Science 速递:大语言模型对蛋白质结构进行演化尺度预测
2023-03-21
3,191
关键词:大语言模型,蛋白质结构预测,深度学习
论文题目:Evolutionary-scale prediction of atomic-level protein structure with a language model
论文链接:https://www.science.org/doi/10.1126/science.ade2574
语言模型有可能在整个进化过程中学习蛋白质序列的模式。这一想法促使人们对进化规模的语言模型进行研究,其中基本模型学习反映基础生物学方面的表征,并且随着表征能力的增强,在低分辨率下捕捉二级结构和三级结构。
Science 的这篇文章展示了使用大语言模型从主序列直接推断出完整的原子级蛋白质结构。研究人员构建 ESMFold,一个从序列到结构的预测器,其准确度几乎与基于对齐的方法一样,而且速度相当快。当蛋白质序列的语言模型被扩展到150亿个参数时,蛋白质结构的原子分辨率图就会在学习的表征中出现。这导致了高分辨率结构预测的数量级加速,从而实现了元基因组蛋白质的大规模结构特征。
这项研究应用这一能力构建了 ESM 元基因组图谱,预测了6.17亿个元基因组蛋白质序列的结构,其中包括2.25亿个高置信度的预测,这使我们看到了天然蛋白质的广阔性和多样性。
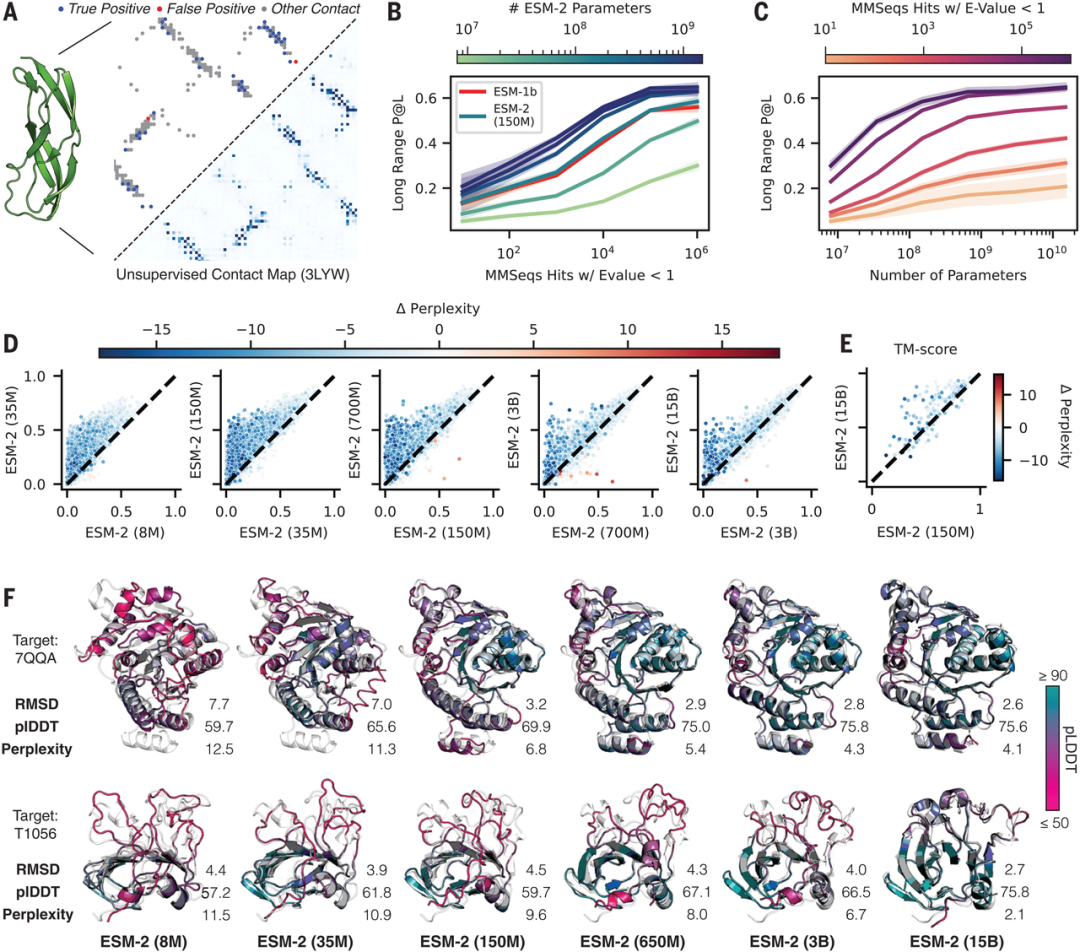
图1. 将语言模型扩展到 150 亿个参数时出现结构

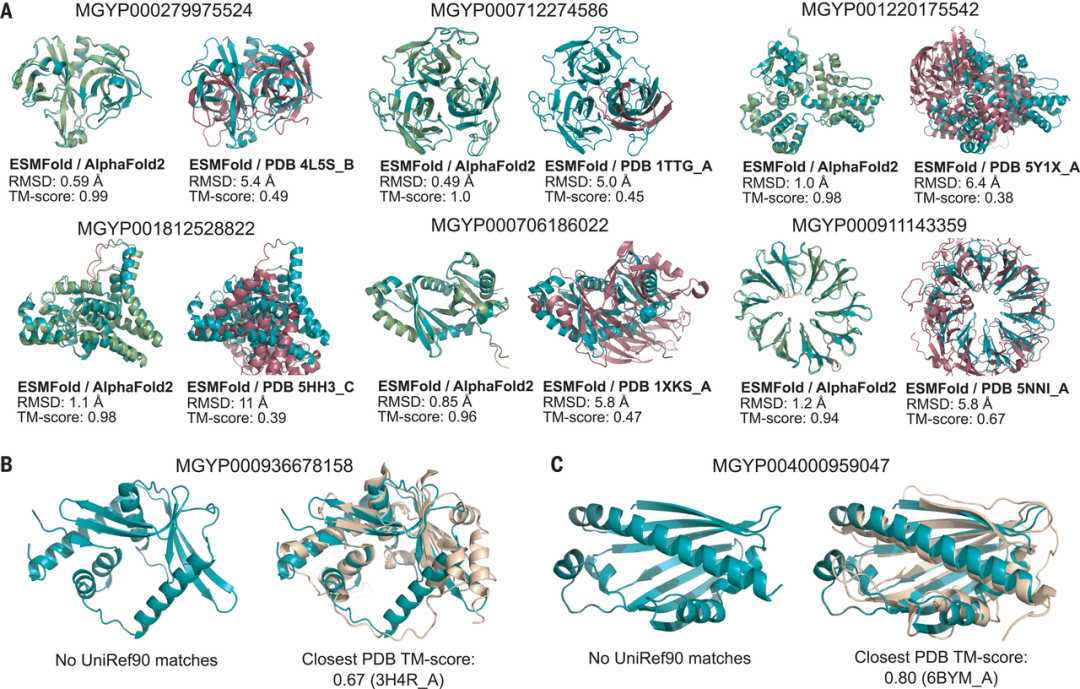
图3. 宏基因组序列的 ESMFold 结构预测示例
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 9:00-11:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。
推荐阅读














