DeepMind提出多人游戏的网络分析方法 | Nature communications研究速递

导语
从复杂系统的角度来看,同样是多人策略游戏,Dota和LOL之间有何区别?11月5日,S. Omidshafiei等多位DeepMind研究员在Nature communications发表论文,将游戏看成是多个智能体(agent)之间的博弈,并结合图论,构建了游戏的策略空间。该研究所提出的框架对于游戏设计、AI训练、多主体建模等都有所启发。

论文题目:
Navigating the landscape of multiplayer games
论文地址:
https://www.nature.com/articles/s41467-020-19244-4#Sec2
多人游戏与策略空间
多人游戏是评价和训练AI的重要实验平台,以DeepMind为代表的研究者在国际象棋、围棋等两人零和游戏中创造出了超出人类能力的智能主体agent。
但是要继续取得进步,就需要对游戏进行适当的分类,评估不同游戏的特性,从而针对性地训练agent。StarCraft II(星际争霸)、德州扑克等多人互动类型的游戏对AI技术提出了挑战。
为了研究游戏中多个agent之间如何互动,DeepMind研究者利用图论工具,深入分析了一些大型游戏的拓扑结构。相关成果近日发表在Nature communications上。
该研究的创新点在于建立了能自动化地发现游戏中的拓扑结构的工具,使得各类游戏都被放在同一策略空间中进行分析。
所谓策略空间(landscape of games),可以看成是将游戏的背景抽离,而只关注游戏中玩家的策略和互动怎样影响玩家收益。
玩家从青铜到黄金的升级过程,不仅是策略的提升过程,更是玩家(或玩家的策略风格)在策略空间的移动过程。有些游戏所需的策略,位于策略空间的高原,一开始就不容易。而有些游戏所需的策略位于山地,最初入门不难,但爬到山顶却困难重重。这两种游戏因为其学习曲线的差异,在策略空间的不同位置。
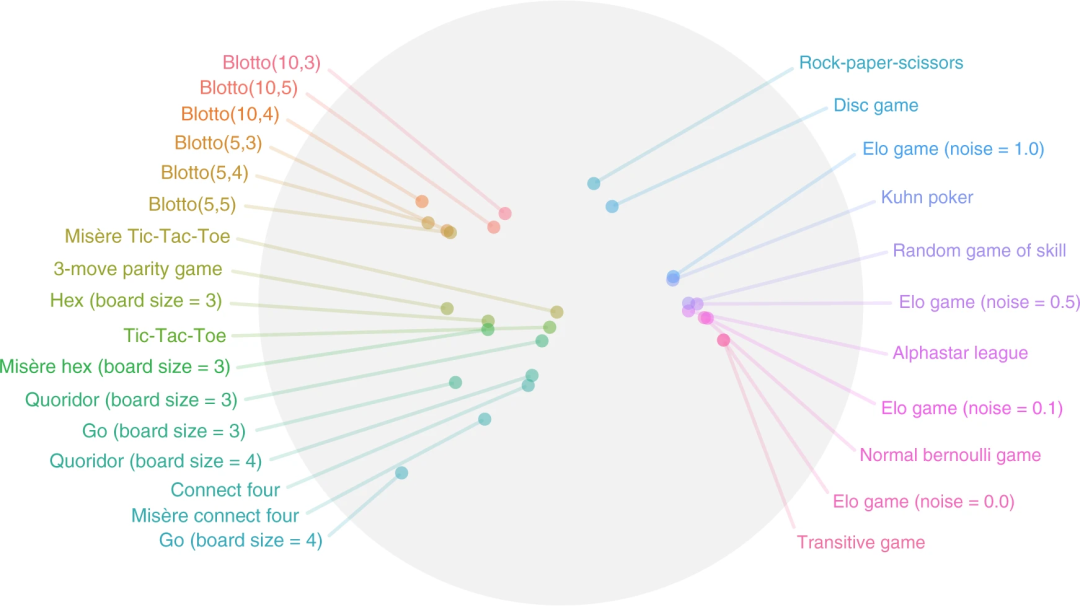
图1:将不同游戏置于同一策略空间
研究者将不同游戏置于同一策略空间,如图所示,其中位置相近的游戏,尽管其规则不同,但其在策略空间上的相近意味着游戏玩家所需的策略相似。
策略空间下的三种游戏
无论一个游戏是否有趣,游戏中必然涉及到几个玩家、多种策略,还可以考虑游戏的结果是否零和,不同玩家间是否对称。这些考虑角度都可以看成是从拓扑结构上分析游戏。对于简单的游戏,用上述的指标可以将其分类。
而对于真实世界中更复杂的游戏,可以根据策略的计算复杂度进行分类。然而一个计算上有挑战性的游戏,并不一定有趣。这说明游戏很难通过单一维度分类。
研究者采用的分析方法,是将不同的策略(或者代表某个策略的agent)看成一群节点,分析不同策略(或agent)之间的关系。并建立收益矩阵和网络。
根据不同策略之间的对比,可以构建收益矩阵,如图2所示。每个游戏由两个玩家组成,每个玩家有10个策略(从S0到S9)。格点颜色代表两两策略在游戏中出现时对应的收益(payoff)。红色表示收益为正,即该策略赢了对位的另一种策略。收益为负则是青色。
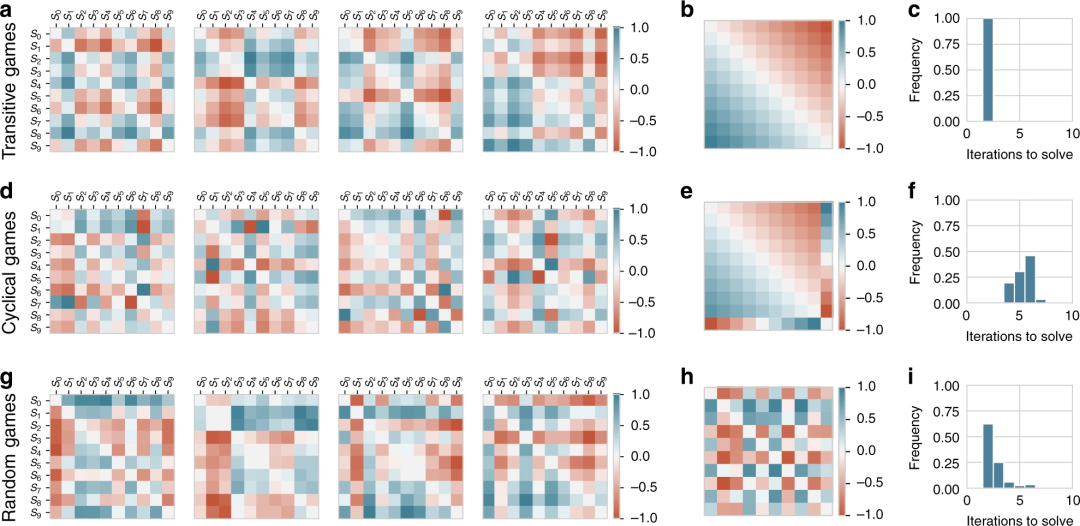
图2:不同策略相遇时,对应的收益矩阵
尽管游戏收益变化各种各样,但当我们剔除游戏本身随机性导致的差异,就可以将游戏分为三类,分别是可传导型(图2-b)、循环型(图2-e)和随机型(图2-h)。
可传导型游戏有明确的传递顺序,例如Elo机制游戏,排位高的玩家往往对应着更优的策略。循环型游戏,其策略具有周期性的结构。经典的循环游戏是石头剪刀布,策略之间彼此制约,形成循环。而随机型游戏,则缺乏清晰的特征。
在这三类游戏中,收益变化还会显著影响解决游戏的难度,如图2-c、图2-f、图2-i所示。
如何分析游戏的策略空间
该研究中,对于石头剪刀布这样的简单游戏,可以穷举出所有可能的策略。而对于星际争霸这样的大型游戏,则是通过抽样,选出部分策略。进而构建上述的策略矩阵。
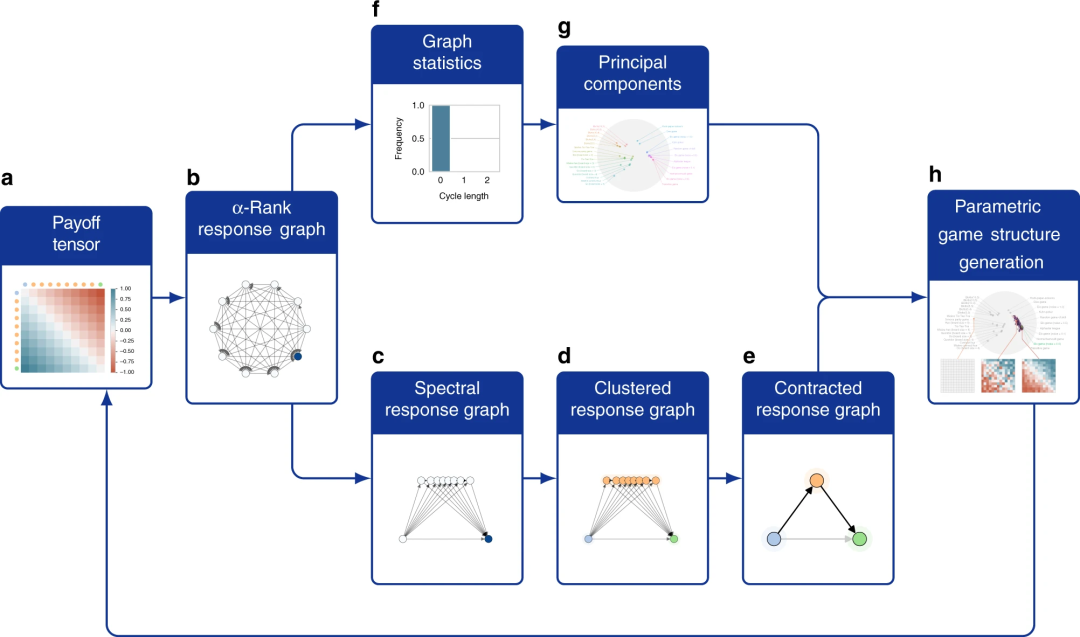
图3:构建游戏之间策略空间的流程
构建不同游戏策略空间的步骤如图所示。首先是根据α-Rank算法,将收益矩阵拆分为不同策略间的转移概率。之后将该图的特征值映射到拉普拉斯空间,通过频域分析,将相似的策略聚类。再构建出高层次的策略转移图(从c到e),而将图中的统计量进行主成分分析(从f到g)。
最终根据主成分和游戏策略分类,就可以生成游戏的策略空间。不同策略类型的游戏占据不同的空间位置。
这种将游戏表示为图或网络的方法,能使我们对游戏底层结构和复杂性有更多的洞察。在论文中,作者还发现游戏策略网络的复杂度和解决游戏的复杂度之间具有显著的相关性。
对AlphaGo和AlphaStar的策略分析
这套方法能够用来分析复杂的游戏,并将其归类。
AlphaGo和AlphaStar是DeepMind分别为围棋和星际争霸设计的游戏AI。研究者根据上述流程,分别研究了它们在游戏策略空间的位置,以及对应的游戏类型。
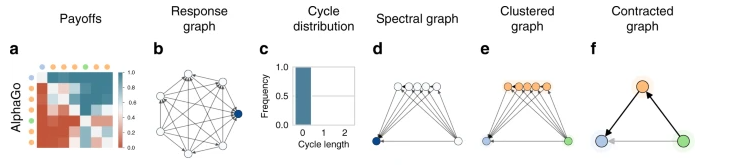
图4:AlphaGo的游戏策略进行分析的过程
如上图所示,对AlphaGo策略聚类后,最终能够将围棋归为循环型的游戏,即不存在一个始终占优的策略。这也符合我们的常识。
除了归类,该方法还可以区分不同策略等级的玩家(agent)所带来的影响。
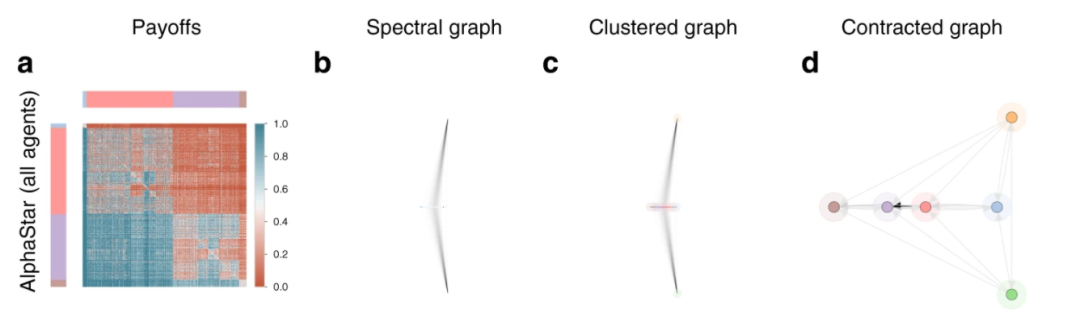
图5:使用所有AlphaStar版本来分析星际争霸
在对星际争霸这样涉及三个种族的对战类游戏的分析中,使用AlphaStar的不同版本(对应不同能力级别的策略),可以构建出游戏的策略空间,如图5所示。可以看到图5-d中,不存在一个最优的策略。是循环型游戏。
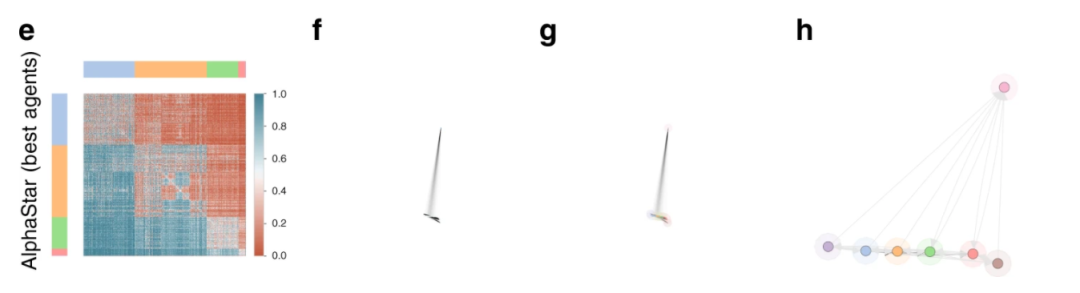
图6:只用最强的几个AlphaStar来分析星际争霸
而只使用最强的数个AlphaStar智能体,构建策略的收益矩阵,经过相同的分析步骤,却可以得出截然不同的结论。如图6-h所示,存在一个比其他策略都好的最优策略。这意味着对很强的AI来说,星际争霸是可传导型游戏。强者之间博弈,反而更容易找到最强的。
研究游戏策略空间的意义
该研究首次结合博弈论和图论,根据游戏策略间的关系构建网络,对多种游戏进行了统一分析,论证了复杂网络方法可以用来解决游戏规则生成等问题。
AI的发展,与待解决的问题息息相关。挖掘出游戏的策略空间,未来就可能人工生成位于特定策略空间位置的新游戏,并且设计特定的AI解决该游戏。这会让AI研究更有针对性,进而扩展AI可能的应用领域。
如何生产大量有趣的自适应环境以支持研究,是多主体建模、人工社会、人工生命等领域长期关注的问题。构建游戏策略空间,对多主体建模的环境、规则设计也有所启发。
除了对游戏AI和建模设计的启发,在其他学科中涉及多个参与者或多种策略的复杂博弈问题,例如入侵物种和本地物种间的相互作用,也可以借鉴本研究提供的框架。
作者:郭瑞东、刘培源 编辑:邓一雪
复杂科学最新论文
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

推荐阅读

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”

让苹果砸得更猛烈些吧!
👇点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











