关键词:自然语言处理,预训练语言模型,参数微调
论文题目:Parameter-efficient fine-tuning of large-scale pre-trained language models
论文来源:Nature Machine Intelligence
论文链接:https://www.nature.com/articles/s42256-023-00626-4
随着预训练语言模型(pre-trained language model, PLM)和预训练-微调范式的盛行,人们不断发现更大的模型往往能产生更好的性能。然而,随着预训练语言模型规模的扩大,微调和存储所有参数的成本过高,使得模型的部署变得不可行。这就需要一个新的研究分支,专注于预训练语言模型的参数高效适应性,只优化一小部分模型参数,同时保持其余参数的固定,这能大大降低计算和存储成本。总的来说,这一研究领域表明大规模的模型,可以通过优化少量参数来有效激活。
尽管已经存在各种各样的设计,这篇文章用一个更一致和更容易理解的术语“delta-tuning”来讨论和分析这些方法,其中“delta” 是一个经常用来表示变化的数学符号,被借用来指训练中“改变”的那部分参数。这项研究正式描述了这个问题,并为现有的 delta-tuning 方法提出了一个统一的分类标准,以探索它们之间的关联和差异。delta-tuning 微调方法只更新预训练语言模型(PLM)的最后一层,而保持其他层不变。研究证明 delta-tuning 可以在不损失性能的情况下,显著减少微调的参数数量和计算成本。
作者还讨论了 delta-tuning 有效性的理论原则,并从优化和最优控制的角度对其进行解释。此外,作者还对 100 多个自然语言处理任务进行了全面的实证研究,并研究了 delta-tuning 的各个方面。在多个自然语言处理任务上,用 delta-tuning 微调的预训练语言模型可以达到和全模型微调相当或更好的效果。
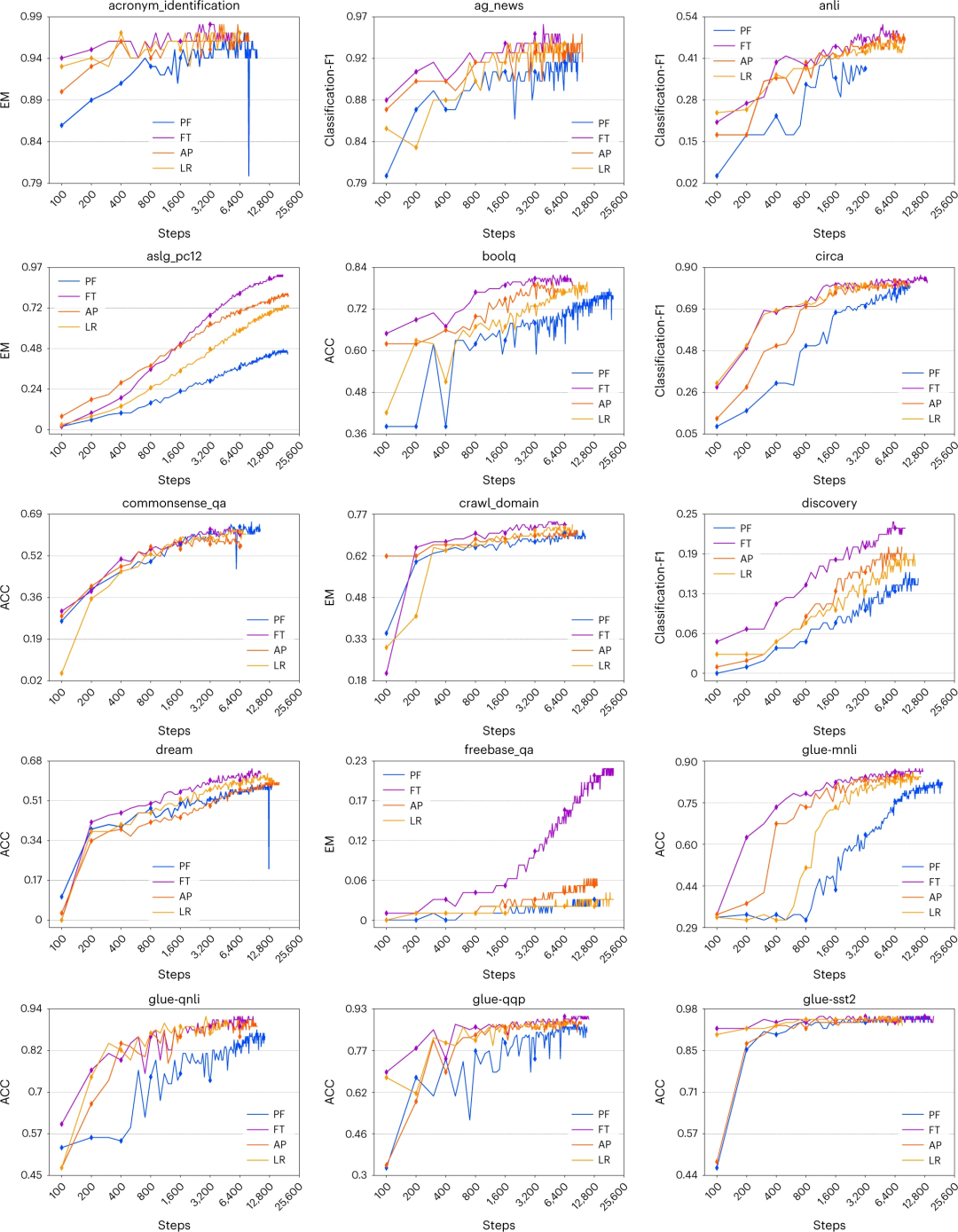
图1. T5(BASE) 在不同训练步骤中采用不同增量调整方法(LR、AP 和 PF)和微调 (FT) 的性能。
图2. 每个delta-tuning方法和微调所消耗的GPU内存。
图3. delta-tuning 的分类标准。这里 Θ 表示预训练参数,Θ’ 表示调整好的参数。
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「我的集智」推送论文信息。扫描下方二维码即可一键订阅:

推荐阅读