互信息的“微积分”

导语
众所周知,Shannon的信息论在经典的通讯工程中起到了异常重要的作用。进入21世纪,信息论在复杂系统中的应用又有了长足的发展。其中,很多进展都是与互信息(Mutual Information)这一指标的细化和发展有着密切关系的。传统的观点认为,互信息刻画的是随机事件之间的非线性关联,而非线性往往是无法进行拆分的。然而,2010年的经典论文 “Nonnegative Decomposition of Multivariate Information”却找到了一个可以将复杂多变量体系的互信息进行原子化拆分的方式。这一拆分不仅能够精准地将多维度变量X对单一变量Y的互信息拆分为冗余、协同,以及独立信息,还能为我们理解复杂系统中的涌现特性以及因果特性提供深刻洞察,特别是,该理论可能为普遍存在于复杂系统分析中的重整化/粗粒化操作提供信息论方面的理论基础。
在「因果涌现读书会」第二季,北京师范大学系统科学学院在读博士张章解读了这篇论文,今天的文章是对该论文的深入解读。
研究领域:复杂系统,多变量相互作用,信息论

张章、张江 | 作者
梁金 | 审校
邓一雪 | 编辑

论文题目:
Nonnegative Decomposition of Multivariate Information
论文链接:
https://arxiv.org/abs/1004.2515
一、如何量化复杂系统中的相互作用?
一、如何量化复杂系统中的相互作用?
想象这样一个场景:我们收集到了很多人的身高、体重和性别的信息,现在让我们来训练一个神经网络模型来建模数据中的关系,以身高和体重作为输入,以性别作为输出。这是一个比较基础的机器学习场景。然而我们的问题是,能否在训练之前,就大概估计出每个变量的相对重要性?
理解这个问题的一个基本思维是,若特征之间存在非常复杂的相互作用,则我们需要很多的参数去拟合这种相互作用,否则,只需很少的参数对特征进行线性拟合即可。那么我们能否量化这种相互作用的复杂性呢?
让我们再来看一个场景:社会复杂系统的归因是一个困难的问题。一个典型的例子是,人们常常把萨拉热窝事件定义为一战的导火索,导火索是事情的直接起因,但我们知道真实的情况必然更复杂得多。那么我们能否有一种定量的方法去回答这样的问题:到底是某个事件单独促成了战争的爆发,还是多个事件共同促成了战争的爆发?
从某种视角来看,复杂系统可以看做存在相互作用的多变量系统。而信息论视角是理解变量之间相应关系的重要视角,因此人们发明并拓展了一系列方法,将信息论的思维应用到对复杂系统的理解上。例如,针对两个变量之间的相互作用,我们可以使用互信息(Mutual Information)来衡量当一个变量被观测后,另一个变量的不确定性(熵)的减少。但这种工具的适用场景相当有限,当变量数量增多,其相互作用机制变得复杂时,由于大量变量之间有可能存在协同效应(synergy),因此,我们除了计算原始变量之间的互信息,还要计算变量的两两组合,甚至更多组合之间的互信息。另一方面,在预测问题中,不同自变量之间有可能共享相似的信息,那么不同变量之间共享的这部分信息到底对预测起到了多大作用呢?
为了理解多变量相互作用情况下的信息结构,人们对互信息做了一系列拓展,发明了多种新的工具以分析复杂的相互作用,并试图将这些工具应用于对复杂系统的理解中。
本文将介绍多个源(source)变量作用于一个目标(target)变量时的一些信息分解工具,我们将从互信息出发,进一步讨论多变量情况下的互信息面临的困境,并引入信息的非负分解方法来更好地理解多对一情况下的信息结构。
二、互信息的局限性
二、互信息的局限性
信息论奠基人香农(Shannon)认为,“信息是用来消除随机不确定性的东西”。也就是说衡量信息量大小就看这个信息消除不确定性的程度。通过将信息与事件发生的概率结合在一起,香农率先对信息量进行了度量:即信息量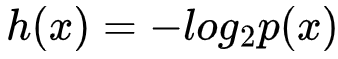 ,x 为随机变量 X 的一个可能取值,p(x) 表示 X 取值为 x 的概率,h(x) 代表 X 取值为 x 这一事件的信息量。进一步,香农提出了信息熵的概念来衡量一个随机变量可能产生的信息量的期望,即
,x 为随机变量 X 的一个可能取值,p(x) 表示 X 取值为 x 的概率,h(x) 代表 X 取值为 x 这一事件的信息量。进一步,香农提出了信息熵的概念来衡量一个随机变量可能产生的信息量的期望,即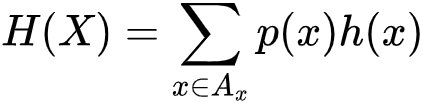 。我们也可以将信息熵理解为对事物的不确定性的度量:信息熵越大,事物越具有不确定性,信息熵的单位为 bit。
。我们也可以将信息熵理解为对事物的不确定性的度量:信息熵越大,事物越具有不确定性,信息熵的单位为 bit。
当两个变量之间存在相互作用时,我们可以通过观测其中一个变量来获知另外一个变量的部分信息,从而减少另一个变量的不确定性。所减少的不确定性大小可以用互信息来度量。例如,一个变量X原本服从这样的分布:X有0.5的概率取0,有0.5的概率取1。那么变量X的信息熵(不确定性)即为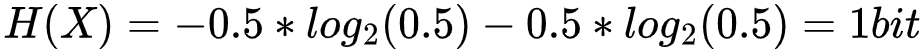 。此时假设存在变量Y,Y和X存在相互作用,例如Y=X,当我们观测到Y的取值为1时,X的分布就变成了以1的概率取1,此时X不再具有任何不确定性,其熵变为 0 bit。这减少的1 bit信息是通过观测Y得来的,因此我们称减少的1 bit信息为互信息。
。此时假设存在变量Y,Y和X存在相互作用,例如Y=X,当我们观测到Y的取值为1时,X的分布就变成了以1的概率取1,此时X不再具有任何不确定性,其熵变为 0 bit。这减少的1 bit信息是通过观测Y得来的,因此我们称减少的1 bit信息为互信息。
具体来说,互信息衡量的是通过观测Y能够给X减少的不确定性的大小。因此互信息的算法可以是用X原本的不确定性 H(X) 减去当Y被观测条件下的不确定性 H(X|Y)。使用这种思路,我们可以推导出互信息的计算公式为
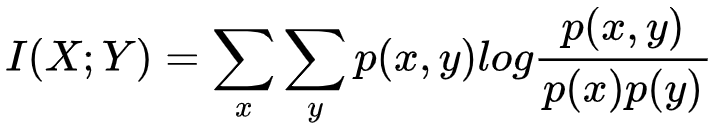

当相互作用的变量数量增多时,互信息的使用便会带来一定的问题,想象这样的场景:存在三个变量R1, R2, S,它们都以等概率取0或1,但彼此之间并不独立,其关系为:
R1=R2=S
如果我们观测到R1,便能够确定S的取值,这一过程可以被互信息描述为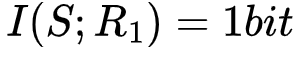 。但如果我们提前知道了R2的取值,那么在R1被观测之前就知道了S的取值,即S的不确定性已经降为0,此时观测R1已经不能S带来任何不确定性的降低。这种场景可以用条件互信息的语言来描述为
。但如果我们提前知道了R2的取值,那么在R1被观测之前就知道了S的取值,即S的不确定性已经降为0,此时观测R1已经不能S带来任何不确定性的降低。这种场景可以用条件互信息的语言来描述为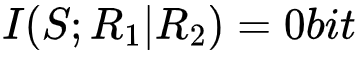 ,即在已知R2的条件下,R1的观测不能降低S的不确定性。在这一例子中,我们把R1和R2的位置互换,效果相同。
,即在已知R2的条件下,R1的观测不能降低S的不确定性。在这一例子中,我们把R1和R2的位置互换,效果相同。
再考虑这样一个场景,同样是R1, R2, S三个以等概率取0或1的变量,它们之间的关系为:
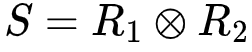 (异或)
(异或)
针对这一场景,在R2未知的情况下,通过观测R1,我们不能得到任何关于S的信息,即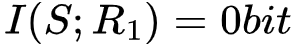 ,但如果R2已知,我们即可通过观测R1获得S的精确取值,即
,但如果R2已知,我们即可通过观测R1获得S的精确取值,即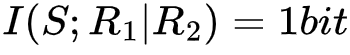 ,在这一例子中,我们把R1和R2的位置互换,效果相同。
,在这一例子中,我们把R1和R2的位置互换,效果相同。
在上述第一个例子中,R1=R2=S,我们单独观测R1或R2所获得的的信息量为1bit,在其中一个被观测后,再去观测另一个,就不再获得额外的信息量。此时我们可以说,R1和R2为S提供了一些冗余(redundant)信息。因为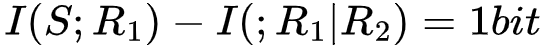 ,我们还可以知道它们提供的冗余信息量为1 bit。在上述第二个例子中,我们必须同时观测到R1和R2才能减少S的不确定性,此时我们可以说R1和R2为S提供了协同(syngernistic)信息。因为
,我们还可以知道它们提供的冗余信息量为1 bit。在上述第二个例子中,我们必须同时观测到R1和R2才能减少S的不确定性,此时我们可以说R1和R2为S提供了协同(syngernistic)信息。因为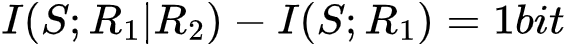 ,我们可以知道它们提供的协同信息量为1 bit。
,我们可以知道它们提供的协同信息量为1 bit。
但在所有情况下,冗余信息和协同信息都只能二者仅存其一吗?前文提到的冗余信息量的计算方法在更复杂的情况下仍然适用吗?在多变量作用于单变量的更复杂场景中,我们应该如何理解谁贡献了什么信息?这便是接下来要回答的问题。
三、多变量信息分解
三、多变量信息分解
1. 计算冗余信息
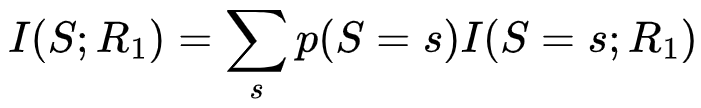
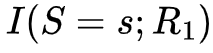 表示了观测R1对S取值为s这一事件的不确定性的减少,当然,观测R2同样可能减少S取值为s的不确定性,我们取以上两个不确定性的最小值,即1
表示了观测R1对S取值为s这一事件的不确定性的减少,当然,观测R2同样可能减少S取值为s的不确定性,我们取以上两个不确定性的最小值,即1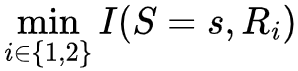 ,作为R1和R2关于S取s的冗余信息量。注意,这里指的是对S取值为s这一事件,R1和R2均可提供的信息量,因此这一信息量具有冗余的性质。进一步,冗余信息的期望可以被写成
,作为R1和R2关于S取s的冗余信息量。注意,这里指的是对S取值为s这一事件,R1和R2均可提供的信息量,因此这一信息量具有冗余的性质。进一步,冗余信息的期望可以被写成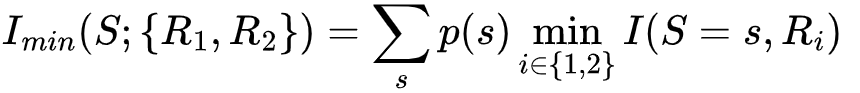
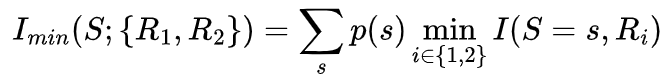
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
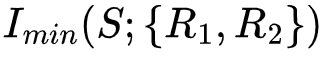 可知,其计算结果也为1 bit,可见我们的直观分析是正确的。
可知,其计算结果也为1 bit,可见我们的直观分析是正确的。冗余信息有如下三条重要的性质:
-
首先,冗余信息Imin应该是非负的,可以想象,如果任何源变量对目标变量的任何一个可能取值都无法贡献出公共信息,那么冗余信息即为0。 -
其次,冗余信息应该小于或等于任何一个源变量关于目标变量的互信息,我们可以从冗余信息的计算公式中分析出此性质:观察其计算公式  ,若针对S=s的每一个取值,A0都比其他Ai提供了更少的信息,则此时 Imin(S;a)=Imin(S;A0)。
,若针对S=s的每一个取值,A0都比其他Ai提供了更少的信息,则此时 Imin(S;a)=Imin(S;A0)。 -
另外,虽然我们通常定义冗余信息为多个源变量对目标变量提供的共同信息,但如果只有一个源变量,根据前述公式,我们仍然可以定义这个源变量为目标变量提供的冗余信息,实际上,经过计算,我们可以发现,这种冗余信息大小即为源变量和目标变量的互信息,即I{min}(S; {A1}) = I(S; A1)。
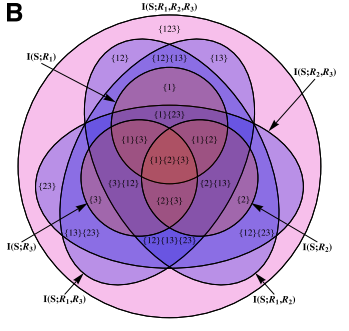
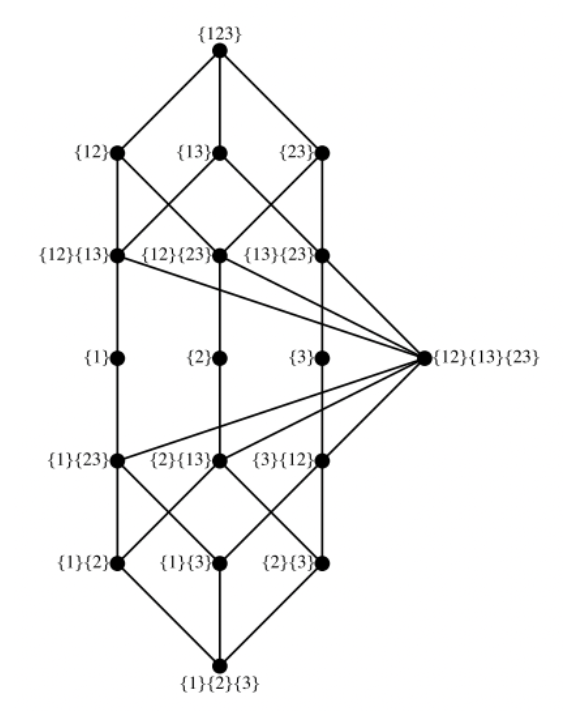
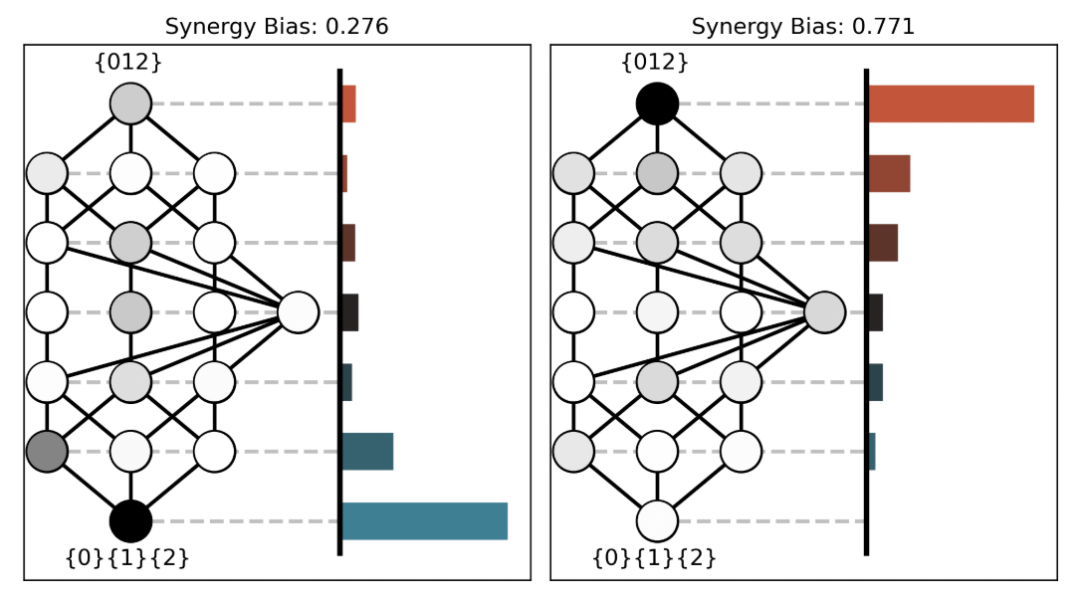
3. 冗余信息的结构
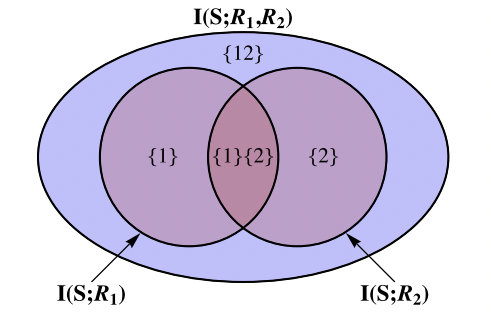
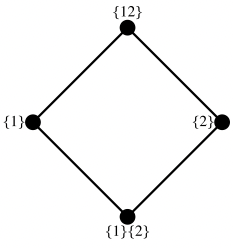
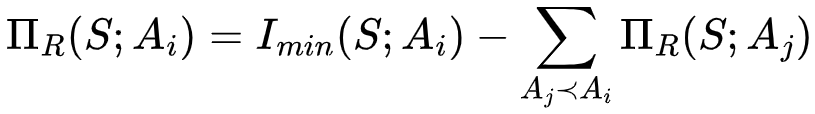
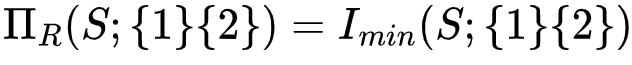 。而中间层的节点{1}的信息分解结果为该节点为目标节点提供的冗余信息量(即该节点和目标节点之间的互信息)减去底层节点的信息分解结果的值,即
。而中间层的节点{1}的信息分解结果为该节点为目标节点提供的冗余信息量(即该节点和目标节点之间的互信息)减去底层节点的信息分解结果的值,即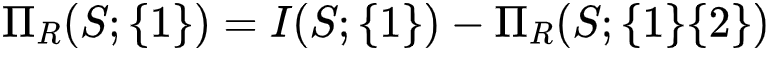 。这一部分信息量由节点{1}单独提供,而不包括节点{1}和节点{2}提供的公共信息,因此我们将这一部分信息称之为单独(Unique)信息。
。这一部分信息量由节点{1}单独提供,而不包括节点{1}和节点{2}提供的公共信息,因此我们将这一部分信息称之为单独(Unique)信息。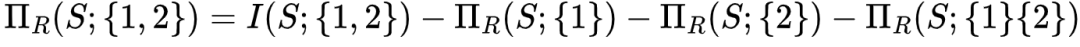 ,这表示仅有该节点,而非任何其余三个下层节点提供的冗余信息,具体来说,这也表示了通过联合观测节点{1}和{2}才能得到的信息,而非单独观测任何一个能得到,而观测另一个得不到的信息,也非节点{1}和{2}都可以为目标变量提供的信息。因此我们将这一信息称之为协同(Synergistic)信息。
,这表示仅有该节点,而非任何其余三个下层节点提供的冗余信息,具体来说,这也表示了通过联合观测节点{1}和{2}才能得到的信息,而非单独观测任何一个能得到,而观测另一个得不到的信息,也非节点{1}和{2}都可以为目标变量提供的信息。因此我们将这一信息称之为协同(Synergistic)信息。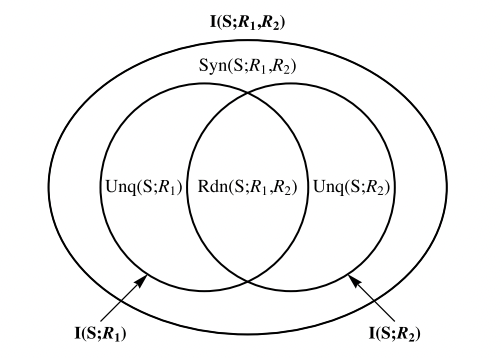
四、应用
四、应用
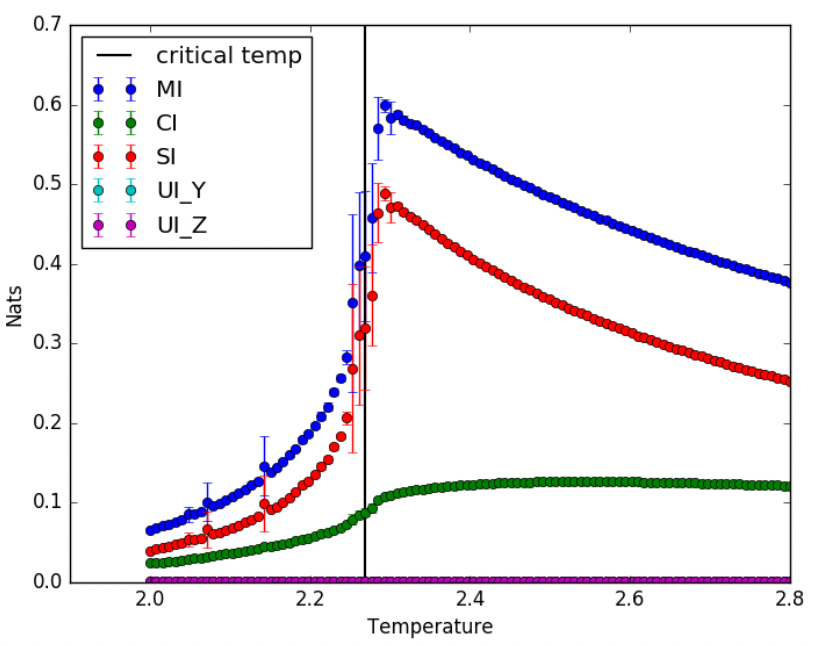
1. 信息分解方法在 Ising Model 中的应用
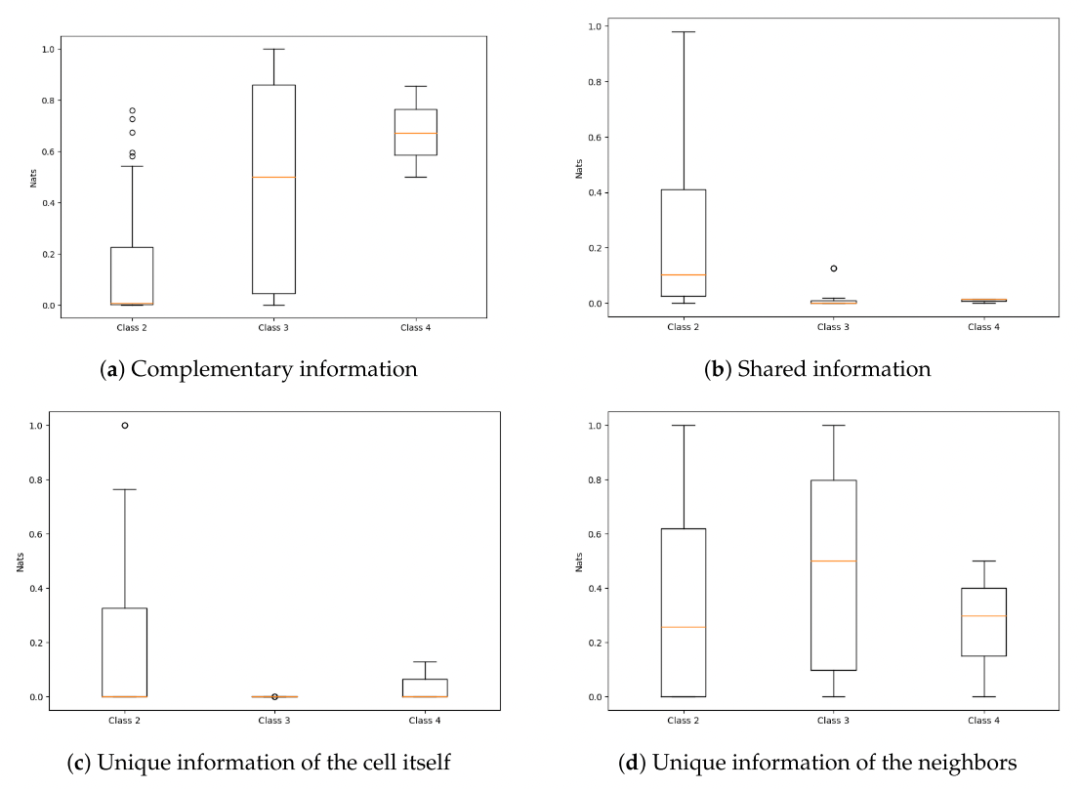
2. 信息分解方法在元胞自动机中的应用
-
元胞自动机很快演化为纯黑或纯白
-
元胞自动机演化出周期性的、可重复的模式
-
元胞自动机演化出混沌
-
元胞自动机演化可以长时间存在的复杂斑图

3. 信息分解方法在因果涌现中的应用
五、总结
五、总结
通过这篇文章,我们介绍了一种信息分解方法,该方法可以帮助我们清晰表述在多个源变量作用于一个目标变量的情况下的信息结构,可以回答一系列具体的问题,例如“谁为结果提供了多少信息?”,“它们为结果提供的信息中,有多少是互相冗余的?”,“有多少信息需要协同考虑多个变量才可以获得?”等等。我们首先定义了冗余信息(Redundant Information),然后通过分析冗余信息的性质,发现冗余信息天然存在着一种结构,进一步通过对冗余信息的分解,我们获得了单独信息(Unique Information)和协同信息(Synergistic Information)的定义和计算方法,从而帮助我们更好地理解了这一信息结构。
这篇文章的价值在于,它从某种程度上揭开了我们似乎已经很熟悉的“互信息”的神秘面纱,发明了一种类似“互信息的微积分”的方法,详细拆解了互信息的每一个元素应该如何理解和计算。这篇文章自发表以来便引起了科学家们的巨大兴趣,人们沿着这篇文章的方向进行了诸多探索,这些探索包括定义一些新的冗余信息计算方法,更深入地研究信息结构的性质,以及信息分解方法在不同领域中的应用等等。另一个有趣的现象是,这篇文章一直挂在arXiv上,从2010年至今也并未能正式发表,成为了一个另一个典型的无需杂志认可的经典文章案例。
我们还进一步介绍了这一方法在多种复杂系统中的应用,如Ising Model和元胞自动机这类已经被研究人员广泛研究的系统。我们也初步介绍了信息分解方法在因果涌现中的应用。
从信息流动的视角理解复杂系统,无疑可以增进我们对复杂性本质的理解。但本文所介绍的方法仍有一定的局限,例如,本文所介绍的方法只能适用于多变量作用于单变量的情况,但在一个复杂系统中,多变量之间存在着相互影响。又如,本文所介绍的方法计算复杂度非常高,导致该方法很难应用于源变量很多的情况,我们在「因果涌现读书会」第二季第二期解读了这篇文章,后面我们还会解读一些基于这篇文章开展的其他进展,这些进展在某种程度上克服了本文的缺点,为我们理解复杂系统提供了更多的工具,欢迎大家加入此次读书会,与我们共同讨论。
因果涌现读书会第二季招募中

本季读书会详情与报名方式请参考:
推荐阅读
-
Nature Phycics:信息论方法描述高阶相互作用 -
PRL:互信息帮助分离环境噪声与系统内部相互作用 -
量化涌现:信息论方法识别多变量数据中的因果涌现 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











