为了帮助大家更好地了解因果科学的最新科研进展和资讯,我们因果科学社区团队本周整理了第2期《因果科学周刊》,从 Causality, Causal Inference, Causal AI 三个维度鸟瞰,推送近期因果科学值得关注的论文和资讯信息, 同时我们也将向大家介绍社区正在推进的活动——因果科学与Causal AI读书会第6期中的主要报告内容、观点。
本期作者:况琨,龚鹤扬,陈晗曦,陈天豪,张卓婧,杨雅程
本期周报中的论文推荐,将围绕因果科学领域的“混淆偏差”问题展开,关于它的解释,大家可以先看下面这个例子(熟悉的朋友也可以忽略这部分内容,直接阅读下面的“论文推荐”)。
锻炼能否降低胆固醇呢?如下图1,从每个年龄层来看可以降低,但是如果不分层则会提高胆固醇。
这个问题便涉及混淆偏差,回答它仅仅靠数据不够,需要因果建模,转化本期周刊关注的因果问题:在拥有治疗变量 T,协变量 X 和结果变量 Y 的观测数据下的因果效应估计。
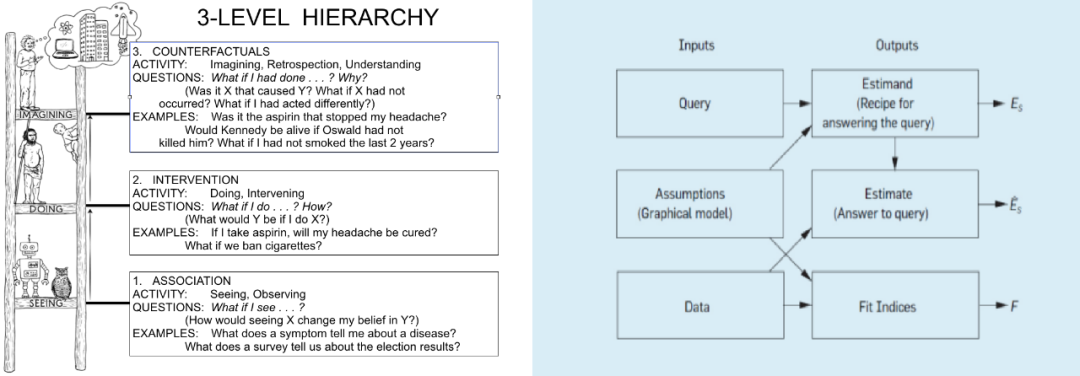
推理引擎中,该问题属于因果之梯干预层的 Query,而 Data 是观测数据,Asumptions 则经常用潜结果框架(Potential Outcome)来描述。
关于该因果问题如何回答,也就是去混淆偏差,浙江大学助理教授况琨向大家推荐了几篇论文,我们根据“基于匹配方法”“倾向评分方法”和“直接均衡方法”三个类别分别选择两篇论文进行了整理和解读。
前两篇论文是基于匹配的方法 (Matching based method) ,该方法基本思想是对比相似个体用药和不用药产生的效果差异。中间两篇是以倾向评分为工具,给定倾向评分则类似于随机化实验,而最后两篇是通过直接加权创造一个新的总体,使得混淆变量和治疗变量独立的方法。
1.1 基于匹配的方法(Matching based method) 一个前沿理论框架
Kallus, N. 2017. A Framework for Optimal Matching for Causal Inference. In Artificial Intelligence and Statistics, 372–381.
论文标题:因果推断的最优匹配框架框架
摘要:本文提出了一种从观测数据中进行因果推断的广义最优匹配方法 (generalized optimal matching, GOM),它涵盖了 atching、covariate balancing 以及 doubly robust 等方法。这套框架是基于对最优匹配的一种新的泛函分析的推广提出的,它产生了一类 GOM 的方法,本文提供了一套统一的理论框架来对它们进行可解性和一致性分析。许多已有的方法都可以被纳入 GOM 的框架,利用GOM视角的解释,可以将它们拓展成一种最优且自动的方差与性能之间的平衡策略。Kernel optimal matching (KOM) 作为GOM的一类子类,理论和经验结论表明,可以将许多方法的优点汇集在这一类方法中。KOM可以转化为求解线性约束的凸二次优化问题,在继承了可解释性与 model-free 的匹配一致性同时,还实现了在特定回归问题下的 、减少 bias 以及和 doubly robust 方法相当的鲁棒性。在有限重叠 (limited overlap) 的设定下,KOM是一种对于部分识别和鲁棒覆盖问题的可移植的区间估计方法。文章在生成数据和真实数据下验证了这点。
Kallus, N. 2019. Generalized optimal matching methods for causal inference. The Journal of Machine Learning Research (forthcoming)
、减少 bias 以及和 doubly robust 方法相当的鲁棒性。在有限重叠 (limited overlap) 的设定下,KOM是一种对于部分识别和鲁棒覆盖问题的可移植的区间估计方法。文章在生成数据和真实数据下验证了这点。
Kallus, N. 2019. Generalized optimal matching methods for causal inference. The Journal of Machine Learning Research (forthcoming)
论文标题:因果推断的广义最优匹配方法
摘要:本文唯一作者 Nathan Kallus 也是上一篇推文“A framework for optimal matching for causal inference”的唯一作者,本文“Generalized Optimal Matching Methods for Causal Inference”是基于上一篇工作推广的后续工作,整体上延续了先前的研究思路,但是给出了更详尽的理论依据并提出了KOM++这种新的匹配策略。文章的理论性同样十分强,但作者也在KOM章节给出了一些诸如 kernel 选择等实践化的建议与讨论,十分推荐在因果推断 matching 领域的研究者阅读,也建议对因果推断、机器学习理论感兴趣的朋友进一步阅读。
1.2 基于倾向评分的方法 (Propensity score based method),一篇综述和一篇前沿
Austin, P. C. 2011. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivariate behavioral research 46(3): 399–424.
论文标题:在观测研究中用于减少混淆变量影响的倾向性评分方法简介
摘要:倾向性评分是给定观测特征条件下的接受治疗概率赋值,它通过模仿随机化实验的一些特定特征来允许研究者进行观测研究的设计和分析。具体而言,倾向性评分是一种平衡评分:在给定倾向性评分情况下,观测到的协变量分布会近似于随机化实验的分布。本文讨论了四种倾向性评分方法:基于倾向性评分的匹配法、基于倾向性评分的分层法、基于倾向性评分的 inverse probability of treatment weighting(IPW) 法以及基于倾向性评分的协变量调整法。本文描述了一种平衡诊断程序,用于检验使用的倾向性评分方法是否合理。此外,本文还讨论了基于回归的方法和基于倾向性评分的方法在观测数据分析上的区别。文章最后描述了不同的平均因果效应与倾向性评分分析的联系。
Kun Kuang, Peng Cui, Hao Zou, Bo Li, Jianrong Tao, Fei Wu, and Shiqiang Yang. Data-Driven Variable Decomposition for Treatment Effect Estimation, IEEE Transaction on Knowledge and Data Engineering (TKDE) , 2020
论文标题:数据驱动的变量分解用于因果效应估计
摘要:因果推断的一个基本问题是观察研究中存在混淆变量时的因果效应估计。倾向性评分常被用于混淆效应的控制。但它将所有观察到的变量视为混淆变量,从而忽略了那些对处理没有影响,但对于结果具有预测性的调整变量。最近研究证明,调整变量可以有效减少估计因果效应的方差。然而,如何自动分离混淆变量和调整变量依然是一个开放性问题。在这篇文章中,我们首次提出一种数据驱动的变量分解 (Data-Driven Variable Decomposition, D2VD) 算法,它可以自动将变量分离为混淆变量和调整变量,并同步地估计因果效应。在标准假设下,我们从理论上证明了D2VD 算法能以更低的方差给出因果效应的无偏估计。此外,为了解决非线性问题,我们提出了一种非线性的D2VD (Nonlinear-D2VD, N-D2VD) 算法。为了验证算法的有效性,我们在合成数据集和真实数据集上进行了大量的实验。实验结果表明,与现有的方法相比,D2VD 和 N-D2VD 算法能够自动而精确地分离变量,更准确地估计因果效应,且方差更小。我们还表明,在一个在线广告数据集中,我们的算法产生排名靠前的特征具有最好的预测性能。
1.3 直接混淆因子均衡方法 (Directly confounder balancing)
K. Imai and M. Ratkovic. Covariate balancing propensity score. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 76(1):243–263, 2014.
论文标题:协变量均衡的倾向评分
摘要:倾向评分在各种因果推断中扮演着核心角色。特别地,在观察性数据的分析中,基于倾向评分估计的匹配和加权方法愈发常见。尽管这些方法广受欢迎,而且在理论上具有吸引力,但是它们实际困难主要是必须估计倾向评分。研究者已经发现,对倾向评分模型的微小误判会导致因果效应估计的严重偏差。我们引入协变量均衡的倾向评分 (Covariate Balancing Propensity Score, CBPS) 方法,在对 Treatment 赋值进行建模的同时,优化协变量均衡性。也就是说 CBPS 同时利用倾向评分帮助协变量均衡和建模 Treatment 赋值条件概率。CBPS 的估计可以用广义矩估计或者经验似然框架实现。我们发现 CBPS 显著改善了倾向评分匹配和加权方法在文献报道中糟糕的实证表现。我们还表明,CBPS 可以推广到其他重要的环境中,包括估计非二值处理的广义倾向评分以及将实验估计值推广到目标人群。我们提供了一个开源软件用于实现上述提出的方法。
Kun Kuang, Peng Cui, Bo Li, Meng Jiang, Fei Wu and Shiqiang Yang. Treatment Effect Estimation via Differentiated Confounder Balancing and Regression, Transactions on Knowledge Discovery from Data (TKDD) , 2019.
论文标题:通过区分性混淆变量均衡和回归得到因果效应估计
摘要:因果效应在诸如社会营销、医疗保健和公共政策等领域的决策中扮演着重要角色。在一般的观察性研究中,估计因果效应的关键挑战是控制由处理单元和对照单元之间混淆变量分布不均衡引起的混淆偏差。传统的方法在无混淆性假设下,用假定是准确的倾向评分估计来重新加权单元,以消除混淆偏差。控制高维变量可以使无混淆性假设更加可信,但却在准确估计倾向评分上产生了新挑战。最近的一系列文献希望跳过倾向评分估计,直接优化权重来均衡混淆变量的分布。但是当前的均衡方法无法在大量潜在的混淆变量做出选择和区分,导致在许多高维环境中可能表现不佳。在这篇文章中,我们提出了一个数据驱动的区分性混淆变量均衡 (Differentiated Confounder Balancing, DCB) 算法,来联合选择混淆变量、区分混淆变量权重和均衡混淆变量的分布,以在高维环境下实现因果效应估计。此外,在一些存在严重混淆偏差的情况下,为了进一步减小因果效应估计的偏差和方差,我们提出一种回归校正的区分性混淆变量均衡 (Regression Adjusted Differentiated Confounder Balancing, RA-DCB) 算法,这种算法基于我们的DCB算法,并纳入了结果回归校正。我们提出的协同学习算法更能减少许多观察性研究中的混淆偏差。为了验证上述DCB算法和RA-DCB算法的有效性,我们在合成数据集和真实世界数据集中进行了大量实验。实验结果清楚表明我们的算法比当下流行的方法具有更好的表现。通过纳入回归校正,我们的RA-DCB算法估计得到的因果效应比DCB算法得到的具有更高的精确度,特别是在严重混淆偏差的情况下。最后,我们展示了由我们算法所产生的排名靠前的特征可以准确地预测在线广告的效果。
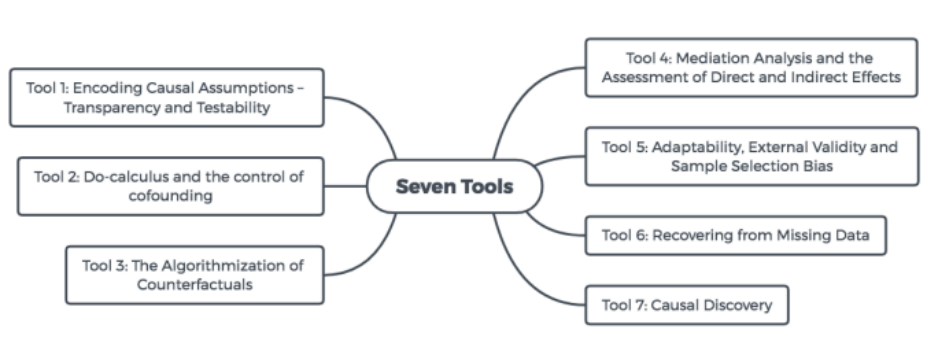
本次推荐的论文主要属于 Causal Inference for Data Science ,七个因果推断工具中的第二个 The Control of Confounding 有关内容。
我们本次的资讯推荐包括一门新出的因果课程,两个 Causal AI 方面报告,一篇因果迁移学习的论文(正是我们读书会本周周末的将要分享主题)。
2.1 Causal AI课程
课程名:Introduction to Causal Inference (ICI) from a Machine Learning Perspective
这门课程由 Yoshua Bengio 高徒 Brady Neal 主讲,主要讲述因果推理相关知识。此外,该课程整合了来自许多不同领域的见解,如流行病学、经济学、政治学和机器学习等,这些领域都利用到了因果推理。
课程链接:https://www.bradyneal.com/causal-inference-course#course-textbook
2.2 Causal AI报告
报告名:Symbolic, Statistical and Causal Artificial Intelligence
在 MLSS2020 上,Bernhard Scholkopf 首先简单介绍了该机器学习暑期学校,它将会涉及从基础到 state-of-art 的现代机器学习核心主题。然后回顾了人工智能的历史,指出 Causality 将会是下一代人工智能的关键。
Bernhard Scholkopf 讲座 Causal AI
课程链接:https://www.youtube.com/watch?v=8staJlMbAig
报告名:因果强化学习(Causal Reinforcement Learning)
在ICML2020上Elias Bareinboim教授组织了关于因果强化学习的 Tutorial, 介绍了因果和强化学习之间的联系,并且总结了因果强化学习中的6个重要的任务:将在线学习和离线学习结合,在强化学习中加入合适的干预,反事实决策,使用强化学习提取因果模型,以及在 Reward 未知的情形下训练强化学习模型。
见 ICML2020 https://crl.causalai.net/
Edmonds M, Ma X, Qi S, et al. Theory-Based Causal Transfer: Integrating Instance-Level Induction and Abstract-Level Structure Learning[C]//AAAI. 2020: 1283-1291.
论文标题:基于理论的因果迁移:实例级别的归纳及抽象级别的结构学习
摘要:在相近但不同的设定间学习可迁移的知识是通用智能的基本组成。本文从因果理论的视角来逼近迁移学习的挑战。本文的智能体被赋予两条基础但一般性的理论来进行迁移学习:(i)跨域的任务间有一个不变的一般性抽象结构;(ii)环境表现出的特定特征在跨域时维持常数。本文采用了贝叶斯视角的因果理论进行归纳,并用这些理论在不同环境间来迁移知识。给定这些一般性理论,本文的目标是训练一个可和问题空间交互并探索的智能体来:(i)发现、构建并迁移有用的抽象结构化知识;(ii)从环境中观测到的实例级别属性中归纳出有用的知识。贝叶斯结构的层级被用于建模抽象层面的结构化因果知识,实例级别的相关性学习机制通过交互来学习哪种特定目标可以被用于归纳状态的改变。这种模型学习机制和一个基于模型的规划器结合来完成“开锁”环境中的任务,所谓的“开锁”环境是指一个虚拟的“逃脱空间”,空间内有复杂的层级,要求智能体对抽象、泛化的因果结构进行推理。本文和先前一系列上佳的无模型强化学习算法进行了比较。强化学习智能体在不同的尝试中显示出较差的可迁移知识的学习能力。但是本文提出的模型展现出趋近人类学习者的性能,更重要的是,展现出在不同的尝试和学习环境中展现出可迁移的行为。
2020年11月1日晚8点,因果科学与Causal AI读书会第六期——“潜结果框架下的因果效应估计”如期进行,浙江大学助理教授况琨作了精彩分享。
因果问题存在于很多领域,如医疗健康、经济、政治科学、数字营销等。比如一种新的药物是否比旧的药物更有疗效?一个新的策略是否能提升销量?一个新的政策会给民众、经济和社会带来多大的影响?所以这些问题都需要因果推理的技术来解决。
什么是因果,通俗来说,因果在生活中很普遍,“因”其实就是引起某种现象发生的原因,而“果”就是某种现象发生后产生的结果。但因果性却很难直接观测到,一般在观测中会得到事件之间的相关性,而在观察性研究中发展自动统计方法来推断因果效应是非常困难的。况琨提出了一些在现实的大数据场景中面临因果效应估计的一些挑战,包括(1)高维和噪声变量,(2)变量之间相互作用的未知模型结构,和(3)连续/复杂处理变量。为了应对这些挑战,他们提出了以下的算法:
Data-Driven Variable Decomposition (D2VD) algorithm;
Decomposed Representation Counterfactual Regression (DeR-CFR) model;
Differentiated Confounder Balancing (DCB) algorithm;
Generative Adversarial De-confounding (GAD) algorithm.
相比于当前已有的方法,他们提出的这些算法在观察性研究中可以对因果效应作出更精确和稳健的估计。了解更多详情:
https://mp.weixin.qq.com/s/Yx5wtwl8efBNQ_S-grKxbA
大数据时代的下一场变革——因果革命正在酝酿之中,通过融合因果推理和机器学习而构建出来的Causal AI系统,有望奠定强人工智能的基石。
集智俱乐部联合北京智源人工智能研究院,邀请了一批对因果科学与Causal AI感兴趣的研究者,开展为期2-3个月的系列线上读书会,研读经典和前沿论文,并尝试集体撰写一部书籍。如果你也从事相关的研究、应用工作,欢迎报名,参与读书会的讨论!
时间:9月20日起,每周日晚19:00-21:00,持续约2-3个月
模式:线上闭门读书会;收费-退款的保证金模式;读书会成员认领解读论文
了解读书会具体规则、报名读书会请点击下方文章:
目前读书会已经有超过130余人的海内外高校科研院所的一线科研工作者以及互联网一线从业人员参与,如果你也对这个主题感兴趣,就快加入我们吧!
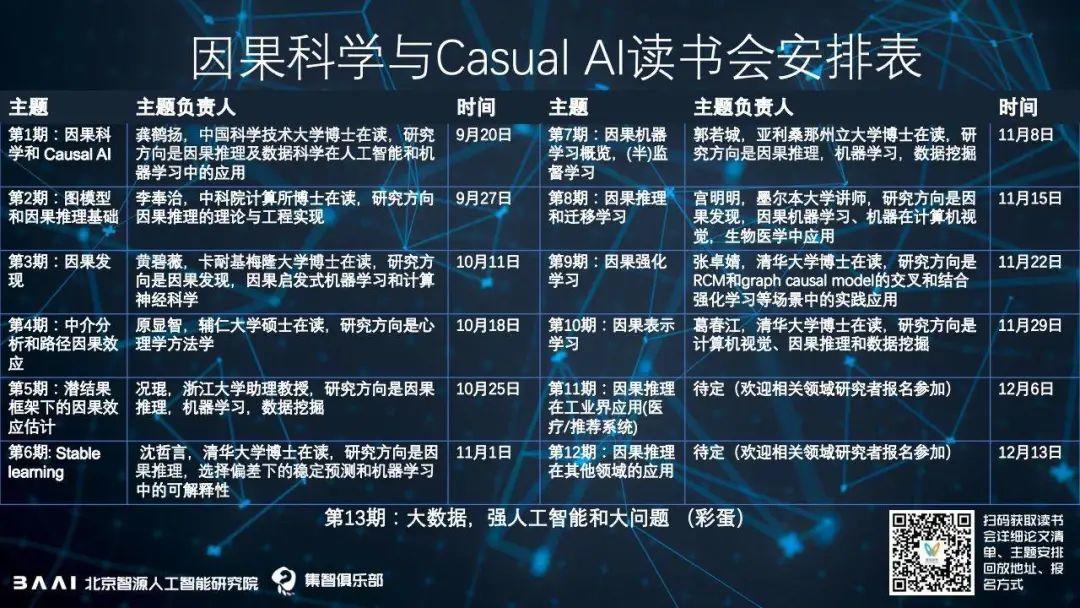
图注:针对读书会的主题,由发起人龚鹤扬设置好了内容框架,每个主题下有一个负责人来负责维护组织相关内容,目前已经定好的如图所示,欢迎对主题感兴趣的联系相关负责人,以及来认领相关主题。
因果科学社区简介:它是由集智俱乐部、智源社区共同推动,面向因果科学领域的垂直型学术讨论社区,目的是促进因果科学专业人士和兴趣爱好者们的交流和合作,推进因果科学学术、产业生态的建设和落地,孕育新一代因果科学领域的学术专家和产业创新者。

因果科学社区欢迎您加入!
因果科学社区愿景:回答因果问题是各个领域迫切的需求,当前许多不同领域(例如 AI 和统计学)都在使用因果推理,但是他们所使用的语言和模型各不相同,导致这些领域科学家之间沟通交流困难。因此我们希望构建一个社区,通过组织大量学术活动,使得科研人员能够掌握统计学的核心思想,熟练使用当前 AI 各种技术(例如 Pytorch/Pyro 搭建深度概率模型),促进各个领域的研究者交流和思维碰撞,从而让各个领域的因果推理有着共同的范式,甚至是共同的工程实践标准,推动刚刚成型的因果科学快速向前发展。具备因果推理能力的人类紧密协作创造了强大的文明,我们希望在未来社会中,因果推理融入到每个学科,尤其是紧密结合和提升 AI ,期待无数具备攀登因果之梯能力的 Agents (Causal AI) 和人类一起协作,共建下一代的人类文明!
如果您有适当的数学基础和人工智能研究经验,既有科学家的好奇心也有工程师思维,希望参与到“因果革命”中,教会机器因果思维,为因果科学作出贡献,请加入我们微信群:扫描下面社区小助手二维码加入(请备注“因果科学”)👇


集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!