在过去的十年里,我们见证了深度学习的崛起,逐渐在人工智能领域占据主导地位。人工神经网络以及具有大内存的硬件加速器的进步,加上大型数据集的可用性,使得从业者能够训练和部署复杂的神经网络模型,并在跨越计算机视觉、自然语言处理和强化学习等多个领域的任务上取得最先进的性能。然而,随着这些神经网络变得更大、更复杂、应用更广泛,深度学习模型的基本问题变得更加明显。众所周知,最先进的深度学习模型存在各种问题,包括稳健性差、无法适应新的任务设置,以及需要严格和不灵活的配置假设。通常在自然界观察到的集体行为,往往会产生稳健、适应性强、对环境配置的假设不那么严格的系统。集体智能(Collective Intelligence)作为一个领域,研究的是从许多个体的互动中涌现的群体智能(Group Intelligence)。在这个领域中,诸如自组织、涌现行为、群优化和元胞自动机等思想被开发出来,以模拟和解释复杂系统。因此,研究者很自然地会将这些想法融入到较新的深度学习方法中。在这篇综述中,作者将提供一个涉及复杂系统的神经网络研究历史背景,并强调现代深度学习研究中几个活跃的领域,这些领域结合了集体智能的原则来提高其能力。我们希望这篇评论可以作为复杂系统和深度学习社区之间的桥梁。
David Ha, Yujin Tang | 作者
刘志航 | 翻译
刘培源 | 审校
邓一雪 | 编辑
论文题目:Collective intelligence for deep learning: A survey of recent developments
论文链接:https://dl.acm.org/doi/10.1177/26339137221114874
1. 引言
2. 背景:集体智能
3. 历史背景:细胞式类神经网络
4. 深度学习的集体智能
5. 讨论
深度学习(Deep learning)是一类机器学习方法,使用多层(“深度”)神经网络进行表征学习。虽然用反向传播算法训练的人工神经网络最早已经在20世纪80年代出现(Schmidhuber, 2014),但深度神经网络直到2012年才受到广泛关注,当时在GPU上训练的深度人工神经网络解决方案(Krizhevsky et al. 2012)在年度图像识别比赛(Deng et al. 2009)中以明显优势战胜非深度学习的方法。这一成功表明,当深度学习和硬件加速以及大型数据集的可用性相结合时,能够在非琐碎的任务中取得比传统方法更好的结果。实践者们很快就将深度学习纳入到其他领域,以解决长期存在的问题。在计算机视觉(CV)中,深度学习模型被用于图像识别(Simonyan and Zisserman, 2014; He et al. 2016; Radford et al. 2021)和图像生成(Wang et al. 2021; Jabbar et al. 2021)。在自然语言处理(NLP)中,深度语言模型可以生成文本(Radford et al. 2018,2019; Brown et al. 2020)并进行机器翻译(Stahlberg,2020)。深度学习也被纳入到强化学习(RL)中,以解决基于视觉的计算机游戏,如Doom(Ha and Schmidhuber, 2018)和Atari(Mnih et al. 2015),以及具有大型搜索空间的游戏,如围棋(Silver et al. 2016)和星际争霸(Vinyals et al. 2019)。深度学习模型也被部署在移动应用中,如语音识别(Alam et al. 2020)和语音合成(Tan et al. 2021),显示出其广泛的适用性。
然而,深度学习并不是没有副作用的灵丹妙药。虽然我们见证了许多成功的案例,并且越来越多地采用深度神经网络,但随着我们的模型和训练算法变得更大、更复杂,深度学习的基本问题也越来越明显地暴露出来。深度学习模型在某些情况下并不稳健。众所周知,只要修改视频游戏屏幕上的几个像素(这种修改对人类来说根本无法察觉),用未修改的屏幕训练出来的原本超越人类性能的模型就可能失败(Qu et al. 2020)。另外,在没有特殊处理的情况下训练的计算机视觉模型,可能无法识别旋转的或类似变换的例子,换句话说,我们目前的模型和训练方法不适合推广到新的任务中去。最后,大多数深度学习模型不适应学习任务的变化。模型对输入进行假设,并期望环境的刚性配置和静止性,即统计学家认为的数据生成过程。例如,在一个确定的顺序中,模型可能期望有固定数量的输入。我们不能期望主体(agent)有能力超越它们在训练期间学到的技能,但是一旦这些刚性配置被违反,模型就不会有好的表现,除非我们重新训练它们或者手动处理输入,使之与模型最初的训练配置一致。
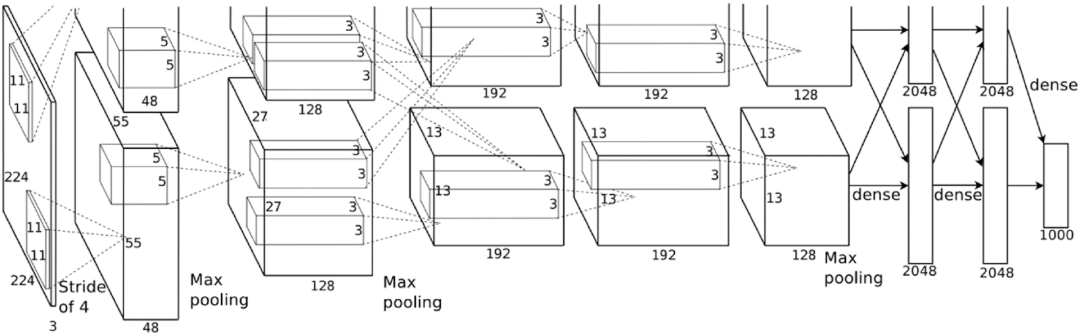
此外,随着所有这些进展,深度学习中令人印象深刻的壮举是被应用到复杂的工程项目中。例如,著名的AlexNet卷积神经网络架构(Krizhevsky et al. 2012)(见图1),在2012年赢得ImageNet竞赛之后,使深度学习成为计算机视觉界的焦点,它提出了一个精心设计的网络架构和一个精心校准的训练程序。现代神经网络通常更加复杂,需要一个横跨网络架构和精细训练方案的管道。像许多工程项目一样,在产生每一个结果时,都要付出很多劳动和微调。
图1. AlexNet(Krizhevsky et al. 2012)的神经网络结构,它是2012年ImageNet竞赛的冠军。
我们认为,深度学习的许多限制和副作用源于这样一个事实,即目前深度学习的实践与建筑工程类似。我们建造现代神经网络系统的方式类似于我们建造桥梁和建筑的方式,而这些设计是不具有适应性的。引用《控制论大脑》(The Cybernetic Brain,Pickering, 2010)一书作者Pickering的话说:“我所想到的大多数工程实例都是不具有适应性的。桥梁和建筑、车床和发动机、汽车、电视以及电脑,都被设计成对环境漠不关心,承受环境的波动,而不是适应环境。 最好的桥是一座不管天气如何都屹立在那里的桥。”
集体智能(Collective Intelligence)在自然系统中发挥了很大的作用,我们看到由于自组织而涌现的适应性设计,这种设计对周围世界的变化非常敏感,反应迅速。自然系统适应并成为环境的一部分(见图2的比喻)。
图2. 左图:位于阿尔坎塔拉的图拉真桥,由罗马人于公元106年建造(维基百科,2022)。右图:行军蚁组成的桥(Jenal, 2011)。
正如行军蚁集体形成一座适应环境的桥梁的例子一样,自然界中常见的集体行为往往会产生适应性强、稳健、对环境配置的假设不那么严格的系统。集体智能作为一个领域,研究的是从许多个体的互动(如合作、集体行动和竞争)中涌现的群体智能(Group Intelligence)。在这个领域中,诸如自组织、涌现行为、群优化和元胞自动机等思想被开发出来,以模拟和解释复杂系统。因此,看到这些思想被纳入较新的深度学习方法中是很自然的。
我们不认为深度学习模型必须按照建造桥梁的思路来构建。正如我们将在后面讨论的那样。深度学习领域之所以走上这条道路,可能只是历史上一个偶然的结果。事实上,最近有几项工作通过将深度学习与集体智能的理念相结合,以解决深度学习中存在的局限性。从将元胞自动机应用于基于神经网络的图像处理模型(Mordvintsev et al. 2020;Randazzo et al. 2020),到重新定义如何使用自组织主体来处理强化学习中的问题(Pathak et al. 2019; Huang et al. 2020; Tang and Ha, 2021)。随着我们见证了并行计算硬件(适合模拟集体行为,见图3的例子)的不断技术进步,我们可以期待更多的作品将集体智能纳入到传统深度学习处理的问题中去。
图3. GPU硬件的最新进展能够对成千上万的机器人模型进行逼真的3D模拟(Heiden et al. 2021),如本图所示,来自(Rudin et al. 2021)。这样的进展为大规模的三维模拟人工主体打开了大门,这些主体可以相互交流,并集体发展智能行为。
这篇综述的目的是对集体智能领域的核心思想、工具和见解,尤其是自组织、涌现和群体模型如何影响深度学习的不同领域,从图像处理、强化学习到元学习,提供一个高层次的调查。我们希望这篇综述能对未来的深度学习集体智能的协同作用提供一些见解,我们相信这将在这两个领域带来有意义的突破。
集体智能是一个在社会学、商业、通信和计算机科学等领域广泛使用的术语。集体智能的定义可以概括为一种不断增强和协调的分布式智能,其目标是通过相互认可和互动,取得比群体中任何个体更好的结果(Lévy, 1997; Leimeister, 2010)。集体智能带来的更好结果归功于三个因素:多样性、独立性和去中心化(Surowiecki, 2005; Tapscott and Williams, 2008)。
为了我们的目的,我们认为集体智能作为一个领域,是对许多个体之间的互动(可以是合作性的,也可以是竞争性的)中涌现的群体智能的研究。这种群体智能是涌现的产物,当观察到群体具有组成群体的个体所不具备的特性时,它才会出现,并且只有当群体中的个体在更广泛的整体中互动时才会产生涌现现象。
这种系统的例子在自然界中比比皆是,从个体之间简单的局部互动/协作中产生了复杂的全局行为,以实现共同的目标(Deneubourg and Goss,1989; Toner, 2005;Sumpter,2010; Lajad et al. 2021)。在这篇评论中,我们仅限于关注集体智能的模拟,而不是分析在自然和社会中观察到的集体智能。早期数十年的工作也探索了集体行为的模拟,并从这种模拟中收集见解。Mataric(1993)使用物理移动机器人来研究导致群体行为的社会互动。他们提出了一套基本的相互作用机制(例如,避免碰撞、跟随和聚集),希望这些基本要素能够使一群自组织主体完成一个共同的目标或相互学习。受在真实的蚂蚁群中观察到的群体行为的启发,Dorigo等人(2000)提出了stigmergy(社会性昆虫使用的一种特殊形式的间接通信)作为分布式通信范式,并展示了它是如何启发解决分布式优化和控制问题的新型算法的。此外,Schweitzer和Farmer(2003)在许多不同的背景下应用了布朗主体模型。结合多主体系统和统计方法,作者提出了一个理解复杂系统的连贯框架的愿景。
虽然这些早期的工作推动了适用于优化问题算法的发现(如解决旅行商问题的蚁群优化算法),但许多这些工作的目的是使用这些模型来理解集体智能的涌现现象。这指出了集体智能和人工智能领域的目标之间的一个根本区别。在集体智能领域,目标是建立复杂系统的模型,以帮助我们解释和理解涌现现象,这可能被应用于理解自然和社会中的真实系统。而人工智能(尤其是机器学习领域)则关注优化、分类、预测和解决一个具体问题。
在我们提到的早期作品中,并没有充分利用深度学习的建模能力或硬件的发展。尽管如此,这些工作还是不断展示了集体智能的惊人效果,即系统是自组织的,能够通过群体智能进行优化,并呈现出涌现行为。这些研究人员认为,集体智能的概念是有很好的前景的,可以应用于深度学习,以产生稳健、适应性强、对环境配置的假设不那么严格的解决方案,这也是本综述的重点。
复杂系统的思想,如自组织,被用来模拟和理解涌现和集体行为,与人工神经网络的发展有着长期而有趣的历史关系。虽然仿生学派和人工神经网络是在20世纪50年代随着人工智能的诞生而出现的,但我们的故事开始于20世纪70年代,当时的先驱Leon Chua领导的一群电子工程师开始发展非线性电路理论,并将其应用于计算。他因在20世纪70年代构思了记忆体(一个最近才实现的设备),并设计了蔡氏电路,这是第一批因表现出混沌行为而闻名电路。在20世纪80年代,他的小组开发了细胞式类神经网络(Cellular Neural Networks),这是一种类似于元胞自动机(Cellular Automata, CA)的计算系统,但使用神经网络来代替元胞自动机系统中典型的算法单元,如康威的生命游戏(Conway et al. 1970)或初等的元胞自动机规则(Wolfram, 2002)。
细胞式类神经网络(CeNNs)(Chua and Yang, 1988a, 1988b)是一种人工神经网络,每个神经元或细胞只能与它们的近邻互动。在最基本的设置中,每个细胞的状态都是通过其邻居和自身状态的非线性函数来持续更新的。与依靠数字、离散时间计算的现代深度学习方法不同,细胞式类神经网络是连续的时间系统,通常用非线性模拟电子元件实现(见图4,左),使其速度非常快。细胞式类神经网络的动力学依赖于独立的局部信息处理和处理单元之间的互动,与元胞自动机一样,它们也表现出涌现行为,并可以被做成通用图灵机。然而,它们比离散的元胞自动机和数字计算机要普遍得多。由于连续的状态空间,细胞式类神经网络表现出前所未有的涌现行为。(GoraS et al. 1995)
图4. 左图:二维细胞式类神经的典型配置(Liu et al. 2020)。右图:深度学习和细胞式类神经网络这两个词在一段时间内的谷歌趋势。
从20世纪90年代到21世纪中期,细胞式类神经网络成为人工智能研究的一个完整子领域。由于其强大而高效的分布式计算,它在图像处理、纹理分析中找到了应用,其固有的模拟计算被应用于求解偏微分方程,甚至为生物系统和器官建模(Chua and Roska, 2002)。有数以千计的同行评议的论文、教科书和一个IEEE会议专门讨论细胞式类神经网络,有许多建议扩大它们的规模,堆叠它们,将它们与数字电路相结合,并研究不同的方法来训练它们(就像我们目前在深度学习中看到的那样)。至少有两家硬件创业公司成立,生产细胞式类神经网络件和设备。
但在2000年代的后半期,他们突然从舞台上消失了!2006年之后,人工智能界几乎没有人提及细胞式类神经网络。而从2010年代开始,GPU成为了神经网络研究的主流平台,这导致了人工神经网络被重新命名为深度学习。请参阅图4(右),了解不同时期的趋势对比。
没有人能够真正指出细胞式类神经网络在人工智能研究中消亡的确切原因。就像记忆体一样,也许细胞式类神经网络领先于它的时代。或者是消费级GPU的最终崛起使其成为一个引人注目的深度学习平台。人们只能想象在一个平行宇宙中,细胞式类神经网络的模拟计算机芯片赢得了硬件彩票(Hooker, 2020),人工智能的状态可能会非常不同,因为那个世界的所有设备都嵌入了强大的分布式模拟元胞自动机。
然而,细胞式类神经网络和深度学习的一个关键区别是可及性,在我们看来,这是它没有流行起来的主要原因。在目前的深度学习范式中,有一个完整的工具生态系统,旨在使训练和部署神经网络模型变得容易。通过向深度学习框架提供数据集(Chollet et al. 2015),或模拟任务环境(Hill et al. 2018),用深度学习框架训练神经网络的参数也相对简单。深度学习工具被设计成可以被任何有基本编程背景的人使用。另一方面,细胞式类神经网络是为电子工程师设计的,当时大多数电子工程的学生对模拟电路的了解多于编程语言。
为了说明这一困难,“训练”一个细胞式类神经网络需要解决一个至少有九个常微分方程的系统,以确定支配模拟电路的系数,从而定义系统的行为!在实践中,许多从业者需要依靠一本已知问题解决方案的指南(Chua and Roska, 2002),然后针对新问题手动调整解决方案。最终,遗传算法(和早期版本的反向传播)被提出来训练细胞式类神经网络(Kozek et al. 1993),但它们需要模拟软件来训练和测试电路,然后再部署到实际(和高度定制的)细胞式类神经网络硬件上。
从细胞式类神经网络中我们可以得到很多教训。它们是模拟和数字计算的极其强大的混合体,真正综合了元胞自动机和神经网络。不幸的是,在其消亡之前,我们可能只见证了其全部潜力的开始。最终,商业化的GPU和将神经网络抽象为简单的Python代码的软件工具,使深度学习得以传播。虽然细胞式类神经网络已经消失了,但来自复杂系统的概念和想法,如元胞自动机、自组织和涌现行为,并没有消失。尽管仅限于数字硬件,我们正在见证集体智能的概念在深度学习的许多领域重新出现,从图像生成,深度强化学习,到集体和分布式学习算法。正如我们将看到的,这些概念通过为传统人工神经网络的一些局限和限制提供解决方案,推进深度学习的发展。
集体智能自然产生于网络中多个个体的相互作用,自组织行为从人工神经网络中涌现出来也就不足为奇了。当我们在整个网络中采用相同的权重参数重复计算相同的模块时尤其如此。例如,Gilpin(2019)观察到元胞自动机和卷积神经网络(CNN)之间的密切联系,这是一种经常用于图像处理的神经网络,它对所有的输入施加相同的权重(或过滤器)。事实上,他们表明任何元胞自动机都可以用某种卷积神经网络来表示,并且用卷积神经网络优雅地演示了康威的生命游戏(Conway et al. 1970)。这说明在某些情况下,卷积神经网络可以表现出有趣的自组织行为。我们将在后面讨论的Mordvintsev等人(2020)的几项工作都利用了卷积神经网络的自组织特性,并为图像再生等应用开发了基于神经网络的元胞自动机。
其他类型的神经网络架构,如图神经网络(Wu et al. 2020; Sanchez-Lengeling et al. 2021; Daigavane et al. 2021)明确地将自组织作为中心特征,将图的每个节点的行为建模为相同的神经网络模块,并将信息传递给由图的连边定义的邻居。传统上,图神经网络被用来分析相关的网络,如社交网络和分子结构。最近的工作(Grattarola et al. 2021)也证明了图神经网络有能力学习既定元胞自动机系统的规则,如Voronoi图,或群体的集聚行为(Schoenholz and Cubuk, 2020)。正如我们将在后面讨论的那样,图神经网络的自组织特性最近被应用于深度强化学习领域,创造出了具有远超一般能力的主体。
我们已经确定了四个深度学习领域,它们已经开始纳入与集体智能相关的想法:(1)图像处理,(2)深度强化学习,(3)多主体学习,以及(4)元学习。我们将在本节中详细讨论每个领域并提供相应的实例。
自然界中的隐含关系和重复出现的模式(如纹理和景物)可以采用元胞自动机的方法,以学习自然图像的替代表示。与细胞类式神经网络一样,(Mordvintsev et al. 2020)提出的神经元胞自动机(neural CA)模型将图像的每个独立像素视为一个神经网络细胞。这些网络被训练成根据其近邻的状态来预测其颜色,从而开发出一个用于生成图像的形态发生模型。他们证明了有可能通过这种方式训练神经网络来重建整个图像,即使每个细胞缺乏关于其位置的信息,只依靠来自其邻居的局部信息。这种方法使生成算法能够抵抗噪声。此外,允许图像在受损时恢复。神经元胞自动机的扩展(Randazzo et al. 2020)使单个细胞能够执行图像分类任务,如手写数字分类(MNIST),只检查单个像素的内容,并将信息传递给细胞的近邻(见图5)。随着时间的推移,将形成关于哪个数字最有可能的像素的共识,但有趣的是,根据像素的位置可能会产生分歧,特别是如果图像被故意绘制成代表不同的数字。
图5. 由(Randazzo et al. 2020)创建的训练有素的神经元胞自动机识别MNIST数字,也可作为互动网络演示。每个细胞只允许看到一个像素的内容,并与它的邻居交流。随着时间的推移,将形成一个共识,即哪个数字是最有可能的像素,但有趣的是,根据预测的像素的位置,可能会产生分歧。
神经元胞自动机的再生功能已经被探索到二维图像之外。在后来的工作中,(Zhang et al. 2021)采用了类似的方法来生成三维体素。这对高分辨率的三维扫描特别有用,因为三维形状数据往往是用稀疏和不完整的点来描述的。使用生成式元胞自动机,他们可以只从部分点的集合中恢复完整的三维形状。这种方法也适用于纯生成领域之外,也可以应用于活动环境中人工主体的构建,如游戏《我的世界》(Minecraft)(Sudhakaran et al. 2021)。训练神经元胞自动机从Minecraft中生长出复杂的实体,如城堡、公寓区和树,其中一些是由成千上万的块体素组成的。除了再生,他们的系统还能重新生成出简单功能机器的部件(如游戏中的虚拟生物),他们演示了一个形态生物在虚拟世界中被切成两半时会长成两个不同的生物(见图6)。
图6. 神经元胞自动机也被应用于Minecraft实体的再生。在这项工作中,作者的表明不仅使Minecraft建筑、树木的再生,而且可以使游戏中的简单功能机器,如蠕虫状生物的再生,在切成两半时甚至可以再生为两个不同的生物。
元胞自动机也自然适用于为图像提供视觉解释。(Qin et al. 2018)研究了使用层次元胞自动机模型进行视觉显著性分析,以识别图像中突出的项目。通过让元胞自动机对从深度神经网络中提取的视觉特征进行操作,他们能够迭代地构建图像的多尺度显著性地图,最终的图像接近于目标项目。Sandler等人( 2020)后来研究了元胞自动机在图像分割任务中的应用,这是一个深度学习享有巨大成功的领域。他们证明了使用规则相对简单的元胞自动机执行复杂的分割任务的可行性(只有10K的神经网络参数),其优点是该方法能够扩展到令人难以置信的大图像尺寸,这对于拥有数百万甚至数十亿模型参数的传统深度学习模型来说是一个挑战,因为它受到了GPU内存的限制。
深度学习的兴起催生了使用深度神经网络进行强化学习,即深度强化学习(Deep RL),为强化学习主体配备了现代神经网络架构,可以解决更复杂的问题,如高维连续控制或基于视觉的像素观测任务。虽然深度强化学习与深度学习有着相同的成功特证,即采用足够的计算资源一般会导致目标训练任务的解决方案被发现。但与深度学习一样,深度强化学习也有其局限性。当任务稍有改变时,为执行某一特定任务而训练的主体往往会失败。此外,神经网络解决方案一般只适用于具有明确的输入和输出映射的特定形态。例如,为四条腿的蚂蚁训练的运动策略可能对六条腿的蚂蚁不起作用,而一个期望接收10个输入的控制器,如果你给它5个或20个输入,就不会起作用。
进化计算领域较早地开始应对这些挑战,在支配人工主体设计的进化过程中加入了模块化(Schilling, 2000; Schilling and Steensma, 2001)。让由相同但独立的模块组成的主体通过模块间的局部相互作用促进自组织,使系统对主体形态的变化具有稳健性,这是进化系统的一个基本要求。这些想法已经在软体机器人的工作文献中提出(Cheney et al. 2014),其中机器人由由体素细胞网格组成,每个细胞由一个独立的神经网络控制,具有局部感知功能,可以产生一个局部的行动。通过信息传递,构成机器人的细胞群能够自组织,并执行一系列的运动任务(见图7)。后来的工作(Joachimczak et al. 2016)甚至提出在细胞放置的进化过程中加入变形,以产生对一系列环境的稳健配置。
图7. 二维和三维的软体机器人模拟实例。每个细胞代表一个单独的神经网络,具有局部感知功能,产生局部动作,包括与邻近的细胞交流。训练这些系统来完成各种运动任务,不仅涉及到训练神经网络,而且还涉及到形成主体形态的软体细胞的设计和放置。图自(Horibe et al. 2021)。
最近,软体机器人甚至与前面讨论的神经元胞自动机方法相结合,使这些机器人能够自我再生。Horibe等人(2021)弥合了通常在深度强化学社区完成的策略优化(目标是找到策略神经网络的最佳参数)和在软体文献中完成的那种形态-策略共同进化(形态和策略神经网络一起被优化)工作之间的差距。Bhatia等人(2021)最近开发了一个类似 OpenAI Gym(Brockman et al. 2016)的环境,名为Evolution Gym,这是一个开发和比较共同优化设计和控制的算法的基准,它提供了一个高效的软体机器人模拟器,用C++编写,带有Python接口。
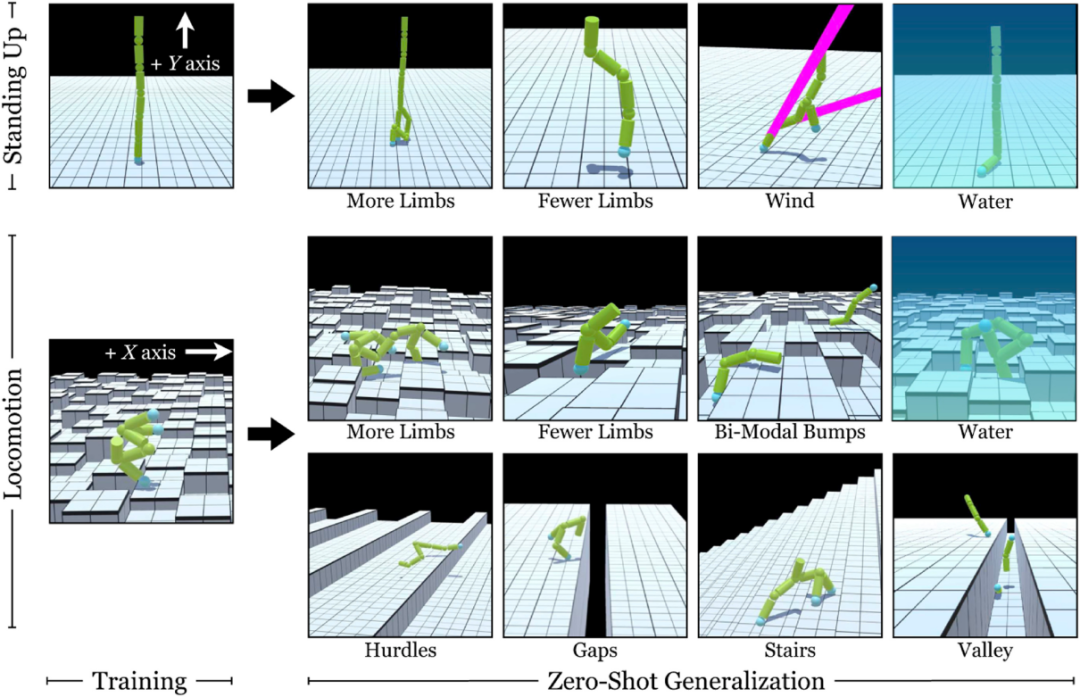
模块化、去中心化的自组织控制器也开始在深度强化学习社区进行探索。Wang等人(2018)和Huang等人(2020)探索了使用模块化神经网络来控制模拟机器人的每个单独的执行器,以实现连续控制。他们将全局运动策略表达为模块化神经网络的集合(在(Huang et al. 2020)的情况下,也是相同的网络),对应于每个主体的执行器,并使用强化学习训练该系统。像软体机器人一样,每个模块只负责控制其相应的执行器,并且只从其本地传感器接收信息(见图8)。消息在相邻的模块之间传递,在遥远的模块之间传播信息。他们表明,一个单一的模块策略可以为几种不同的机器人形态产生运动行为,并表明这些策略可以推广到训练中未知的形态变化,如有额外腿的生物。与软体机器人的情况一样,这些结果也证明了通过去中心化的模块之间的信息传递,出现了集中的协调,这些模块正在集体优化一个共同的奖励。
图8. 传统的强化学习方法为具有固定形态的特定机器人训练一个特定的策略。但最近的工作,如这里显示的(Huang et al. 2020)试图训练一个单一的模块化神经网络,负责控制机器人的单一部分。因此,每个机器人的全局策略是这些相同的模块化神经网络协调的结果。他们表明,这样的系统可以在各种不同的骨架结构上进行泛化,从跳跃者到四足动物,甚至是一些未见过的形态。
上述工作暗示了具身认知的力量,它强调了主体的身体在产生行为中的作用。虽然深度强化学习的大部分工作重点是为具有固定设计的主体(如双足机器人、人形机器人或机械臂)学习神经网络策略,但具身智能是该子领域中正在聚集兴趣的领域(Ha,2018; Pathak et al. 2019)。受(Stoy et al. 2010; Rubenstein et al. 2014; Hamann,2018)之前关于自我配置模块化机器人的几项工作的启发,Pathak等人(2019)研究了一个原始主体的集合,这些主体学习自组装成一个复杂的身体,同时也学习一个局部策略来控制身体,而没有一个明确的集中控制单元。每个原始主体(由一个肢体和一个马达组成)可以与附近的主体联系起来,允许出现复杂的形态。他们的结果表明,这些动态和模块化的主体对条件的变化具有稳健性。这些策略不仅可以推广到未知的环境,而且可以推广到未知的由更多模块组成的形态。我们注意到,这些想法可以用来让一般的深度学习系统(不局限于强化学习)拥有更灵活的架构,甚至可以学习机器学习算法,我们将在后面的元学习部分讨论这个问题。
图9. 自组织也使强化学习环境中的系统能够为特定的任务自我配置它自己的设计。在(Pathak et al. 2019)中,作者探索了这种动态和模块化的主体,并表明它们不仅可以泛化到未知的环境,还可以泛化到由额外模块组成的未知的形态。
除了适应不断变化的形态和环境外,自组织系统还能适应其感官输入的变化。感知替代是指大脑使用一种感知方式(如触摸)来提供通常由另一种感知(如视觉)收集的环境信息的能力。然而,大多数神经网络并不能适应感知替代。例如,大多数强化学习主体要求它们的输入必须是精确的、预先指定的格式,否则它们就会失败。在最近的一项工作中,Tang和Ha(2021)探索了排列不变的神经网络主体,要求其每个感知神经元(从环境中接收感觉输入的感受器)推断其输入信号的意义和背景,而不是明确地假设一个固定的意义。他们证明,这些感知网络可以被训练来整合局部收到的信息,并且使用注意力机制的交流,可以集体产生一个全局一致的政策。此外,即使其感知输入(以实值数字表示)的顺序在一个事件中被随机地改变了几次,系统仍然可以执行其任务。他们的实验表明,这种主体对包含许多额外的冗余或噪声信息的观察,或对损坏和不完整的观察结果具有稳健性。
图10. 利用自组织和注意力的特性,(Tang and Ha, 2021)中的作者研究了强化学习主体,它们将其观察结果视为任意有序、长度可变的感官输入列表。他们将CarRacing 和 Atari Pong(Brockman et al. 2016; Tang et al. 2020)等视觉任务中的输入划分为小斑块的二维网格,并打乱了它们的顺序(左)。他们还在连续控制任务中增加了许多额外的冗余噪声输入通道(Freeman et al. 2019),以打乱顺序(右),主体必须学习识别哪些输入是有用的。系统中的每个感觉神经元都收到一个特定的输入流,通过协调完成手头的任务。
集体智能可以从几个不同的尺度来看待。大脑可以被看作是一个由单个神经元集体运作的网络。每个器官可以被看作是执行集体功能的细胞的集合。单个动物可以被看作是共同工作的器官的集合。当我们进一步放大时,我们也可以超越生物学来看待人类的智慧,并将人类文明视为解决(和产生)超出单个个体能力的问题的集体智能。因此,虽然在上一节中,我们讨论了几项工作,它们利用集体智能的力量,将一个单一的强化学习主体基本上分解成一个较小的强化学习主体集合,共同为一个集体目标工作,类似于生物层面的集体智能模型,但我们也可以将多主体问题视为社会层面上的集体智能模型。
集体智能领域的一个主要焦点是研究大量个体集合所产生的群体智能和行为,无论是人类(Tapscott and Williams,2008)、动物(Sumpter,2010)、昆虫(Dorigo et al. 2000; Seeley, 2010),还是人工蜂群机器人(Hamann,2018;Rubenstein et al. 2014)。在深度强化学习领域,显然缺少这种关注。虽然多主体强化学习(multi-agent reinforcement learning, MARL)是深度强化学习的一个成熟的分支,但提出的大多数学习算法和环境都针对相对较少的主体(Foerster et al. 2016; OroojlooyJadid and Hajinezhad, 2019),因此不足以研究规模庞大群体的涌现特性。在最常见的多主体强化学习环境中(Resnick et al. 2018; Baker et al. 2019; Jaderberg et al. 2019; Terry et al. 2020),“多主体”仅仅意味着两个或四个主体经过训练,通过自我游戏的方式执行任务(Bansal et al. 2017; Liu et al. 2019; Ha, 2020)。然而,在自然界或社会中观察到的集体智能依赖于比多主体强化学习中通常研究的更多数量的个体,涉及从数千到百万的种群规模。在本节中,我们将讨论最近来自深度强化学习的多主体强化学习子领域的工作,这些工作受到了集体智能的启发(正如他们的作者甚至在他们的出版物中指出的)。与大多数多主体强化学习工作不同的是,这些工作开始采用大型的主体群体(每个都由神经网络实现),从数千到数百万,以便真正在宏观层面(1000多个主体),而不是在微观层面(2-4个主体)研究它们的涌现特性。
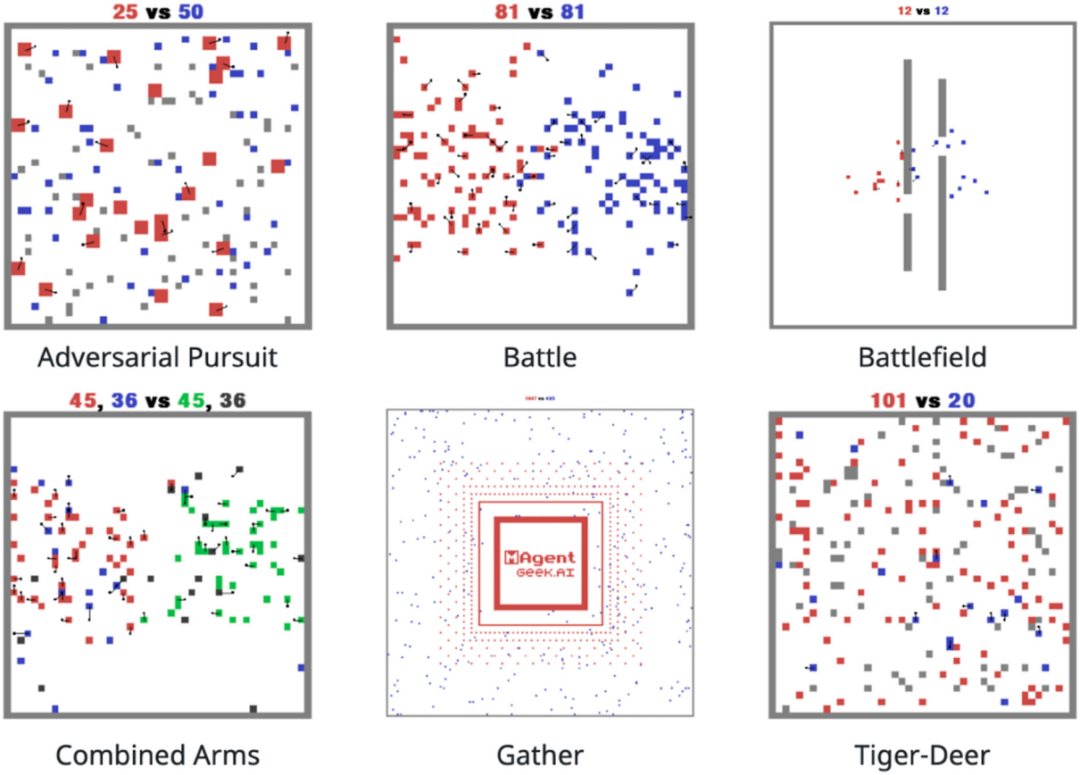
图11. MAgent(Zheng et al. 2018)是一套环境框架,在网格世界中大量的像素主体在战斗或其他竞争场景中进行互动。与大多数专注于单一主体或只有少数主体的强化学习研究的平台不同,他们的目标是支持扩展到数百万主体的强化学习研究。这个平台的环境现在作为PettingZoo(Terry et al. 2020)开源库的一部分进行维护,用于多主体强化学习研究。
深度强化学习的最新进展已经证明了在复杂的三维模拟环境中只用一个GPU就能模拟成千上万的主体(Heiden et al. 2021; Rudin et al. 2021)。一个关键的挑战是在更大的规模上接近多主体学习的问题,利用并行计算硬件和分布式计算的进展,以训练数百万主体为目标。在本节中,我们将举例说明最近在训练大规模在集体环境中互动的主体方面的尝试。
Zheng等人(2018)没有关注现实的物理学或环境的真实性,而是开发了一个名为MAgent的平台,一个简单的网格世界环境,可以允许数百万的神经网络主体。他们的重点是可扩展性,他们证明MAgent可以在一个GPU上承载多达一百万个主体(2017)。他们的平台支持主体群体之间的互动,不仅有利于研究政策优化的学习算法,更关键的是,能够研究人工智能社会中数百万主体涌现的社会现象,包括可能出现的语言和社会等级结构的出现。环境可以用脚本建立,它们提供了一些例子,如捕食者-猎物模拟、战场、对抗性追击,支持不同种类的不同主体,可能表现出不同的行为。
MAgent启发了许多最近的应用,包括多主体驾驶(Peng et al. 2021),它着眼于整个驾驶主体群体的涌现行为,以优化驾驶政策,这不仅影响到一辆车,而且旨在提高整个群体的安全性。这些方向都是很好的例子,证明了深度学习的问题(为单个个体寻找驾驶政策)与集体智能的问题(为整个群体寻找驾驶政策)之间的区别(见图12)。
图12. Neural MMO(Suarez et al. 2021)是一个在程序化生成的虚拟世界中模拟主体群体的平台,以支持多主体研究,同时保持其在计算上的要求。用户从一组提供的游戏系统中选择,为他们的具体研究问题创造环境–支持多达一千种主体和几千个时间步长的一平方公里的地图。该项目正在积极开发中,有大量的文档和工具,为研究人员提供记录和可视化工具。截至发稿时,这个平台将在2021年的Neur IPS会议上进行演示。
受MMORPG(大型多人在线角色扮演游戏,又称MMO)游戏类型的启发,Neural MMO(Suarez et al. 2021)是一个人工智能研究环境,它支持设置大量的人工主体,为了生存而必须竞争有限的资源。因此,他们的环境能够大规模模拟多主体的互动,要求主体与大群中的其他主体一起学习战斗和导航政策,这些主体都试图做同样的事情。与大多数多主体强化学习环境不同的是,允许每个主体拥有自己独特的神经网络权重集,这在内存消耗方面是一个技术挑战。该平台早期版本的初步实验结果(Suarez et al. 2019年)表明,具有不同神经网络权重参数的主体开发了填补不同领域的技能,以避免在大量主体群体中的竞争。
截至发稿时,该项目正在NeurIPS机器学习社区中积极开发(Suarez et al. 2021),致力于研究大型主体群体、长时间范围、开放式任务和模块化游戏系统。开发者提供了积极的支持和文档,还开发了额外的训练、记录和可视化工具,以实现这一大规模多主体研究的路线。这项工作仍处于早期阶段,只有时间才能告诉我们,像Neural MMO或MAgent这样能够研究大型群体的平台是否在深度学习社区中获得进一步的吸引力。
在前面的章节中,我们描述了用独立的神经网络主体的集合来表达对问题的解决,以实现一个共同的目标。这些神经网络模型的参数被优化为群体的集体表现。虽然这些系统已被证明是稳健的,并能适应其环境的变化,但它们最终被硬性规定为执行某项任务,除非从头开始重新训练,否则无法执行另一项任务。
元学习是深度学习中一个活跃的研究领域,其目标是训练系统的学习能力。它是机器学习的一个大型子领域,包括从一个训练集到另一个训练集的简单迁移学习等领域。为了我们的目的,我们遵循Schmidhuber(Schmidhuber, 2020)的工作思路,他将元学习视为可以学习更好的机器学习算法的问题,他认为这是建立真正的自我改进的AI系统所需要的。
因此,与传统上训练一个神经网络来完成一项任务不同,传统上神经网络的权重参数是用梯度下降算法来优化的,或者用进化策略(Tang et al. 2022),元学习的目标是训练一个元学习者(可以是另一个基于神经网络的系统)来学习一种学习算法。这是一项特别具有挑战性的任务,其历史悠久,见Schmidhuber的评论(Schmidhuber, 2020)。在这一节中,我们将强调最近有希望的工作,这些工作利用集体主体,可以学会学习,而不是只学会执行一个特定的任务(我们在上一节中已经介绍了)。
自组织的概念可以自然地应用于训练神经网络,通过扩展构成人工神经网络的基本构件来进行元学习。正如我们所知,人工神经网络由相同的神经元组成,这些神经元被建模为非线性激活函数。这些神经元在网络中通过突触连接,突触是权重参数,通常用梯度下降等学习算法来训练。但是可以考虑将神经元和突触的抽象扩展到静态激活函数和浮点参数之外。事实上,最近的工作(Ohsawa et al. 2018; Ott, 2020)已经探索了将神经网络的每个神经元建模为一个单独的强化学习主体。使用强化学习的术语,每个神经元的观察是它的当前状态,它随着信息在网络中的传输而变化,每个神经元的行动使每个神经元能够修改它与系统中其他神经元的连接;因此,元学习的问题被视为一个多主体强化学习问题,每个主体是神经网络中神经元集合的一部分。虽然这种方法很优雅,但上述作品只能够学习解决玩具问题(toy problem),还不能与现有的学习算法竞争。
最近的方法已经超越了使用简单的标量权重,在神经元之间传输标量信号。Sandler等人(2021)介绍了一种新型的广义人工神经网络,其中神经元和突触都有多种状态。传统的人工神经网络可以被看作是其框架的一个特例,有两个状态,一个用于激活,另一个用于使用反向传播学习规则产生的梯度。在一般框架中,他们不需要反向传播程序来计算任何梯度,而是依靠一个共享的局部学习规则来更新突触和神经元的状态。这种Hebbian式的双向局部更新规则只需要每个突触和神经元收集自其邻近的突触和神经元的状态信息,类似于元胞自动机。该规则被参数化为一个低维基因组向量,并且在整个系统中是一致的。他们采用了进化策略或传统的优化技术来元学习这个基因组向量。他们的主要结果是,在训练任务上元学习的更新规则可以推广到未知的新测试任务。此外,对于几个标准的分类任务,更新规则比基于梯度下降的学习算法表现得更快。
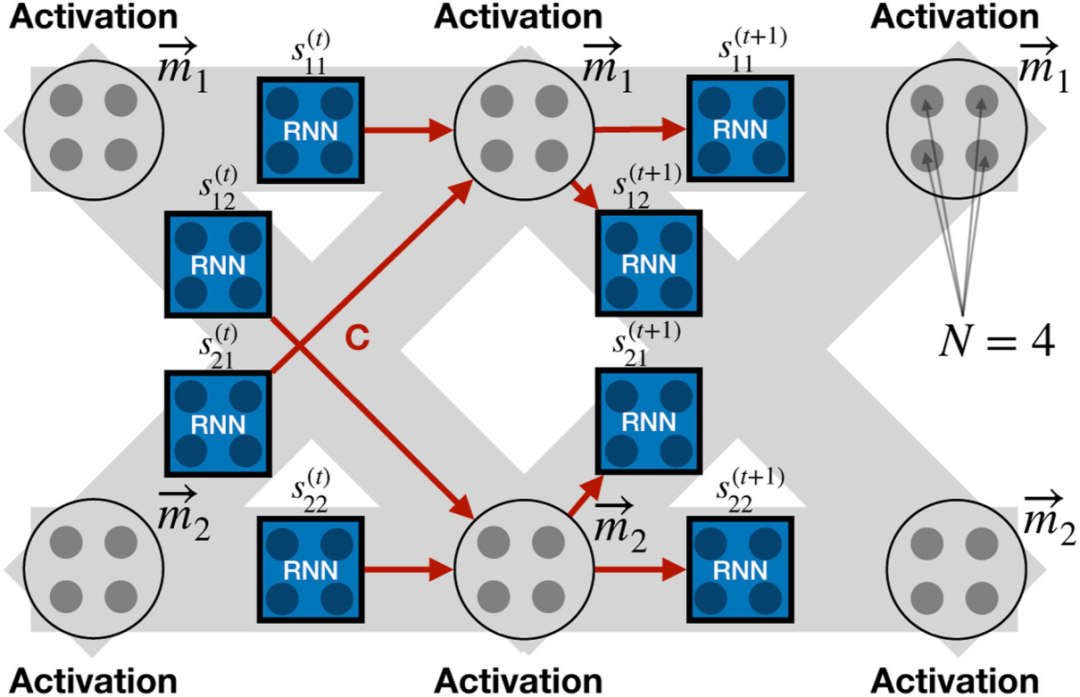
Kirsch和Schmidhuber(2020)也采取了类似的方向,神经网络的神经元和突触也被泛化为更高维度的信息传递系统,但在他们的案例中,每个突触都被一个具有相同共享参数的循环神经网络(RNN)取代。这些循环神经网络突触是双向的,支配着整个网络的信息流。与Sandler等人(2021)一样,双向属性允许网络在前向传播模式下运行系统,同时用于推理和学习。这个系统的权重基本上存储在循环神经网络的隐藏状态中,所以通过简单地运行系统,它们可以使用错误信号作为反馈来训练自己。由于循环神经网络是通用计算机,他们能够证明该系统可以编码基于梯度的反向传播算法,通过训练该系统来简单地模拟反向传播,而不是通过手工设计明确地计算梯度。当然,他们的系统比反向传播要通用得多,因此能够学习比反向传播更有效的新学习算法(见图13)。
图13. Sandler(2021)和Kirsch和Schmidhuber(2020)最近的工作试图概括人工神经网络的公认概念,每个神经元可以持有多个状态而不是一个标量值,每个突触的功能是双向的,以促进学习和推理。在这个图中,(Kirsch and Schmidhuber, 2020)使用一个相同的循环神经网络(RNN)(具有不同的内部隐藏状态)来模拟每个突触,并表明网络可以通过简单地向前运行循环神经网络来训练,而不使用反向传播。
本节提到的前两项工作在写作时才刚刚发表,我们相信,这些去中心化的局部元学习方法有可能在未来彻底改变神经网络的使用方式,挑战目前分离模型训练和模型部署的范式。在证明这些方法可以扩展到更大的数据集方面仍有许多工作要做,这是因为固有的更大的内存需求(由于系统的内部状态大很多)。此外,虽然这些算法能够产生比梯度下降更有效的学习算法,但这种效率只在学习的早期阶段明显,而且性能往往在早期达到顶峰。梯度下降,虽然效率较低,但对少样本学习的偏向较小,而且可以继续运行更多的周期来完善权重参数,最终产生的网络将取得更高的性能。
在这篇综述中,我们首先简要介绍了历史背景,以描述深度学习和集体智能研究的交织发展。这两个研究领域的诞生时间大致相同,我们也可以发现这两个领域在整个历史上的兴衰有一些正相关的关系。这并非巧合,因为这两个领域中的一个领域的进展和突破通常可以创造新的想法,或补充另一个领域问题的解决方案。例如,将深度神经网络和相关训练算法引入元胞自动机,使我们能够开发出抗噪音和具有“自我修复”特性的图像生成算法。这项调查探索了深度学习中的几项工作,这些工作也受到了集体智能中的概念的启发。在宏观层面上,多主体深度强化学习中的集体智能推动了有趣的工作,这些工作可以通过集体自我博弈超越人类的表现,并去中心化的自组织机器人控制器的发展;在微观层面上,集体智能也蕴含在用深度模型在系统内以更精细的颗粒度模拟每个神经元、突触或其他对象的先进方法里面。
尽管在本文中描述的工作取得了进展,但仍有许多挑战摆在面前。虽然神经元胞自动机技术已经被应用于图像处理,但到目前为止,它们的应用仅限于相对较小和简单的数据集,而且它们的图像生成质量,仍然远远低于如ImageNet或Celebrity Faces(Palm et al. 2022)等更复杂数据集上的最新技术水平。对于深度强化学习来说,虽然所研究的工作已经证明了一个全局策略可以被较小的单个策略的集合所取代,但我们还没有将这些实验转移到真正的物理机器人上。最后,我们已经见证了自组织指导元学习算法。虽然这一工作路线非常有前途,但由于用整个人工神经网络取代每一个神经连接所带来的大量计算要求,它们目前只限于小规模的实验。我们相信许多挑战将在适当的时候得到解决,因为它们的发展轨迹已经开始了。
纵观它们各自的发展轨迹,深度学习在开发新型架构和训练算法方面取得了显著的成就,从而实现了高效学习和更好的性能。深度学习的研究和开发周期更注重工程构建,因此看到的进展更多的是基于基准(如图像识别问题的分类准确度或语言建模和机器翻译问题的相关量化指标)。深度学习的进展通常是更多的增量和可预测的,而集体智能则更多地关注问题的提出和环境机制,以激发新的涌现的群体行为。正如我们在这次调查中所显示的,基于集体智能的技术能够实现以前根本不可能实现的新能力。例如,不可能将一个固定的机器人逐步改进成一个能够自组装的机器人,并从这种模块化中获得所有的好处。自然,这两个领域可以相互补充。我们相信,这种携手并进的共同开发方式将继续下去。
-
Alam M, Samad MD, Vidyaratne L, et al. (2020) Survey on deep neural networks in speech and vision systems. Neurocomputing 417: 302–321.
-
Baker B, Kanitscheider I, Markov T, et al. (2019) Emergent Tool Use from Multi-Agent Autocurricula. arXiv preprint arXiv:1909. 07528.
-
Bansal T, Pachocki J, Sidor S, et al. (2017) Emergent Complexity via Multi-Agent Competition. arXiv preprint arXiv:1710. 03748.
-
Bhatia J, Jackson H, Tian Y, et al. (2021) Evolution gym: A large-scale benchmark for evolving soft robots. In: Advances in Neural Information Processing Systems. Curran Associates, Inc.
-
Brockman G, Cheung V, Pettersson L, et al. (2016) Openai Gym. arXiv preprint arXiv:1606. 01540.
-
Brown TB, Mann B, Ryder N, et al. (2020) Language Models Are Few-Shot Learners. arXiv preprint arXiv:2005. 14165.
-
Cheney N, MacCurdy R, Clune J, et al. (2014) Unshackling evolution: evolving soft robots with multiple materials and a powerful generative encoding. ACM SIGEVOlution 7(1): 11–23.
-
Chollet F, et al. (2015) Keras.
-
Chua LO, Roska T (2002) Cellular Neural Networks and Visual Computing: Foundations and Applications. Cambridge University Press.
-
Chua LO, Yang L (1988a) Cellular neural networks: Applications. IEEE Transactions on Circuits and Systems 35(10): 1273–1290.
-
Chua LO, Yang L (1988b) Cellular neural networks: Theory. IEEE Transactions on Circuits and Systems 35(10): 1257–1272.
-
Conway J, et al. (1970) The game of life. Scientific American 223(4): 4.
-
Daigavane A, Ravindran B, Aggarwal G (2021) Understanding Convolutions on Graphs. Distill. https://distill.pub/2021/understanding-gnns
-
Deneubourg J-L, Goss S (1989) Collective patterns and decision-making. Ethology Ecology & Evolution 1(4): 295–311.
-
Deng J, Dong W, Socher R, et al. (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255.
-
Dorigo M, Bonabeau E, Theraulaz G (2000) Ant algorithms and stigmergy. Future Generation Computer Systems 16(8): 851–871.
-
Foerster JN, Assael YM, De Freitas N, et al. (2016) Learning to Communicate with Deep Multi-Agent Reinforcement Learning. arXiv preprint arXiv:1605.06676.
-
Freeman CD, Metz L, Ha D (2019) Learning to Predict without Looking Ahead: World Models without Forward Prediction.
-
Gilpin W (2019) Cellular automata as convolutional neural networks. Physical Review E 100(3): 032402.
-
GoraS L, Chua LO, Leenaerts D (1995) Turing patterns in cnns. i. once over lightly. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications 42(10): 602–611.
-
Grattarola D, Livi L, Alippi C (2021) Learning Graph Cellular Automata.
-
Ha D (2018) Reinforcement Learning for Improving Agent Design.
-
Ha D (2020) Slime Volleyball Gym Environment. https://github.com/hardmaru/slimevolleygym
-
Ha D, Schmidhuber J (2018) Recurrent world models facilitate policy evolution. Advances in Neural Information Processing Systems 31: 2451–2463. https://worldmodels.github.io
-
Hamann H (2018) Swarm Robotics: A Formal Approach. Springer.
-
He K, Zhang X, Ren S, et al. (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778.
-
Heiden E, Millard D, Coumans E, et al. (2021) NeuralSim: Augmenting differentiable simulators with neural networks. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA).
-
Hill A, Raffin A, Ernestus M, et al. (2018) Stable Baselines.
-
Hooker S (2020) The Hardware Lottery. arXiv preprint arXiv:2009.06489.
-
Horibe K, Walker K, Risi S (2021) Regenerating soft robots through neural cellular automata. In: EuroGP, pp. 36–50.
-
Huang W, Mordatch I, Pathak D (2020) One policy to control them all: Shared modular policies for agent-agnostic control. In: International Conference on Machine Learning, pp. 4455–4464.
-
Jabbar A, Li X, Omar B (2021) A survey on generative adversarial networks: Variants, applications, and training. ACM Computing Surveys (CSUR) 54(8): 1–49.
-
Jaderberg M, Czarnecki WM, Dunning I, et al. (2019) Human-level performance in 3d multiplayer games with population-based reinforcement learning. Science 364(6443): 859–865.
-
Jenal M (2011) What Ants Can Teach Us about the Market.
-
Joachimczak M, Suzuki R, Arita T (2016) Artificial metamorphosis: Evolutionary design of transforming, soft-bodied robots. Artificial Life 22(3): 271–298.
-
Kirsch L, Schmidhuber J (2020) Meta Learning Backpropagation and Improving it. arXiv preprint arXiv:2012. 14905.
-
Kozek T, Roska T, Chua LO (1993) Genetic algorithm for cnn template learning. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications 40(6): 392–402.
-
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems 25: 1097–1105.
-
Lajad R, Moreno E, Arenas A (2021) Young honeybees show learned preferences after experiencing adulterated pollen. Scientific Reports 11(1): 1–11.
-
Leimeister JM (2010) Collective intelligence. Business & Information Systems Engineering 2(4): 245–248.
-
Lévy P (1997) Collective Intelligence.
-
Liu J-B, Raza Z, Javaid M (2020) Zagreb connection numbers for cellular neural networks. Discrete Dynamics in Nature and Society 2020: 1–8.
-
Liu S, Lever G, Merel J, et al. (2019) Emergent Coordination through Competition. arXiv preprint arXiv:1902.07151
-
Mataric MJ (1993) Designing emergent behaviors: From local interactions to collective intelligence. In: Proceedings of the Second International Conference on Simulation of Adaptive Behavior, pp. 432–441.
-
Mnih V, Kavukcuoglu K, Silver D, et al. (2015) Human-level control through deep reinforcement learning. Nature 518(7540): 529–533.
-
Mordvintsev A, Randazzo E, Niklasson E, et al. (2020) Growing Neural Cellular Automata. Distill.
-
Ohsawa S, Akuzawa K, Matsushima T, et al. (2018) Neuron as an Agent.
-
OroojlooyJadid A, Hajinezhad D (2019) A Review of Cooperative Multi-Agent Deep Reinforcement Learning. arXiv preprint arXiv:1908.03963.
-
Ott J (2020) Giving up Control: Neurons as Reinforcement Learning Agents. arXiv preprint arXiv:2003.11642.
-
Palm RB, Duque MG, Sudhakaran S, et al. (2022) Variational neural cellular automata. In: International Conference on Learning Representations.
-
Pathak D, Lu C, Darrell T, et al. (2019) Learning to Control Self-Assembling Morphologies: A Study of Generalization via Modularity. arXiv preprint arXiv:1902.05546.
-
Peng Z, Hui KM, Liu C, et al. (2021) Learning to simulate self-driven particles system with coordinated policy optimization. Advances in Neural Information Processing Systems 34.
-
Pickering A (2010) The Cybernetic Brain. University of Chicago Press.
-
Qin Y, Feng M, Lu H, et al. (2018) Hierarchical cellular automata for visual saliency. International Journal of Computer Vision 126(7): 751–770.
-
Qu X, Sun Z, Ong YS, et al. (2020) Minimalistic attacks: How little it takes to fool deep reinforcement learning policies. IEEE Transactions on Cognitive and Developmental Systems 13: 806–817.
-
Radford A, Kim JW, Hallacy C, et al. (2021) Learning Transferable Visual Models from Natural Language Supervision. arXiv preprint arXiv:2103.00020.
-
Radford A, Narasimhan K, Salimans T, et al. (2018) Improving Language Understanding by Generative Pre-training.
-
Radford A, Wu J, Child R, et al. (2019) Language models are unsupervised multitask learners. OpenAI blog 1(8): 9.
-
Randazzo E, Mordvintsev A, Niklasson E, et al. (2020) Self-classifying Mnist Digits. Distill.
-
Resnick C, Eldridge W, Ha D, et al. (2018) Pommerman: A Multi-Agent Playground. arXiv preprint arXiv:1809.07124.
-
Rubenstein M, Cornejo A, Nagpal R (2014) Programmable self-assembly in a thousand-robot swarm. Science 345(6198): 795–799.
-
Rudin N, Hoeller D, Reist P, et al. (2021) Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning. arXiv preprint arXiv:2109.11978.
-
Sanchez-Lengeling B, Reif E, Pearce A, et al. (2021) A gentle introduction to graph neural networks. Distill 6(9): e33.
-
Sandler M, Vladymyrov M, Zhmoginov A, et al. (2021) Meta-learning bidirectional update rules. In: International Conference on Machine Learning, pp. 9288–9300.
-
Sandler M, Zhmoginov A, Luo L, et al. (2020) Image Segmentation via Cellular Automata. arXiv preprint arXiv:2008.04965.
-
Schilling MA (2000) Toward a general modular systems theory and its application to interfirm product modularity. Academy of Management Review 25(2): 312–334.
-
Schilling MA, Steensma HK (2001) The use of modular organizational forms: An industry-level analysis. Academy of Management Journal 44(6): 1149–1168.
-
Schmidhuber J (2014) Who Invented Backpropagation? More[DL2].
-
Schmidhuber J (2020) Metalearning Machines Learn to Learn (1987). https://people.idsia.ch/juergen/metalearning.html
-
Schoenholz S, Cubuk ED (2020) Jax md: a framework for differentiable physics. Advances in Neural Information Processing Systems 33.
-
Schweitzer F, Farmer JD (2003) Brownian Agents and Active Particles: Collective Dynamics in the Natural and Social Sciences. Springer. Volume 1.
-
Seeley TD (2010) Honeybee Democracy. Princeton University Press.
-
Silver D, Huang A, Maddison CJ, et al. (2016) Mastering the game of go with deep neural networks and tree search. Nature 529(7587): 484–489.
-
Simonyan K, Zisserman A (2014) Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv preprint arXiv:1409.1556.
-
Stahlberg F (2020) Neural machine translation: A review. Journal of Artificial Intelligence Research 69: 343–418.
-
Stoy K, Brandt D, Christensen DJ, et al. (2010) Self-reconfigurable Robots: An Introduction.
-
Suarez J, Du Y, Isola P, et al. (2019) Neural Mmo: A Massively Multiagent Game Environment for Training and Evaluating Intelligent Agents. arXiv preprint arXiv:1903.00784.
-
Suarez J, Du Y, Zhu C, et al. (2021) The neural mmo platform for massively multiagent research. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
-
Sudhakaran S, Grbic D, Li S, et al. (2021) Growing 3d Artefacts and Functional Machines with Neural Cellular Automata. arXiv preprint arXiv:2103.08737.
-
Sumpter DJ (2010) Collective Animal Behavior. Princeton University Press.
-
Surowiecki J (2005) The Wisdom of Crowds. Anchor.
-
Tan X, Qin T, Soong F, et al. (2021) A Survey on Neural Speech Synthesis. arXiv preprint arXiv:2106.15561.
-
Tang Y, Ha D (2021) The sensory neuron as a transformer: Permutation-invariant neural networks for reinforcement learning. In: Thirty-Fifth Conference on Neural Information Processing Systems. https://attentionneuron.github.io
-
Tang Y, Nguyen D, Ha D (2020) Neuroevolution of self-interpretable agents. In: Proceedings of the Genetic and Evolutionary Computation Conference.
-
Tang Y, Tian Y, Ha D (2022) Evojax: Hardware-Accelerated Neuroevolution. arXiv preprint arXiv:2202.05008.
-
Tapscott D, Williams AD (2008) Wikinomics: How Mass Collaboration Changes Everything. Penguin.
-
Terry JK, Black B, Jayakumar M, et al. (2020) Pettingzoo: Gym for Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2009.14471.
-
Toner J, Tu Y, Ramaswamy S (2005) Hydrodynamics and phases of flocks. Annals of Physics 318(1): 170–244.
-
Vinyals O, Babuschkin I, Czarnecki WM, et al. (2019) Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature 575(7782): 350–354.
-
Wang T, Liao R, Ba J, et al. (2018) Nervenet: Learning structured policy with graph neural networks. In: International Conference on Learning Representations.
-
Wang Z, She Q, Ward TE (2021) Generative adversarial networks in computer vision: A survey and taxonomy. ACM Computing Surveys (CSUR) 54(2): 1–38.
-
Wikipedia (2022) Trajan’s Bridge at Alcantara. Wikipedia.
-
Wolfram S (2002) A New Kind of Science. Champaign, IL: Wolfram media. Volume 5.
-
Wu Z, Pan S, Chen F, et al. (2020) A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems 32(1): 4–24.
-
Zhang D, Choi C, Kim J, et al. (2021) Learning to generate 3d shapes with generative cellular automata. In: International Conference on Learning Representations.
-
Zheng L, Yang J, Cai H, et al. (2018) Magent: A many-agent reinforcement learning platform for artificial collective intelligence. Proceedings of the AAAI Conference on Artificial Intelligence 32.
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「我的集智」推送论文信息。扫描下方二维码即可一键订阅: