是一句话:“我的批评从1955年看到西蒙文章的初稿以来一直没变。”
对曼德布罗特的这个答复,西蒙也没忍住,又写了一篇答复”Reply to Post Scriptum”[36],摘要也很简单:“曼德布罗特对我1955年提出的模型提出了一组新的反驳理由,然而如同他先前的反驳一样,这些反驳同样是无效的。”
至此,两人的争论又重新回到原点,夹缝中的编辑中止了这场争论,而这场持续数年的论战也总算谢幕。

“我的梨比你的苹果甜”
“事实证明我的苹果比你的梨甜”
“明明我的梨更甜”
“明明我的苹果更甜”
“我坚持我的梨更甜”
“我坚持我的苹果更甜”
编辑:好了好了,你们的梨和苹果不要在我这里摆摊了,大家都散了吧。
围观群众:有什么好吵的呢,梨有梨的好处,解渴生津,苹果有苹果的好处,维生素含量高,各来一斤。
如今,我们知道复杂网络种也存在分形和自相似特征,而人工智能算法也在复杂网络分析中日益重要,不知人工智能先驱西蒙和分形之父曼德布罗特得知的话会有何感想。
五、偏好链接:随机还是优化?
目前为止,我们是把幂律产生的随机框架与偏好链接机制相对应的,即度大(也可以称为名气大)的节点获得新链接的概率也大。2012年,帕帕多普洛斯(Papadopoulos)等人的一篇《Nature》文章则给出了偏好链接机制的一种优化框架[39]。
在社会学中有一条基本的同质性原理:越是相似的人越有可能在一起。帕帕多普洛斯等人指出,如果新节点通过优化名气和相似性之间的某个折衷函数而选择添加链接的话,那么同样可以产生偏好链接。
巴拉巴西在同期《Nature》上发了一篇题为“运气还是推理(Luck or reason)”的评论指出[40],当年西蒙和曼德布罗特事围绕幂律产生的随机和优化框架而争论,如今则升华为偏好链接机制形成的随机和优化框架之争。巴拉巴西进一步指出,大多数复杂系统中应该二者兼而有之,因此我们没有必要只能二选一。不管怎样,起作用的是偏好链接机制。
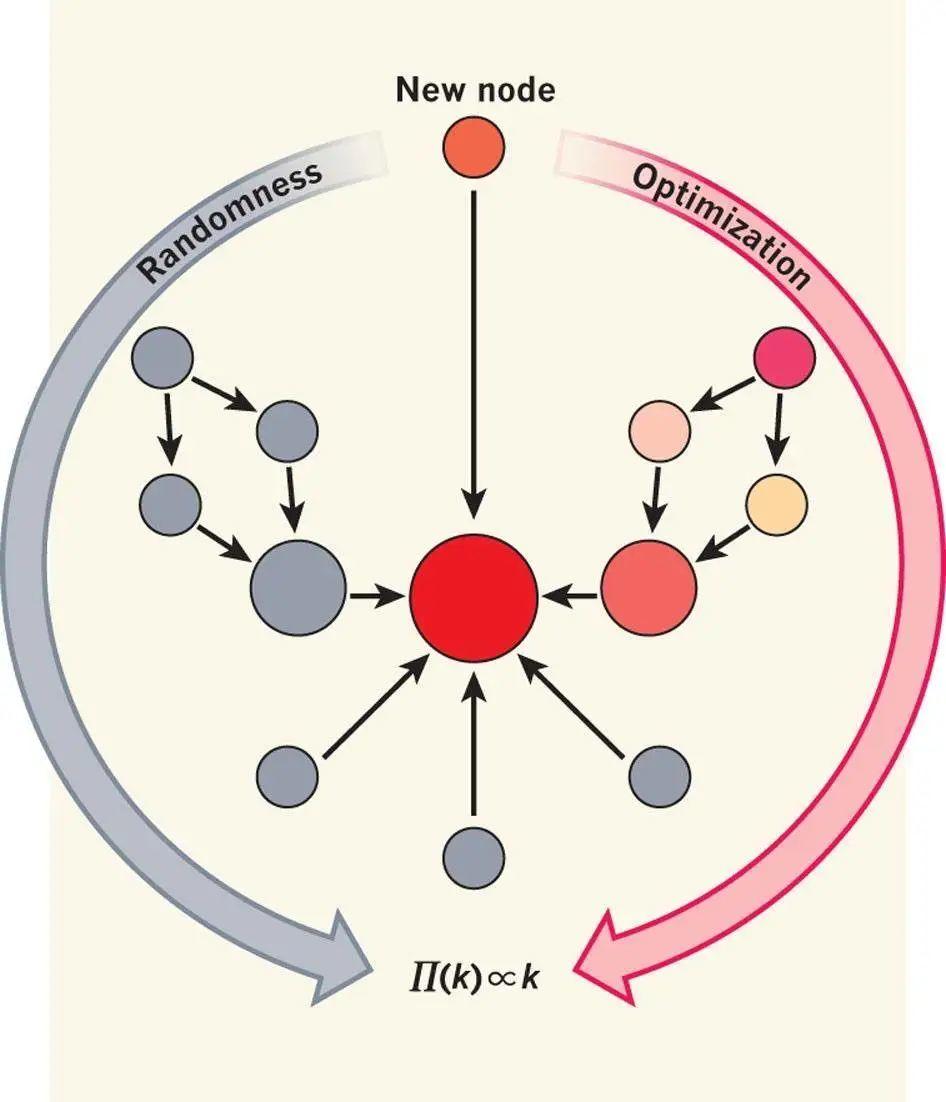
图 8:偏好链接机制的随机和优化模型(取自[40])
六、无标度网络“危机”
A. 克洛赛的“魔戒”引发的危机
2009年,当时在美国圣塔菲研究所从事博士后研究的安然·克洛赛(Aaron Clauset)等人花了4年时间写作的长篇论文“经验数据中的幂律分布(Power-law distributions in empirical data)”终于在国际应用数学顶级期刊《SIAM Review》上发表[41]。
克洛赛认为他们的这篇文章完整解决了幂律分布的检验问题,并在博客文章中把它类比于万能的“魔戒”。文中给出的检验数据是否符合幂律分布的流程如下:
1)使用极大似然方法估计幂律模型参数;
2)计算数据和幂律之间的拟合优度,以判定幂律是否为合理假设;
3)通过似然比检验比较幂律假设和其它分布假设 ,以判断更倾向于哪个假设。
2018年1月,已经到美国科罗拉多大学任教的克洛赛和他的博士生安娜 ·布罗迪(Anna Brodio )在arXiv上贴出了一篇标题为“无标度网络很少见(Scale-free networks are rare)”的文章[42],文中使用上述幂律检验方法,通过对上千个实际网络数据集的研究发现,其中只有15%的网络,通过了无标度网络的强检验,而43%的网络根本就不能算作无标度网络。
无标度网络毕竟是网络科学中的核心概念,这一研究立即引发圈内学者的关注。
2018年2月,著名科普网站《Quanta Magazine》上发表了一篇题为“实际网络中缺乏幂律证据(Scant Evidence of Power Laws Found in Real-World Networks)”的评论文章[43],介绍了一些圈内学者的看法。
大部分学者觉得这一研究还是有意义的,但是巴拉巴西用一个比喻来反驳克洛赛的工作,“你不能因为现实中一片羽毛和一块石头落下的速度不同,就否定万有引力定律(万有引力定律告诉你自由落体的速度就应该一样),在现实中总是会受到其他因素的干扰,比如空气阻力。”
克洛赛显然不同意这种说法,他说,“如果有1000种物体自由落体,你总能在大部分物体中观察到重力和空气阻力如何共同作用于物体的普遍规律,所谓的干扰因素问题就可以迎刃而解。”
2018年3月,巴拉巴西在其实验室主页上贴出了一篇反驳文章,题为“你所需要的只是爱——克洛赛对无标度网络的无效搜索(Love is All You Need——Clauset’s fruitless search for scale-free networks)”[44]。
Love is All You Need | 无标度网络理论之父Barabási回应史上最严重质疑
在克洛赛的研究中,对于一个两层的有向网络,是要把它分成两个单独的有向网络,然后对每个有向网络分别计算出度分布、入度分布和视为无向网络的度分布。只有6个度分布中的5个都服从幂律,那么才认为原始的两层有向网络是无标度网络。
巴拉巴西举例说,这相当于把单词 Love 拆分为如下元素:
{L, o, v, e, Lo, Lv, Le, ov, oe, ve, Lov, Loe, ove, Love}
克洛赛要求其中每个元素都要包含Love,Love才是Love。
因此,巴拉巴西认为,在克洛赛的眼中,There is no Love in Love,而在我们其他人眼中,Love is all you need。
但是,巴拉巴西的这一指责本身也是值得商榷的,因为在克洛赛的文章中也已经指出了,即使对于187个简单网络数据集(每个网络不再有任何拆分),也只有20%的网络可以通过无标度网络的强检验,44%的网络根本不能算作无标度网络。
值得一提的是,克洛赛团队建立了至今为止复杂网络领域的最完整的数据集,包含了好几千个实际网络的数据信息,这也是对网络科学研究的贡献。当然这一数据集还需要改进。数据和算法一样重要,正如imagenet改变了人工智能领域一样,大规模、高质量的复杂网络数据库有助于推动网络科学更上层楼。
B. “神人”克里科夫的辩护
2018年7月,克洛赛在第4届国际计算社会科学年度会议报告了他们关于无标度网络很少见的工作。
2018年11月,巴拉巴西领衔的美国东北大学网络科学研究所的DK-Lab实验室主任迪米特里·克里科夫(Dmitri Krioukov)团队在arXiv上贴出了一篇题为“无标度网络没问题(Scale-free Networks Well Done)”的文章,认为无标度网络显然绝非克洛赛他们所指出的那么少[45]。
克里科夫也算得上是一位科学界的“神人”。2012年的时候,克里科夫还在美国加州大学圣迭戈分校(University of California, San Diego)从事研究工作。一个春日,他驾驶着一辆丰田雅力士在上班途中被警察发现没有在停车标记Stop sign前停车,因而收到400美元的罚单。但是克里科夫没有自认倒霉,而是选择了上法庭申诉。
克里科夫的辩护理由是,当时他经过的道路有两条车道,在他的车身较短的丰田雅力士和警察中间还有另外一辆车身较长的车在通行,两辆车几乎同时从停车标记S的地方通过。他以一篇4页纸的物理论文从理论上向法庭证明,在这种环境下,由于另一辆车的遮挡,完全存在自己停了但警察没看到,而被误认为没有停的可能。
克里科夫居然成功胜诉了,而且他的这篇题为“无辜的证明(The Proof of Innocence)”的论文至今还放在arXiv网站上[46]。当然,后来也有人指出,克里科夫的论证中还是存在瑕疵的,感兴趣的读者可以自行验证。
接下来我们就看看克里科夫团队是如何为无标度网络辩护的,他们做了三件事:
首先,也是最核心的,他们认为要重新给出幂律分布的严格定义。克洛赛团队基于的是幂律分布的理想化的定义,即当k>=kmin时,网络中一个随机选取的节点的度为k的概率服从:
P(k)=c k^-r
其中c为归一化常数,r为幂指数。克里科夫团队指出,实际网络的演化过程多样且存在各种噪声和扰动。因此,要求实际网络的度分布服从这一理想化的幂律,就相当于要求在有摩擦力的地面上的运动要完全符合无摩擦力情形的理想化的牛顿运动定律一样。为此,他们提出幂律分布的一个更为实际的定义应该是正规变化分布(Regularly Varying Distribution),其对应的概率密度函数为:
P(k)=l(k) k^-r
其中I(k)是一个当k趋于无穷大时缓慢变化的函数(数学上,正规变化分布是通过与上式对应的互补累积分布定义)。正规变化分布包含了理想化的幂律分布,并且当k趋于无穷大时两者是一致的。但是,在有限k值的情形两者可以有很大差异。
其次,克里科夫团队给出了估计正规变化分布的指数的三种具有相容性的方法。他们还强调了采用多种相容性估计方法的重要性,因为不同的估计方法可能只是揭示分布的不同的部分。
最后,他们对115个实际网络数据进行了验证。发现无标度网络的比例要显著高于克洛赛团队的判断。这一结论其实也是自然的,因为克里科夫团队毕竟明显放松了对于幂律分布的要求。
2019年3月,“无标度网络很少见”这篇文章正式在《自然通讯》(Nature Communications)上发表[42]。该刊同时配发了一篇由网络科学学者郝培德(Petter Holme) 撰写的评论“既少见又处处可见:关于无标度网络的观点”(Rare and everywhere: Perspectives on scale-free networks)[47]。
评论认为两种看似截然不同的观点还是有可能调和的。克洛赛研究的是规模有限的实际网络,而克里科夫团队研究的是当网络持续增长趋于无限的情形。此外,绝大多数网络科学学者都认为“知道某个分布是否为长尾要比知道它是否符合幂律重要得多。”
同样是在2019年3月,克里科夫团队成员在国际网络科学会议 COMPLENET 上介绍了他们关于“无标度网络没问题”的工作。
2019年4月,克劳赛的博士生布罗迪以“无标度网络很少见”作为论文核心内容通过了博士学位论文答辩。
2019年10月,“无标度网络没问题”这篇文章在新创办的开源期刊《Phys. Rev. Research》上发表[45]。至此,这一争议以双方成果都正式发表而暂时告一段落。
七、结束语
1)即然围绕幂律度分布是否常见及其产生机理存在这么多的争议,那么如何看待无标度网络的研究?
首先,过去二十年的经验研究至少形成了如下共识:许多(甚至是绝大多数)大规模实际复杂网络的度分布都具有长尾特征,即少量节点的度值相对很大。换句话说,如果无标度网络定义为度分布具有长尾特征的网络,那么无标度网络确实是很常见的。
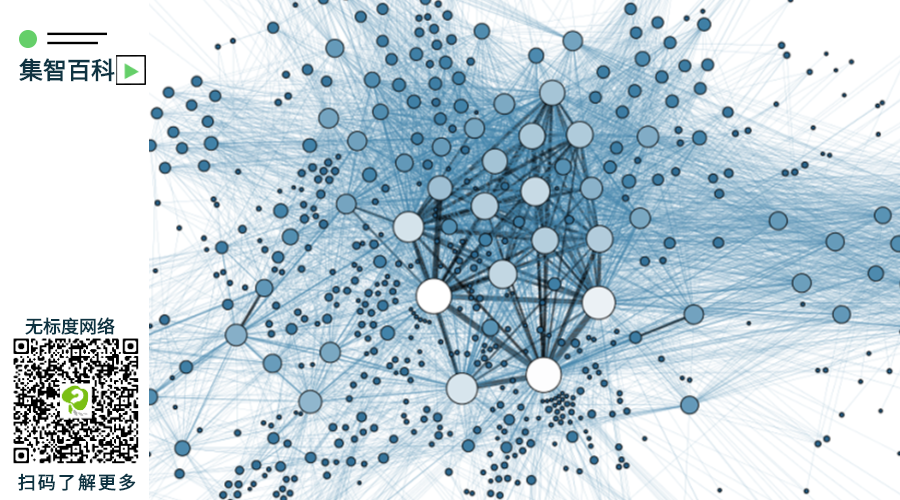
图9:典型的无标度网络,只有少量大度节点,节点度分布服从幂律。扫码可阅读集智百科“无标度网络”词条,了解更多信息
其次,如果把无标度网络定义为度分布服从幂律的网络,那么无标度网络在实际中是否常见确实值得进一步严肃探讨。毕竟,过去二十年很多关于实际网络的无标度特征的发现确实是不严谨的。很多的研究都是不管三七二十一,看到长尾就认为是幂律,在双对数坐标系下简单的直线拟合,而不管误差有多大。更为一般地,许多关于幂律的发现也缺乏统计上的支撑[48]。
第三,如果要求实际网络度分布服从理想幂律分布确实也不合理。所以问题又归结为如何刻画实际网络度分布是否符合幂律。
进一步地,如果幂律并非实际网络度分布的通有特征的话,那么偏好链接机制是否常见也值得探讨,仅仅只是研究幂律的产生机理也显偏颇。爱因斯坦有句名言:越简单越好,但不要过于简单。
综上,我们建议在实际网络分析中粗看长尾、细辩幂律。一方面,如果网络的度分布确实明显不均匀,存在少量度值相对很大(例如,度值差别在2个数量级以上),那么可以认为该度分布具有长尾特征;另一方面,要判断这一长尾是否符合幂律则需要谨慎。为达成共识,所有关于实际网络度分布是否服从幂律的检验应该要按照统一的标准来做,以有利于网络科学更为严谨、避免歧义和不必要的争议,也更好应用于实际。
幂律分布是否依然在实际网络度分布研究中具有统治地位?更进一步,考虑到两个具有相同度分布的网络也可以具有非常不同的其它特征,度分布本身是否依然在网络科学研究中属于核心概念?让我们共同期待下一个二十年。
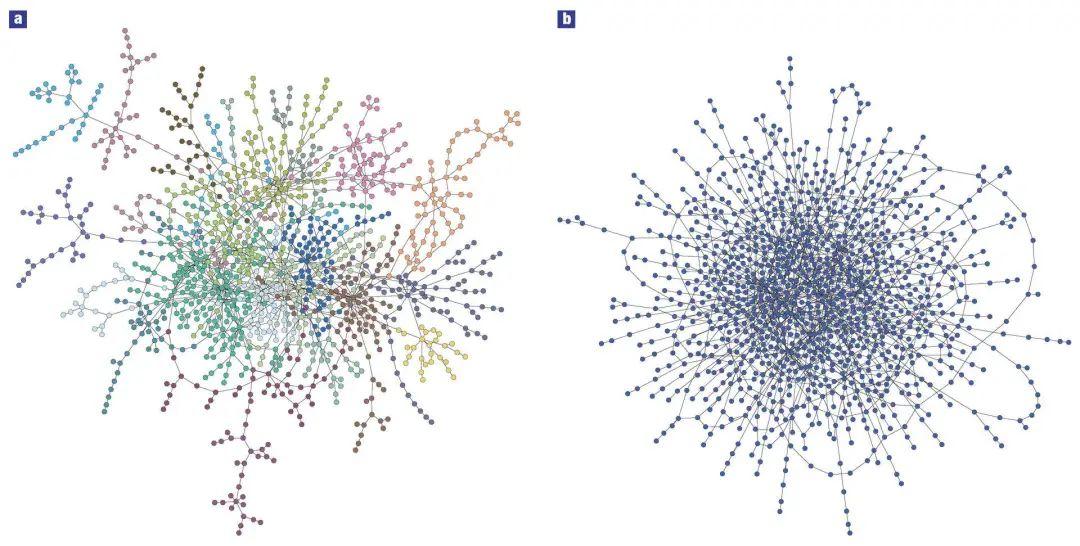
图10:两个具有完全相同度分布的网络(取自[49])
我们可以看一下关于混沌研究的经典案例。1975年,当时在美国马里兰大学读博的李天岩和导师约克在《美国数学月刊》上发表了一篇“周期三则意味着混沌”的文章[50],后来发现这篇文章中的主要定理事实上是前苏联学者萨可夫斯基(Sharkovsky)于1964年发表在俄文期刊《乌克兰数学杂志》上的一个结果的特例[51]。
这样看来,李-约克的工作似乎毫无意义了,但是至少从如下两个方面来看,也许李-约克的工作更有价值:首先,李-约克在关于周期三的结果的基础上首次明确提出了“混沌”的数学概念与定义,揭示了混沌系统关于初始条件的极端敏感性以及由此产生的解的最终性态的不可预测性,从而成为了推动混沌理论研究兴起的奠基性工作;其次,也正是由于李-约克的工作才唤醒了人们对萨可夫斯基的工作的注意。
换句话说,如果没有类似于李-约克的工作,那么萨可夫斯基的工作也许就会依然冷冻在历史长河中等着被唤醒。这个历史上的例子也许有助于我们理解巴拉巴西关于无标度网络的研究对于网络科学的意义,而普莱斯和萨可夫斯基则分别是网络科学和混沌研究中的“睡美人”。
类似的例子其实还可列举很多,从统计物理中的平均场理论到神经网络中的反向传播算法的发明等。诺贝尔奖得主朱棣文在哈佛大学毕业典礼的演讲中曾说到:“在科学中,第一个发现者是重要的,但在得到公认前,最后一个将这个发现重复出来的人也许更重要。”
最后,关于前面介绍的那些争议还想再说几句。科学研究中存在争议实在是太正常不过了,质疑精神本身就是科学精神的核心之一。因此,如果争议的各方都是本着理性求真的精神阐述各自的观点,那么这种争议就有助于科学的发展。理性求真的科学精神在当下更是具有特殊重要的意义。
巴拉巴西的那篇回应文章的标题“你所需要的只是爱”应该对大家都适用,正如同王力宏的一首歌的歌名“爱你就等于爱自己”。
作者讲座:
从无标度网络研究历史看想法传播
兴起于世纪之交的网络科学在过去二十年间取得了重要进展。其中,无标度网络的研究处于中心地位,包括无标度网络的普适性、拓扑模型及其对传播动力学等的影响等等。本讲座将从发现、建模和分析几个方面梳理无标度网络的研究历史,包括对于存在的争议的分析,最后给出对网络科学未来发展的一些看法。

(参考文献可上下滑动)
作者:汪小帆、张倩
审校:张江、陈清华、黄俊铭、刘培源
编辑:张希妍


推荐阅读

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”

让苹果砸得更猛烈些吧!
👇点击“阅读原文”,了解更多论文信息
微信扫一扫,分享到朋友圈











