因果科学怎样改变人工智能和现实世界? | BDSC2020因果推断分会场回顾

导语
8月22日的全国大数据与社会计算会议中,集智俱乐部组织了因果推理专题会议,邀请清华大学、北京师范大学、麻省理工大学(MIT)以及业界学者,分享他们在因果科学领域的研究进展。四位讲者分别从因果推理在人工智能中的必要性、在复杂系统建模的主要方法、以及在互联网平台和产品上的应用等几个层面进行了讲解。本文是对因果推理专题会议上几位专家讲座的总结。
整个会议的部分讲座视频已经剪辑出炉,免费提供给需要的读者,包含讲者授权我们发布的PPT。请扫下方二维码获取。
自9月20日(周日)开始,集智俱乐部还将举行一系列有关因果推理的读书会,欢迎更多的有兴趣的同学和相关研究者参加,一起迎接因果科学的新时代。系列读书会详情与参与方式见文末。

扫码查看大会录播,包含因果推断分会场
因果科学是研究因果关系和回答因果问题的学科,因果革命和数据科学革命的不同之处在于它是以科学为中心,涉及从数据到政策、可解释性、机制的泛化,再到一些社会科学中的基础概念,例如:信用、责备和公平性等,甚至哲学中的创造性和自由意志等概念。因果革命正在改变整个数据科学,帮助解决混杂偏差,选择偏差和测量偏差等问题。AI中的开放性难题,例如从一个问题的另一个问题的泛化能力,本质都和因果密切相关。让机器学会因果推理的是实现真正人工智能一个重要步骤,当前有很多最优秀的科学家在朝着这个方向努力。
崔鹏:大数据环境下的因果推理是 AI 发展的必然

崔鹏,清华大学计算机系长聘副教授。研究兴趣包括大数据环境下的因果推理与稳定预测、网络表征学习、社会动力学建模,及其在金融科技、智慧医疗及社交网络等场景中的应用。
首先,来自清华大学计算机系长聘副教授崔鹏做了题为《人工智能:从“知其然”到“知其所以然”》的学术报告。
近些年来,人工智能技术在大数据和算力提升的加持下,在诸多领域都取得了突破性进展,例如人脸识别、棋类游戏、社交和购物网站的推荐系统等等。然而究其实质,却只是一个不知其所以然的黑箱过程。
这样的智能系统存在诸多系统瓶颈:
- 缺乏“举一反三”的能力,在一个环境或场景中学习的模型难以泛化到其他环境和场景;
- 推理结果和推理过程难以解释,限制了人工智能技术在智慧医疗、金融科技等风险敏感领域的应用。
 这样的智能系统是互联网思维下“性能驱动”的产物,需要不断的投入数据和算力才能进行提升。但即使如此,在互联网之外的诸多垂直领域,如智慧医疗、金融、自动驾驶等这些风险极为敏感领域,传统数据方法也无法满足应用的安全性需求。
这样的智能系统是互联网思维下“性能驱动”的产物,需要不断的投入数据和算力才能进行提升。但即使如此,在互联网之外的诸多垂直领域,如智慧医疗、金融、自动驾驶等这些风险极为敏感领域,传统数据方法也无法满足应用的安全性需求。
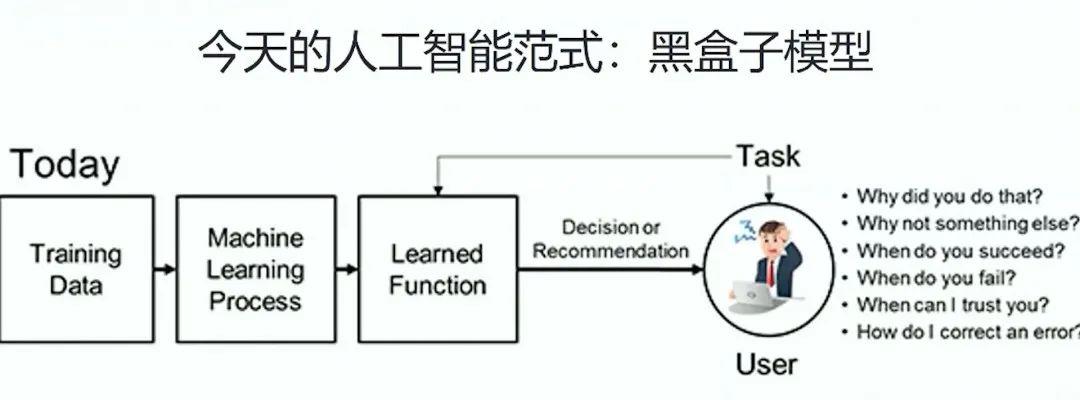
那么如何解决这个问题?崔鹏副教授认为,这就需要在大数据环境中引入因果推理能力,从解决 “What problem” 到“ Why problem”,让工智能技术从“知其然”到“知其所以然”。这也意味着人工智能从性能驱动转到风险敏感驱动,去着力解决有关人类安全和健康的问题。
对后者,一方面是模型的可解释性问题,一方面是将因果推理引入预测性问题,以及在稳定预测模型方面的研究。
相关关系本身就是不可解释的,不可解释就意味着人和机器之间人机不能协同。也就是说智能系统,尤其是在复杂任务性能是不可能达到非常可靠非常高精准的程度的。这样在包括医疗、军事、金融、工业高风险领域人类就不可能去信赖机器去做决策。

此外就是 AI 系统的不稳定性。这源于人工智能模型的一个基本假设,即独立同分布假设。它要求训练数据和测试数据最终数据分布应该是相似的。
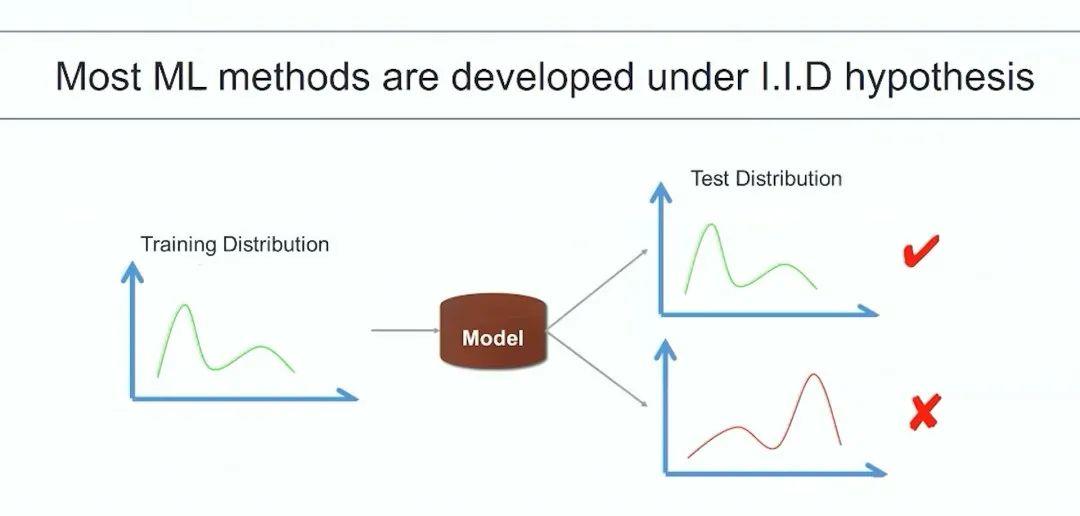
但问题是,在真实应用场景中,例如自动驾驶的路况和训练数据可能有很大的偏差,因为你不能真正控制司机去什么地方。这就导致机器学习模型数据分布会有一个系统性偏差,只能抓到数据中表面上一些虚假关联,并没有理解真正理解概念以及这些属性间的因果关系,因此不管是从性能还是理论上来讲,这个模型的性能是可以任意的差。这个问题甚至在图像识别中也是重大缺陷,人脑可以辨认在任何情况下的一只狗,但对机器来说总可能塑造这样的数据让 AI 无法进行正确识别分类。

要解决这种预测的不稳定性,即不管环境怎么变,狗在天上去依然还是一只狗,能够做到举一反三,就需要机器学习到因果关系。知其然,更知其所以然。这里崔鹏老师讲了一种自己常常使用的稳定学习的方法。
通常机器学习就相当于在一个分布(distribution 1 )上训练一个独立同分布(IID)的模型,去优化的目标旁边 accuracy 1。那么如果再训练多个分布和优化目标的模型呢?如图所示,显然 从 distribution x 去优化 accuracy y,那就是迁移学习(Transfer Learning),在一定程度上能解决预测不稳定问题,但它依然是一种理想化假设情况,因为他要求知道实际应用场景下真实测试数据的真实分布。 
这样基于大数据的因果推理,不仅能因为可解释性让人类参与协作、解决要求更高的安全问题,还将成为从定向推理到通用推理的重要理论基础。
而稳定学习(Stable learning)则是结合上面不同的分布(distribution 1~n),去优化不同的数据环境。至于优化目标,则设置为 accuracy 的方差。这就意味着,在以上环境下训练出来的模型,能够保证它在所有的可能应用的环境下,它的 accuracy 性能都不会太差,即抖动不会太大。因此这就在一定程度上解决了机器学习的不稳定性问题,使得模型结果更具有因果效应。
当然,上面只是基于大数据因果推理思维很简单的一个应用。因果推理对这方面问题的解决方法多种多样,后面张江老师会讲到更多途径。
崔鹏老师认为,基于大数据的人工智能有了因果推理,不仅能因为可解释性让人类参与协作、解决要求更高的安全问题,还将成为从定向推理到通用推理的重要理论基础,甚至实现人类梦寐以求的通用人工智能(AGI)梦想。
张江:复杂系统自动建模与因果发现的几种方法

张江,北京师范大学系统科学学院教授、集智俱乐部创始人、集智学园创始人。主要研究领域包括复杂网络与机器学习、复杂系统分析与建模、计算社会科学等。
复杂系统如今已无处不在,对其建模工作也取得了很多进展。尤其在人工智能、深度学习的助力下,复杂系统建模已经步入了自动化的阶段。例如根据复杂系统的运行数据(时间序列),深度学习系统即可以模拟系统的运行、预测系统的未来状态。
但是,这些系统建模方面的进展,就如前面崔鹏教授所说,大多数还基于大数据之间的相关关系,缺乏可解释性和泛化能力。因此结合因果推断技术自动从数据中提炼出因果关系,并具备一定可解释性能力的深度学习模型逐渐被提出来。目前这两大方向的发展正在逐渐呈现新的交叉、合并之势。尤其通过引入图结构学习技术,深度学习算法不仅可以精准地预测系统动力学,还能够自动提炼因果结构,甚至能够与系统进行互动和干预。
张江老师在讲座中,就结合自己研究小组的工作,从宏观的视角对这些技术进行了概述:不仅包括基于经典机器学习的因果建模、图神经网络自动建模,还包括融合神经网络的格兰杰因果检验、以及动力学网络重构学习和因果发现方面的工作。内容上他从技术角度将因果自动建模的研究分为四类分别进行讲述,这也是一个模型结合因果推理能力不断深入的阶梯。
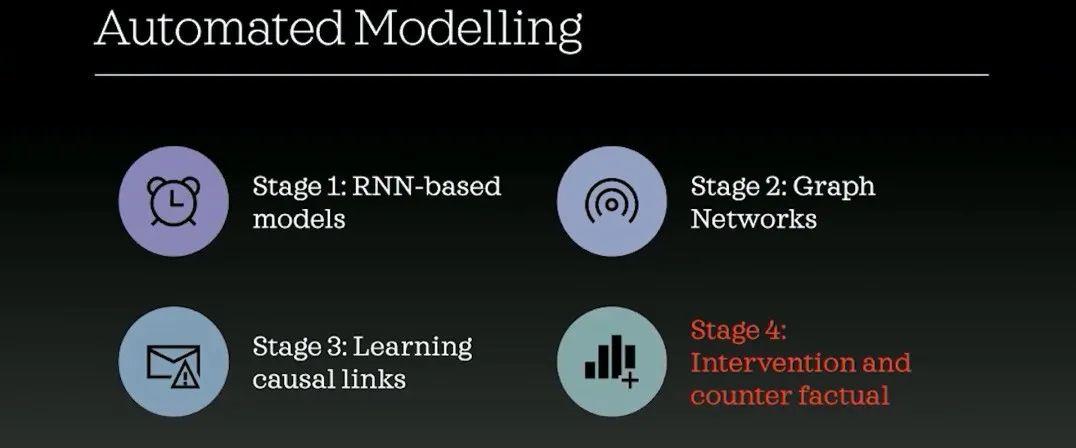
第一阶段:基于机器学习(RNN)的因果建模
第一阶段是基于大家比较熟悉的机器学习的方法的模型,如循环神经网络。
这方面张江老师带着学生许菁做了一个工作,即希望对一些大的相关企业,如北美大概3万家上市公司,通过各种财务指标和财报数据的历史的时间序列、包括宏观经济环境,能够预测出来每个企业的发展的轨迹。
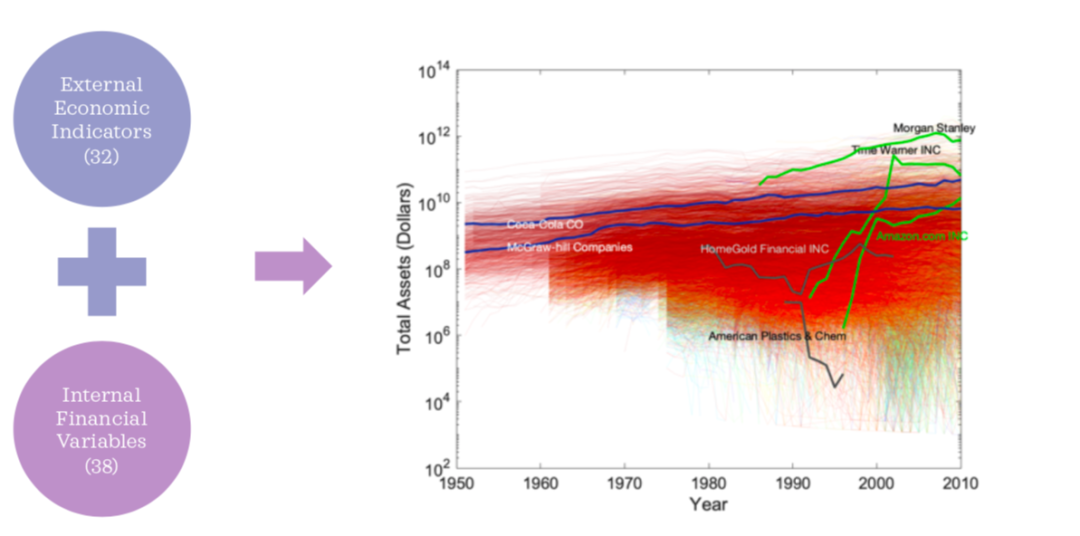
之前张江老师一直在跟圣塔菲研究所 Geoffrey West 合作,用规模理论得到的增长方程作为一个因果模型对企业进行研究。这是物理学视角,方程是典型的因果关系,也是人类的先验知识。但企业增长必然有噪声部分,那么这部分就可以通过机器学习方法去学习,如LSTM模型去学习。通过研究发现,事实证明这两种方法结合效果是最好的,比分别两种做的都更好,都更加准确。
例如在对AT&T公司分析中,对它的各种指标,包括它的总资产长期债务等等这些指标来进行预测,可以看到代表粉色曲线的模型的工作,与蓝色的曲线是真实的走向,模型的预测准确度基本上是可以做到10%以下。这比纯靠物理学增长模型和纯靠LSTM模型结果都要好得多。此外,在对长期预测中,对一家叫 agent Information software的 IT 公司,仅仅用 5 年数据预测30年走势比较长的历史,也能做到 10%以内误差。

所以这就证明,仅仅是人类先验赋予机器的因果知识,将其和机器学习的方法揉合在一起,都是具有非常大威力的。
第二阶段:基于图神经网络的模型 在这方面,张江老师小组的王硕和李嫣然同学,完成了一个工作 《PM2.5-GNN: A Domain Knowledge Enhanced Graph Neural Network For PM2.5 Forecasting》 https://arxiv.org/abs/2002.12898 这实际是一个雾霾预报系统。和上面工作思路类似。其中得到的历史数据是各个监测城市质量监测点它的历史的时间序列,然后希望预测未来雾霾 PM2.5。

雾霾在空气中的流动是一个非常复杂的物理化学的过程,显然不能从微观层面进行建模。那么就可以考虑宏观层面,引入从图结构。例如上面图中蓝色的线,把任意两个城市的质量空气质量的监测点给它连接起来。它的含义就是,我们已经把这个世界的因果联系的一些信息引入了进来了。例如,某条线实际上就意味着在北京的雾霾,会对石家庄的雾霾会有影响,而加这条线又来自空间的位置和地形等一些基本规则。
此外,还可以引入气象其他一些数据,如地质情况等。结果证明,在引入人类加入的因果信息之后,图神经网络的学习效果非常好。
第三阶段:学习因果网络(Learning Causal inks)
然后是第三个阶段,对因果网络的学习。在前面的例子中,虽然在模型中加入因果结构会大幅度提高预测性能,但这些方程或知识是高度依赖于人类的先验知识的,如果没有的话,那该怎么办?能不能自动的去把因果网络网络学习出来?这方面张江老师小组也做出了相关工作,在这篇由多人合作发表在 Springer 的论文《A general deep learning framework for network reconstruction and dynamics learning》中,就提供了一个对因果网络基于网络重构和动态学习的通用深度学习框架。
在这个被称为 Gumbel 图神经网络(Gumbel Graph Network,GGN)的框架中,引入一种经典的因果定义:格兰杰因果(Granger Causality)。例如,在预测 y 的时候,如果把 x 引进来,会提升对外信号预测的准确度的时候,那么就认为 x 是 y 的一个格兰杰因,即 x → y。这时 y 就是 x 的格兰杰果。可以看到,这里的因果关系就是两个信号之间的联系。
GGN 这个框架就是基于格兰杰因果联系的连边,它是一个无模型、数据驱动的深度学习框架,可以实现因果网络连接和动态的重构。在不同类型的时间序列数据上展示了测试框架的通用性可以验证,在相同的结构下,这个模型可以训练成连续、离散和二进制动态的精确恢复网络结构和预测未来状态,并且优于其他竞争的网络重建方法。
第四阶段:干预和反事实因果
但是,即使做到前面的因果网络结构,它还不是真正的因果,例如格兰杰因果定义,它本质还是一种相关性。真正的因果性是一种开放性的模型,能够和外界交互,具有干预性,甚至能够进行反事实推理。也就说,在发生 a 导致 b 的情况下,如果 a 不发生会出现什么情况。这方面 Judea Pearl 已经有了相关理论,相关研究也还在探索中。
张江老师认为,更本质具有因果思维能力的 AI 模型,就像最近一期 nature文章所展示的那样,是一个 AI 的化学家机器人,它可以自己去做实验。虽然它目前自动建模的手段还是比较初级的、只是贝叶斯的方法,但是如果继续下去,就很有可能做成一个真正和外界互相交互的开放系统、甚至反过来进行指导人类。这时候 AI 所具有的联系能力就是真正的因果能力了。

袁源——识别数字平台亲社会行为因果关系

袁源麻省理工学院数据、系统和社会研究所的博士生。他也是麻省理工学院媒体实验室(MIT Media Lab)人类动力学小组的研究助理。清华大学计算机科学和经济学的学士。
来自麻省理工学院系统和社会研究所的博士生袁源,则带来了基于数据平台识别亲社会行为的影响相关研究,其题目是《Identifying the impact of prosocial behavior on digital platforms》。他目前也是麻省理工学院媒体实验室(MIT Media Lab)人类动力学小组的研究助理,以及清华大学计算机科学和经济学的学士。
现在社交网络兴起,存在许多群组,无论是家庭群、朋友群还是工作群,在其中朋友之间礼物可以起到很重要的社会连接作用,而雇主对通过分发礼物给他们的员工,也可以帮助提高员工的工作的效率。但在发群礼物、群红包时,一般不会直接发给某个接收者,而是直接发在群里。因此这种发礼物行为就可能具有一种社会传染性。即是说,当一个人收到了礼物,会促使他们去发更多的礼物。这样的关系其实就是一种因果的关系。
因此就可以通过一些因果推断手段去分析传递性的因果机制。袁源研究工作从红包机制构建数据模型开始。
首先是对使用的观察数据寻找社会传染性。这需要时间上的一种聚集性,称之为 temporary classroom;其次是社会学一个概念叫红包分裂,意思大概是说人们喜欢跟他相近的人,接触或者是成为朋友。这就是说在微信或者在其他社交网络平台的场景下,有钱的人或者是更喜欢发红包的人,这些相似的人更可能跟他相似的人聚集在同一个群里。
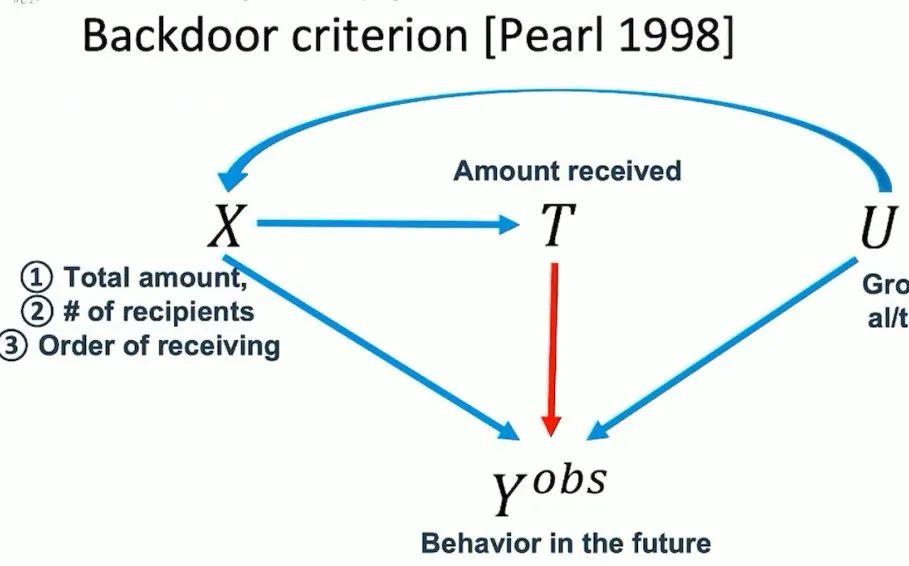
接下来最终重要的一点是利用红包下发机制。它给定了红包的金额大小、你是第几个红包接收人等几个变量下的随机数。因此就相当于进行随机实验控制变量,使得即使从观察数据中也足以能找出其中因果关系。
最终这项基于因果推理技术的研究证明了在线亲社会行为事实:1. 通过随机分配算法设置在线送礼机制,表明在线送礼的社会传染行为,收到礼物会导致收礼人送更多的礼物,并与用户有更多的社会互动。2. 通过使用高维度匹配来量化人们健身行为的亲社会激励的影响,发现这种亲社会激励的影响和同伴效应一样强大。
杨淼钰:计量经济学因果分析工具在快手中的应用
杨淼钰,快手经济学家,华盛顿大学经济学博士。2012年~2019年在亚马逊任职经济学家,先后在亚马逊电商、供应链技术优化、商务和企业发展部任职。2019年加入快手,在快手负责损益相关的生态分析。
在产品迭代和公司決策中,一个很重要问题是:一个动作 A 是如何影响 B 的?例如设置上下滑的功能是如何影响用户的视消费、直播消费、生产等体验,甚至影响用户对于平台的长期留存的?
传统解决以上问题的方法是使用 A/B 实验。但如果没有条件、在不方便传统方法情况下,那就需要使用因果分析的方法,结合观测数据来回答这个问题。在快手则是基于因果分析的计量经济学和机器学习方法来解决这些归因问题。
快手经济学家杨淼钰分别介绍了这两种因果分析方法是如何在产品具体业务中与实践相结合的。

对计量经济学方法而言,首先是工具变量法,它基于线性回归。但如果对 y 对于 x 进行线性回归的话,通常会有内生性的问题,即 x 能影响 y,但同样未知观测因素 ε 也会影响 y,使得 x 与 ε,估测出来的 β 是有偏的。因此如果能找到一个工具变量 z ,能满足和 x 相关但同时和 ε 不相关,即满足外生性,排除了不可观测的因素影响,这样就能通过用 x 和 z 来解释 x 当中的变化了。对此快手通常使用的是一个二阶段的最小二乘法,最后会得到比线性回归要好得多的结果。
在快手,通常会认为实验是一个比较好的工具变量。例如在新用户它转化成一个视频作者以后的收益是什么?这个问题中,就会给实验组的新用户发消息告诉促使他发布第一个作品;然后控制组不对其进行任何影响。
这样的随机实验就满足外生性的条件。如果实验组发消息的当天,用户成为新作者的可能性比控制组是显著提高的了,就可以认为这个工具变量确实是和想要回答的问题是相关的,再用最小二阶段最小二乘法去估计。从统计结果可以看出,新用户转化成作者之后,他对于未来的行为,周活跃天数和未来一周的发作品数都是显著提升的。这就是工具变量法的应用。
然后比较经典的一种方法是双重差分法。杨淼钰举了主要的产品的案例,一个是快手的主站,一个是快手的极速版进行对比的例子:安装了极速版的用户,对于他之前在主站上的行为有没有影响?如果仅仅比较安装了极速版,安装和没安装的用户的差异的话,这两类用户本身是有一定的不同的,会导致结果不准,因此就需要双重差分。

如上图,双重差分依赖于一个关键假设:平行趋势假设。在此比较两条曲线算出来的变化之差,即图中构造的灰线的部分(安装了极速版的用户,没有安装极速版的)情况是一个虚拟的事实。
但是在双重差分之后,如果平行检验没有通过,那就需要尝试匹配法。匹配的方法就是希望去除掉隐藏变量造成的选择性偏差、能够使实验组和对照组之间的比较更加的合理。特别是在一些渗透率低的情况下,用直接对比实验组和控制组往往得不到显著差异的,这时用匹配法就能更准确估计得到它们之间的差异。

杨淼钰为此举了快手直播中连麦的功能例子。即用户如果看到主播连麦功能被打开,可以申请和主播连麦,进行一对一实时互动。通过匹配比较接近的用户(分布图概率分布是比较像)在实验组和控制组进行对比,二者双重差分的平行趋势检验也比较好,但是开启之后就会发现有显著的差距,这样测出来双重差分的结果就意味着连麦功能对于主播的开播以及用户的观看都具有很明显的正向效应。
然后还有一种叫合成控制的方法,主要是用在聚合数据上。在通常实验组就比较少,只有一两个或几个情况下,就很难找到特别好实验对照组。之前方法主要是用在个体的数据上,这里合成控制法则用于聚合的数据上,可以构造出一个虚拟的对照组,来和实验组进行进行比较。

这个方法举了美国加州控制烟草的法案和一个虚拟州的例子,还有然后另一种场景是新的APP版本上,更新了ui界面,还有用户自己选择个版本的时间的例子。
但在后者的例子里,因为时间是不一致的,所以新界面对于用户的影响是没有办法通过简单的合成控制法、或双重差分这样的方法来进行比较的。这就需要一种新的算法,即矩阵补全法。对两个不同状态的矩阵,通过机器学习其他对象的信息进行补全、转变为一个凸优化问题,最后进行因果效应估计。
这个方法举了快手的K歌功能上线的例子,用户其实是逐步更新版本、发现功能,然后才开始使用。可以看到实际的实验组和补全的实验组之差,其实就是中间的因果效应。结果表明这个功能对于作品量还是有一定的正向影响的。
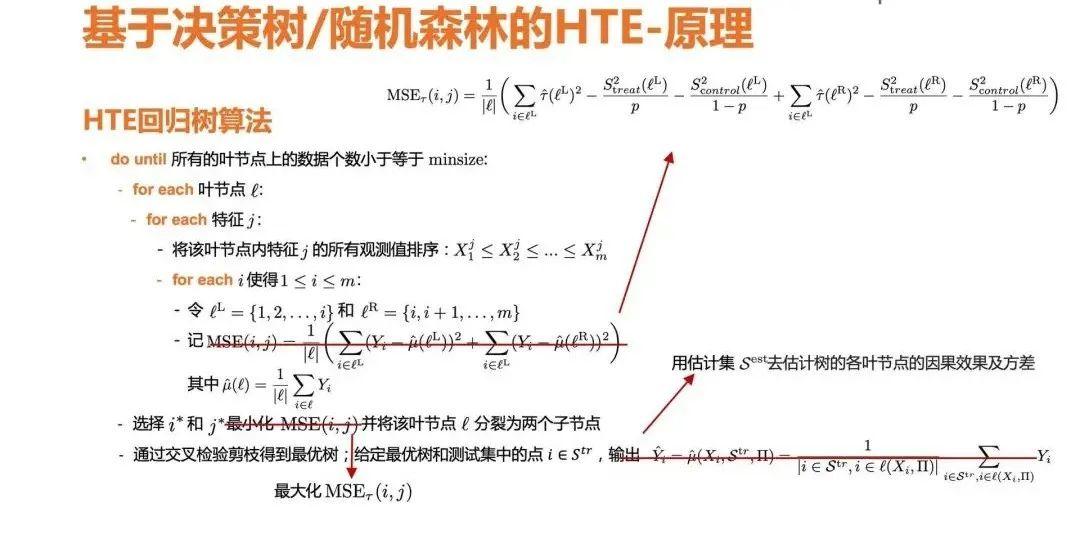
 最后杨淼钰介绍了基于决策树/随机森林的异质性的因果效应估计。 传统互联网方法去理解用户群体,去做个性化的推荐和功能,主要是用户画像,这样不仅效率低,更容易造就伪相关。 而通过决策树的算法划分用户画像,如果用训练集来构造数的节点,然后用估计集来构造各个节点的因果效应和方差,就能够减少因果效应的方差偏差。这里算法只需要在实验组和控制组之间的一个均值的差,不是去最小化它,而是去最大化因果效应,然后在最后输出时用估计集估计级去估计输入的各个节点的因果效应和方差即可。 在讲座中举了一个产品实验作为具体案例。某个产品改版造成了整体的负向的影响,因此想要去找到一些有正向收益的用户。通过决策树算法生成树,就能确实找到了一批年龄小于40岁、而且是属于四五线城市满足要求的用户,他们对于实验是具有很明显的正向收益的。因此就可以针对性的对这群用户进行优化了。
最后杨淼钰介绍了基于决策树/随机森林的异质性的因果效应估计。 传统互联网方法去理解用户群体,去做个性化的推荐和功能,主要是用户画像,这样不仅效率低,更容易造就伪相关。 而通过决策树的算法划分用户画像,如果用训练集来构造数的节点,然后用估计集来构造各个节点的因果效应和方差,就能够减少因果效应的方差偏差。这里算法只需要在实验组和控制组之间的一个均值的差,不是去最小化它,而是去最大化因果效应,然后在最后输出时用估计集估计级去估计输入的各个节点的因果效应和方差即可。 在讲座中举了一个产品实验作为具体案例。某个产品改版造成了整体的负向的影响,因此想要去找到一些有正向收益的用户。通过决策树算法生成树,就能确实找到了一批年龄小于40岁、而且是属于四五线城市满足要求的用户,他们对于实验是具有很明显的正向收益的。因此就可以针对性的对这群用户进行优化了。
从快手经济学家杨淼钰的分享可以看到,结合计量经济学的因果推理对现有产品设计和运营是有着实实在在的改进作用的。因果分析已不仅是理论研究,已经在真实改变世界。
整理:十三维
编辑:刘培源
因果科学与Casual AI系列读书会
数据科学已经深刻影响了各个研究领域的发展,让机器学习、深度学习、大数据等深入人心。而“因果革命”正在酝酿数据科学的一场新革命,尝试用科学方法,解决当前人工智能面临的稳健性、可解释性、因果推断等一系列问题。通过融合因果推理和机器学习而构建出来的Causal AI系统,有望奠定强人工智能的基石。
集智俱乐部梳理了关于因果推理、因果发现的一系列论文和模型,并邀请一批对因果科学与Casual AI感兴趣的研究者,开展为期2-3个月的系列线上读书会,研读经典和前沿论文,并尝试集体完成一部书籍作品。如果你也从事相关的研究、应用工作,欢迎报名,参与集智俱乐部社区学者的讨论!
时间:9月20日起,每周日晚19:00-21:00,持续2-3个月
模式:线上闭门读书会;收费-退款的保证金模式;读书会成员认领解读论文
费用:299/人 读书会具体规则及报名方式请点击下方文章了解: 因果科学与Causal AI系列读书会 | 众包出书
集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”

让苹果砸得更猛烈些吧! 点击👇“阅读原文”,看大数据与社会计算会议录播
本篇文章来源于微信公众号: 集智俱乐部
微信扫一扫,分享到朋友圈











