分析与建模方法在计算社会科学研究中的应用 | 圆桌论坛回顾

导语
人类的许多行为和现象,比如信息在人群中的传播,对彼此行为的模仿和学习,都不是静态独立的,其背后往往有复杂的动力学机制。计算社会科学研究者通过建模和仿真方法(simulation),提出了多种不同的计算模型来解释产生这些现象的机制和可能的影响因素。这类研究的关注重点是现象的成因、形成过程,并且通过提出的模型和机制对未来现象的发展给出预测,同时给出可能的干预方案。
在集智俱乐部「计算社会科学读书会圆桌论坛」中,张子柯、殷裔安、黄俊铭、靳擎四位研究者通过分享四个计算社会科学的前沿研究,讲解计算分析与建模方法在计算社会科学研究中的应用,并进一步探讨了社会科学建模、计算机建模和物理学建模的联系与差别,以及如何跨越传统学科边界,引入不同的研究范式,促进学科之间的融合。本文是此次论坛的整理。
研究领域:计算社会科学,计算机建模

张子柯、殷裔安、黄俊铭、靳擎 | 讲者
吴柳洁 | 整理
梁金、邓一雪 | 编辑
一、建模方法应用于社会科学的背景
一、建模方法应用于社会科学的背景
随着社会实际问题复杂性的不断提高、认识世界和改造世界实践的发展, 在面对新问题的出现,解决新问题的过程中, 研究者不断地对自己的思维方式进行反思, 在学科交叉融合的推动下,社会科学领域的计算建模方法应运而生,不仅提供了来自其他学科的有关动态演化、宏微观层次相互作用、复杂系统自组织等思考维度和研究范式,更是和传统方法相结合,形成更为综合和深刻的方法论。
二、不同社科主题下建模方法的应用
二、不同社科主题下建模方法的应用
报告一:基于高阶演化网络的学科发展研究 (张子柯)

学科发展一直是计算社会科学的重要研究方向。基于学科发展的研究目标,主要有学科发展的规律、人才培养路线图、知识体系的构建、研究方向的锚定等。研究学科发展的方法有很多,本次报告从中国和国际相关学科数据出发,以高阶演化网络为工具和方法,理解学科发展过程中的人才培养困境和对策问题。
在2013年的论文“基于超图结构的科研合作网络演化模型”中,张子柯与其合作者们以研究者为点,合作关系为超边完成高阶网络构建算法。不同的论文中, 可能有相同的作者, 即不同超边之间通过公共的顶点邻接。因此多篇科研论文根据相同的作者就会构成一个作论文合作关系的超网络。如图1所示,可以看到作者的分布大概为“倒V形“分布,获取其超度分布等参数代入微分方程并简化,确认其动力学过程,发现合作者人数的分布服从指数分布。
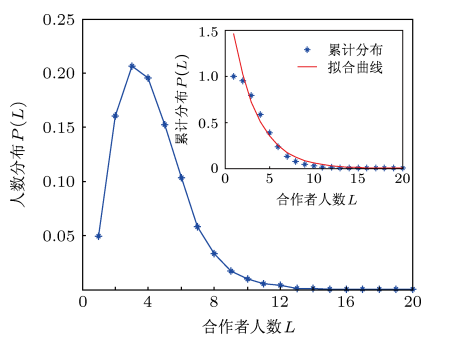
图1 论文中合作者人数分布图
论文题目:基于超图结构的科研合作网络演化模型
论文地址:https://wulixb.iphy.ac.cn/article/id/56181
依据前文模型构建算法, 用蒙特卡洛数值模拟方法生成论文中作者数量和连接的旧作者数量,反复生成时间序列, 逐步构建科研合作超网络演化模型, 用计算机模拟随时间变化的作者发表论文数的分布特性;进而进行了仿真解和真实解的比较,发现理论解在仿真解的边界上,证明了模型的合理性。
理论分析得到了研究者发表论文数量(超度)增长指数的拟合公式:
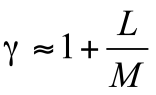
其中,L代表t时刻添加的一篇论文中有L个作者,M表示t时刻添加的一篇论文L个作者中有M个是已知合作网络中的作者;对于模型本身而言,L/M是一个序参量,说明节点的超度分布和很多复杂网络模型的度分布一样符合幂律分布,具有无标度性,即符合Hipps定律的指数增长关系。
结果表明,分布指数大小与领域的作者增长率相关,指数越大,则领域内新发表论文中新作者的比例越大,该学科越兴旺。
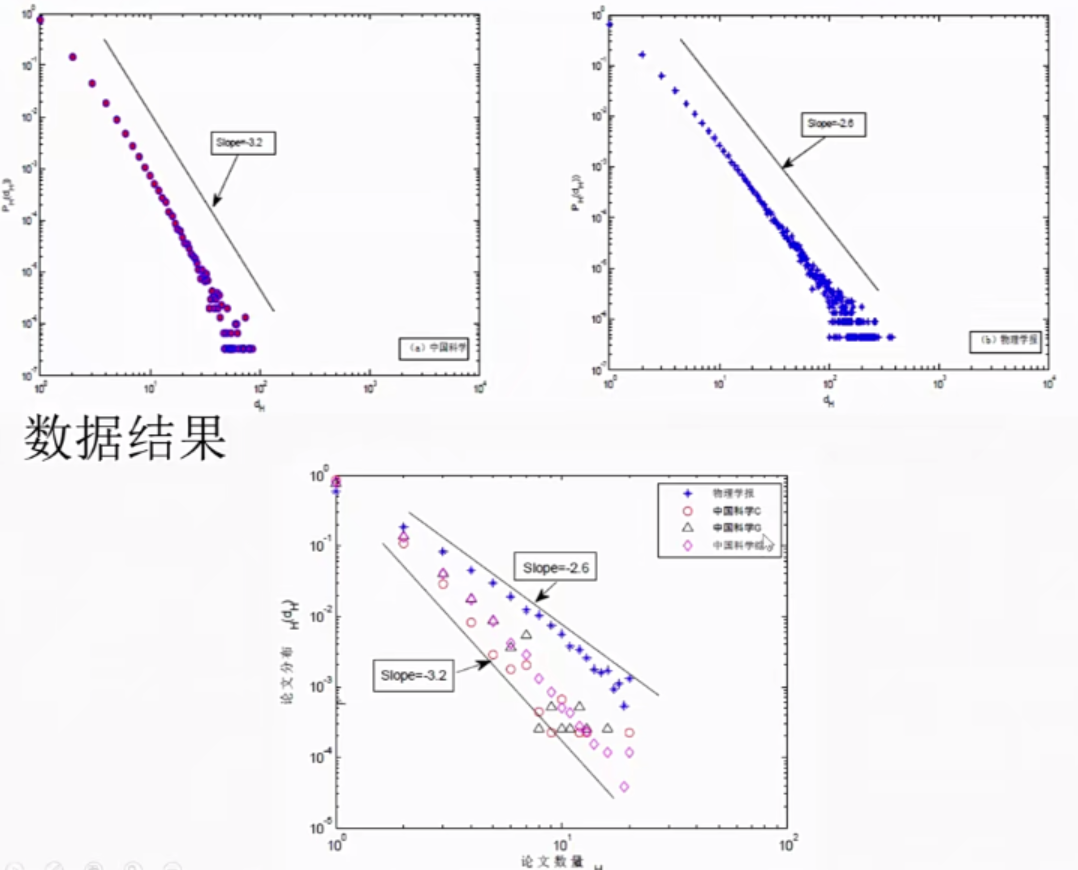
类似合作关系,张子柯及其合作者们利用2021年美国物理学会(APS,1893-2009,共有463,442篇论文发表,4708,753次引用)和数字书目与图书馆项目(DBLP,1954-2013,共有564,705篇论文发表,4191,677次引用)文献数据库,完成了文章为点、引用关系为超边的基于超图演化的引文网络,突破了以往研究中将引用和被引关系作为双向关系考虑的局限性,将出版物及其所有参考文献作为一个整体,并进行了模型的理论近似解和仿真分析。
论文题目:The aging effect in evolving scientific citation networks
论文地址:https://link.springer.com/article/10.1007/s11192-021-03929-8
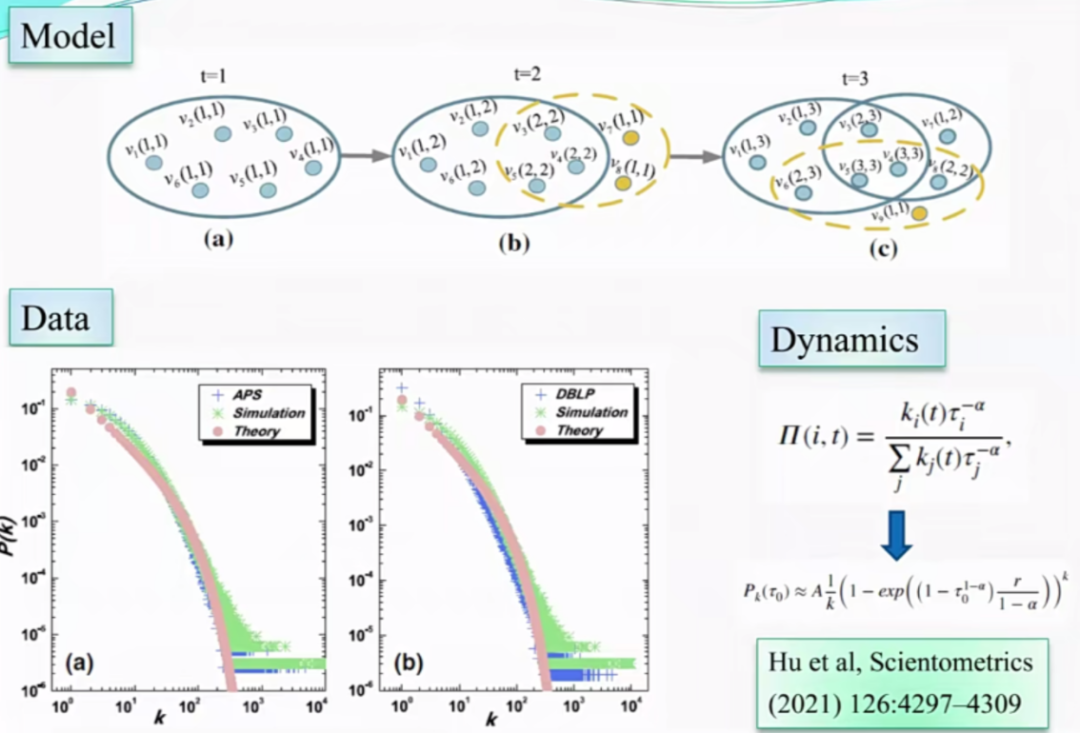
图4 模型示意图与分布/拟合曲线
研究计算了学科吸引力变化的参数,发现学科吸引力的分布都呈现指数级下降,早期出版物的衰退老化速度近似于指数形式。对于短期观测,虽然权威论文可能会主导一个领域,但新的发现仍然可以引起科学界的关注;而在较长的时间尺度上,无论论文有多么出色,对于物理和计算机学科,具体文章的吸引力,即引文分布均会随着时间推移发生变化——新的优秀出版物终将逐渐覆盖旧的出版物。
报告二:量化科学、创业、安全中的失败动力学 (殷裔安)

人类的成就大多始于屡次的失败,但当前鲜少有研究挖掘失败动力学背后的机制。在过去数十年里,计算社会科学里有一个非常活跃的领域,是通过数据模型等量化的方式去研究一些成功现象及其机制,这启发研究者借鉴对成功现象的解读,去理解失败是怎样的过程或现象,并利用失败的动态变化,判断个体是否可以通往成功。
殷裔安等人发表于 Nature 的研究利用具有不同特征的NIH基金申请数据、创业公司数据(VentureXpert)、恐怖主义数据库(Global Terrorism Database),尝试建立一个通用的理论,了解失败到成功过程的普遍性过程和特征。
论文题目:Quantifying dynamics of failure across science, startups, and security
论文地址:https://www.nature.com/articles/s41586-019-1725-y
首先,研究者建立了一个单变量模型入手研究失败的动力学机制。
所有的过程都可以简化成若干次尝试。常说的“失败是成功之母”,一是每一次失败会给予一部分有用的信息,具体来说,每一次尝试都可以拆分成很多不同的部分;二是每次尝试之后也会得到一个来自外界的反馈,指出各个部分完成的优劣。在进行下一次尝试时,个体不再是白手起家,而是借用了自己以前做的很好的部分(experience),并且接受了来自别人的评价(evaluation),对以往尝试中的组成部分进行取舍和优化。
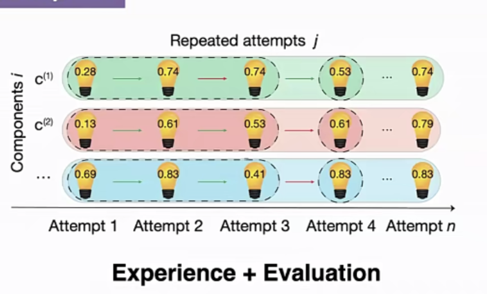
图5 每一次尝试都可以看作不同构成部分的组合
结合了这两种机制后即为k模型,其中k表示多少过去次失败的经验放入到下一次尝试中。k=0表示过去失败的经验一次都没有放入下一次尝试,k比较大时则为从过去的失败活动中吸取到了很多经验。当给定过去的经验时,人们可以进行很多不同的选项,比如多花一点时间尝试新的版本,这时尝试的分数相应地具有随机性;也可以从过去的经验中直接借鉴某部分,节省了一些时间,成绩则与过去具有相似性。
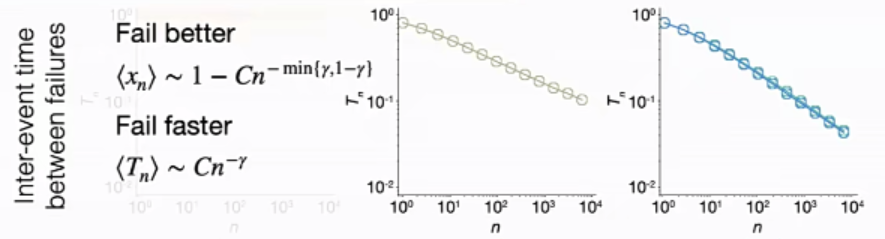
k这样一个简单的参数,可以预测出很多有意思的现象。如k=0时没有任何学习的过程,每次尝试的成绩也没有显著的变化,最终的成功只取决于运气(chance);另一个极限k=∞,过去每一次的经验都加以考虑,当失败越来越多时,通过学习(learning)累积的经验也越来越多,成绩也越来越向更高的水平靠近,两次失败间隔的时间也越来越短,平均间隔时间和失败次数呈现出幂律分布特征。
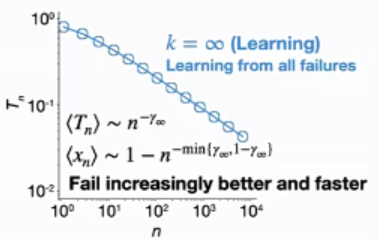
图6 失败次数越多,两次尝试之间的间隔时间越短
在k=0与k=∞这两个极端之间,其表现并不是一个连续的过程。这中间存在着一个临界点(图7),或者说相变点k*,k*以下基本和没学(k=0)没什么区别(图8),而在k*以上和什么都学了(k=∞)非常相像(图9)。K*左右存在着非常不连续的表现变化。
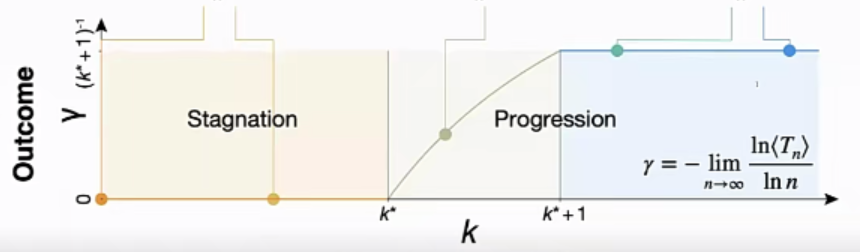
图7 学习水平与最终表现的关系间,存在相变点

报告三:学术界性别不平等的历史比较(黄俊铭)

性别不平等问题在科学学领域的研究由来已久,女性科学家在各个方面所受到的待遇普遍不如男性科学家,这样的因素促使科学家去研究学术界的性别不平等问题究竟到了什么样的程度,以及导致性别不平等现象的因素。
论文题目:Historical comparison of gender inequality in scientific careers across countries and disciplines
论文地址:https://www.pnas.org/content/early/2020/02/14/1914221117
在2020年发表于PNAS的研究中,黄俊铭等利用 Web of Science 全量文献数据,覆盖了1900-2016发表的全部期刊,筛选后留存了5500万篇文献,9800万名作者的职业生涯,使用名字的推断算法判断其性别。首先男性科学家的人数要远远多于女性科学家,所以简单地比较男女性科学家的学术表现是不公平的。

其次每个国家不同学科的科学家的性别比例也存在着普遍的不均等现象,并且这样的现象也是不均等的:某些国家的某些学科男女数量差异巨大,而在另一些国家人数接近均等。
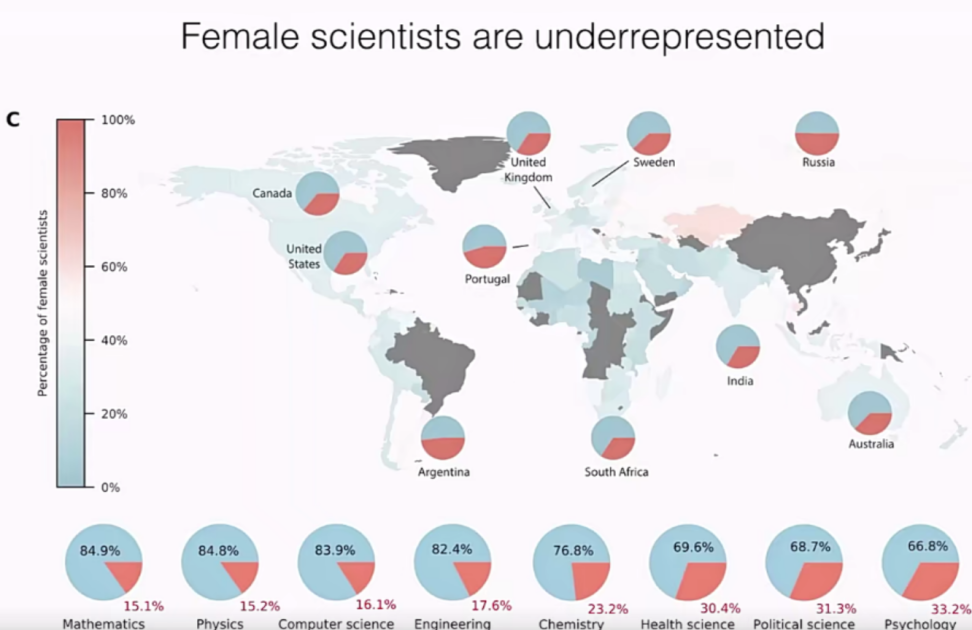
图11 分国家、学科发表论文研究者性别比例
这两个现象的存在促使研究者从个体的层面去研究性别不平等问题,即一个男性科学家和一个女性科学家,他们的研究成果有什么差异。PNAS的这项研究使用个体职业生涯中的发表总数和引用总数指标来表明个体获得的科研群体认同度。
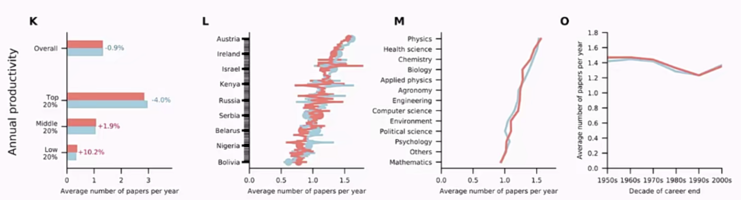
统计结果表明,男性科学家在职业生涯中发表论文总数(平均12篇)显著高于女性科学家(平均9篇),这样的现象在控制了国家、学科、学校排名、年代等因素后仍然显著存在。在对发表论文数进行分组后发现,只有在top20%的组别里,男女性差异最为明显,其他组里这一数量是差不多的,即学术界的性别不平等主要发生在头部科学家。引用情况在修正后情况类似。

数据确认,单个男性科学家获得的总学术成就高于女性科学家,可是要如何解释这样的现象为何会发生?首先,文章利用数据证明了“女性在理工科的天赋比男性低”这一刻板印象的错误性;其次,利用年平均发表论文数、年平均引用数,在不同国家、不同学科和不同年代均发现,男女性科学家在这一方面相差无几。
黄俊铭等结合男女两性在平均职业生涯长度上的显著差异,进而假设:真正导致男女科学家学术表现性别差异的原因,是其职业生涯长度。男性科学家的优势仅仅体现在他们会在学术界待更长的时间,是否是职业长度的差异才决定了学术成就上的差异?
结合数据可以发现,在职业生涯长度性别差异较大的学科和国家,单个科学家职业生涯中发表论文的数量也存在较大差异;而在职业生涯长度性别差异较小的学科和国家,发表论文数量的性别差异也比较小。为了验证这个假设,黄俊铭等从数据集中人工构造了两个匹配样本,使得每一对个体在国家、学科和职业生涯长度上完全类似。

图14 匹配样本案例
构成这样的同分布匹配样本后,可以发现学术成就上的性别差异大大降低,虽然并没有完全消失,即职业生涯长度的变量很大程度上可以解释学术成就上的性别差异,即女性职业生涯长度受其较高的退出率的限制。
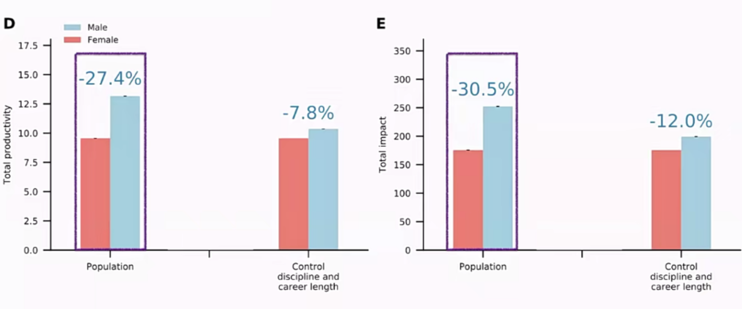
图15 单因素分析:职业生涯长度的差异可以大部分地解释在学术表现上的性别差异
报告四:复杂演替系统的增长动力学研究 (靳擎)

大量的扩散现象来源于事物的更迭与演替。尽管“演替现象”非常普遍,科学界过去对于它的认知非常有限,主要原因是缺乏相关的大规模数据。由于数据的不可及性,以往研究对增长曲线的描述并不精细,尤其是最为重要的新产品的早期增长阶段。各种模型早期的猜测模仿传染病模型,假设创新的扩散是一个乘数增长,增长到一定程度后逐渐趋缓。
靳擎等(2019)利用真实数据——360万人在10年中的手机使用数据,精确到每天的使用,发现销售数据和扩散数据均非指数级增长,而是幂律增长,其指数具体数值分布在0-3区间内。当指数取非整数时,曲线在t=0发散,意味着早期增长非常快,后期增长又比一般的指数增长要慢。
论文题目:Emergence of scaling in complex substitutive systems
论文地址:https://www.nature.com/articles/s41562-019-0638-y
为了证明这样早期增长规律的普遍意义,靳擎及其合作者们采集了另外三个数据集,一是北美地区6年、超过百种汽车的销售状况,二是近千种手机app的下载数据,三是20万科学家研究过的近七千个科学领域中人数的增长进行佐证。利用这四种在使用周期、成本等方面各不相同的数据集,发现其均满足幂律增长模式,均与传统增长模型的指数增长假设不同。这激发了研究者们探索“增长”这一现象更底层机制的好奇。
研究者通过观察发现,人们不是单纯地去购买一个新产品,而是用新产品去替换旧产品。每年新手机引入市场的量是一个恒定值,总有不停地有新手机进入系统,让每一款手机的使用量出现起伏过程。
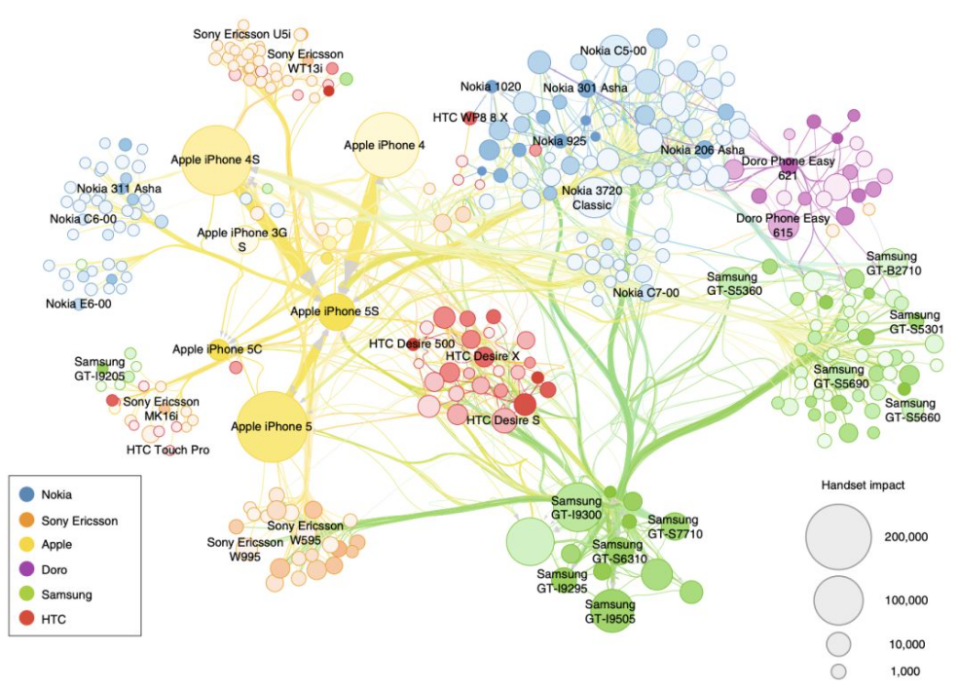
计算模型可以用来模拟这样一个起伏的过程:一种手机i的增减由两个因素决定,一是从别的手机转向使用手机i的概率,二是从手机i转向别的手机的概率。
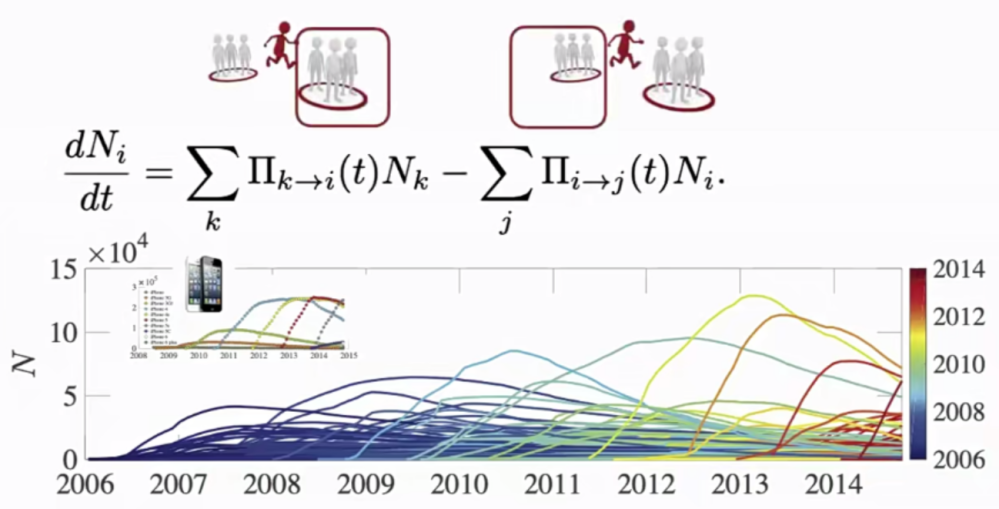
图17 特定产品使用量变化的微分关系式
-
优先链接 (preferential attachment):一个流行、成功的产品更有可能获得更多的新用户,会出现“强者更强”现象。 -
时效性(recency):一个事物越新,“年龄”越小,就越能吸引更多的人。研究者发现,影响力和事物的年龄恰好成反比。 -
内在倾向性(propensity):表示的则是一个新事物对既有的旧事物的替代能力有多强。这种倾向性根植在产品的特性里,与产品的功能、品牌及厂商有比较紧密的联系。
-
期望(anticipation,h):这确定了最初的潜在消费者有多少,第一天可以卖出去多少; -
替换能力(fitness,η):新的产品和用户手中的老产品的契合程度,更换产品的迁移难度,即早期的增长率; -
生命周期(longevity,τ):产品的生存寿命,以及多久会过时,表现了产品最终衰退的速度。
如果系统是封闭稳定的,即新产品匀速进入系统,每个手机的替换能力(fitness)和生命周期(longevity)都是一个其特有的常数。从而使用数量增长方程可以转换为一个简单的、可解的常微分方程。
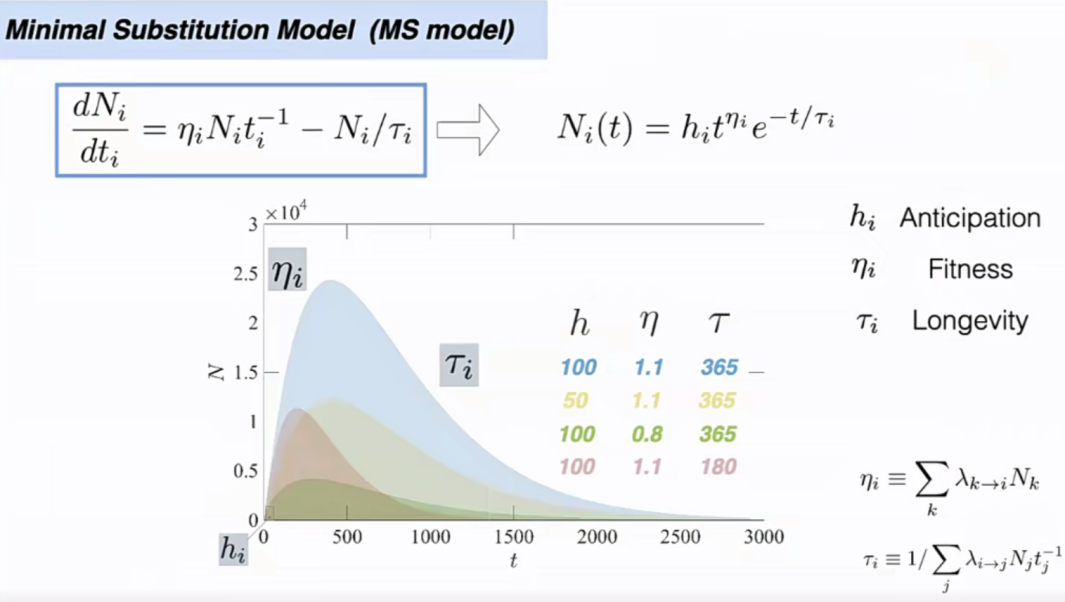
图18 增长变化中的演替关系模拟图
某款手机与其他手机的相似关系决定了其一开始的增长速率;而整体的增长曲线则由三个参数共同决定。模型也预测了所有数据集中销量的增长曲线,并全部可以拟合成一条线,证明了方程的普适性。
三、学科差异背景下方法论的迁移
三、学科差异背景下方法论的迁移
学科的差异性
很多人认为,计算社会科学是社会科学、计算机科学和物理学的交叉领域。那么社会科学建模、计算机建模和物理学建模的差别主要在哪里?什么样的数据结构更适合这三种不同的建模?
黄俊铭博士根据自身在三个学科均涉足过的经历,认为计算机建模主要强调精确,希望可以得到一个很清晰的拟合的结果,在计算机领域鼓励用一个很复杂的模型建模复杂过程。
物理和社会科学更强调模型的简洁,尽可能的简化和被人所理解,物理学、统计力学中的经验公式,过程中的中间状态,最终仍然需要一个比较能够解释、能够自圆其说的模型。例如信息检索中的tf-idf模型,最初提出的时候使用文档频率倒数 idf 来度量词的特异性,后来人们发现 log(idf) 的实际效果优于 idf。此处 tf*log(idf) 可以理解为信息熵,有实际的物理意义。
社会科学可能要求比物理学更简单一些,一方面需要被人所理解,需要具有实际意义,不需要百分之百拟合;另一方面社会科学使用的数据维度和样本量都比较小,故而对于过拟合更为谨慎,这也是社会科学很多公式都非常简单的原因。
靳擎博士提醒大家,在谈论三种学科建模的差异之前,可以先思考我们为什么要建模。模型的目标有三类不同面向:解释力、描述力和预测力。在真实处理中,这三个目标往往不能兼得,所以产生了不同的学派。比如计算机对预测力的要求非常高,目标就是预测成功率的提升,确实在实际落地中也非常有用。物理学的模型在关心预测力之外,更加规避参数的冗余性,用尽可能少的参数去描述系统(奥卡姆剃刀)。社会科学更加注重模型的解释力这一方面,希望模型可以去准确地解释现象发生的原因。
因为这三种学科建模都有自己的侧重点,也都存在自己的偏向。社会科学有时着重关注一两个变量之间的关系,不太关注整体的预测力。物理学虽然把每一个参数回归到具体的物理意义,但其解释力没有到达底层,同时其预测力上也未必达到计算机领域中的精确。但是物理学模型往往可以作为计算机和社会科学领域模型的桥梁,模型参数可以用社会科学的理论进行某种解释,而模型细节部分可以在计算机方法加工下做更精细的预测;其研究周期非常长,且对数据精度的要求非常高。计算机模型最大的问题在于,为了短时间的预测而牺牲了对底层机制的挖掘,进而可能丧失长期的预测力。
殷裔安博士提出,一方面,学科之间的交叉融合是广泛存在的,并没有一个非常明显的界限。另一方面,无论是计算科学还是社会科学研究,其内部本身也都有着很丰富的方法,用来处理从微观的个体特征到宏观的社会结构等不同层次的问题。比如社会学、经济学中的一些范式和物理学在某种程度是相通的,从结构和交互的角度去解释人的关注和行为;而心理学与计算科学也有很多的合作,比如通过社交媒体行为去预测个体的属性和线下行为等等。
张子柯博士同样强调在关注的层面上,可以跨过常说的一级二级学科的分界线,广泛交流合作,从而碰撞出不一样的思考。学科之间交流融合,引入不同的研究范式,才具有突破传统研究方法的重要意义。
方法论的迁移
在几位研究者的工作里,我们经常看见同一套方法论和假设应用在不同的数据集或问题上。当同一套方法论应用在不同问题上的时候,老师们认为,不同项目之间最具有可迁移性的东西是方法和研究范式,而模型本身是最不具有迁移性的。
计算社会科学读书会第二季
课程推荐
课程推荐
集智学园 Python 爬虫课
大数据时代,爬虫是一个重要的基本技能。想要学会爬虫,需要具有一个完整的技术体系,并动手实践。为了帮助学生真正学会爬虫,集智学园联合西安交通大学应用数学博士、现为南京审计大学讲师的卢燚老师,精心设计了一个 8 小时系列爬虫课程,用简短的代码、精短的课时,讲解 3 种 Python 爬虫的基本方法,给你一个较为完整的爬虫技术体系。课程总计 8 节,从 10 月 10 日开始,每周 2 节。欢迎苦于数据获取、希望拥有爬虫技能的你,加入课程!

详情请见:
推荐阅读
-
如何量化语言亲密度?自然语言处理在计算社会科学中的应用 -
Nature特刊:计算社会科学研究的数据百宝箱 -
Nature计算社会科学特刊:如何对21世纪人类社会进行有意义的度量? -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











