RWKV-7:从第一性原理出发的序列建模架构

导语
在Transformer主导的大模型时代,二次复杂度与长上下文成本问题日益凸显。而RWKV-7作为新一代RNN架构,以“内世界持续拟合外世界”的第一性原理,实现了训练高效、推理低耗且表达力超越Transformer的突破。本文旨在解析其核心思想、性能优势及对智能体时代的潜在影响,探讨它如何为高效、强大的序列建模提供全新可能。
研究领域:大模型架构、全注意力架构、线性复杂度、序列建模、预训练、RWKV
RWKV-7 是精确的构造,来自于第一性原理:模型的内部世界必须持续拟合外部世界。
从这个第一性原理就可以直接写出 RWKV-7 的精确公式。
——RWKV架构提出者,彭博,RWKV-7 as a meta-in-context learner:从第一性原理真正理解
论文标题:RWKV-7 “Goose” with Expressive Dynamic State Evolution
论文地址:https://arxiv.org/abs/2503.14456
代码地址:https://github.com/BlinkDL/RWKV-LM
模型内世界持续拟合外世界的想法并不罕见,实际上LSTM模型提出者于尔根·施密德胡伯(Juergen Schmidhuber)在很多年前就提出过,他称为 fast weights。学者们基于该思想做出了诸多脑科学、人工智能领域优秀研究。那么,能否基于该想法,构建一个性能超群的序列建模基础架构呢?这就是RWKV-7,从第一性原理出发的序列建模架构。
有了Transformer,
为什么还需要新的序列建模架构?
有了Transformer,
为什么还需要新的序列建模架构?
首先明确,由于同一架构不同参数、超参数、训练方式、数据进行训练,最终成效可能大不相同,如DeepSeek-V2、DeepSeek-V3、DeepSeek-R1架构均为DeepSeek提出的多头隐注意力(Multi-head Latent Attention,MLA),但模型效果不同。本文探讨的主题并非具体模型,而是架构。可能会涉及关于具体模型的讨论,但这些讨论的目的还是为讨论架构。
很多任务均可以被视为序列建模,虽然目前纯解码式Transformer架构(本文中,Transformer即一般意义上的全注意力full attention架构)在序列建模任务上占据了统治地位,但其自回归推理时,单个符元(token)所需的内存和计算时间随序列长度增加而增加,序列越长,Transformer计算越昂贵。
架构不变的情况下计算本身是绝对的,可以做的是工程优化,因此在笔者看来,架构决定成本,一定程度上影响表现。
人们在如何改善这种所谓的“二次复杂度”问题上,进行了诸多研究。某种意义上说,这些研究的目的就是压缩状态(Transformer中的kv缓存),压缩到极致,就是恒定大小的状态,这自然是一种一般意义上的RNN,或称线性注意力(Linear Attention)模型。传统的RNN模型问题有二:无法并行训练、难以捕捉长距离依赖。经过一系列发展,现代的RNN模型这两个问题可以说均已解决,但在RWKV-7提出前,人们一直对RNN模型能力表示怀疑,虽然在诸多指标上RNN模型有不错表现,但在同数据训练的情况下,MMLU (Massive Multitask Language Understanding)这个重要指标上,RNN模型表现依然不好。虽然有人指出MMLU范式更接近Bert等掩码模型,对自回归模型而言可能本身题目设置不合理,更多考验的是模型记忆选项的能力而非本身能力,但在这个重要指标上RNN模型不如Transformer,无疑让很多人对RNN模型能力心存疑虑,怀疑在很大投入后能力会“撞墙”,无法达到现有顶尖模型水平。
另外,William Merrill等人的一系列研究表明,固定深度的Transformer在不依赖思维链的情况下只能解决复杂性类TC0中的问题,这是一组可以被等深度、多项式大小的阈值电路族识别的问题。实际上很多我们直观上觉得并不复杂的问题都在此之外,例如简单的状态追踪(State Tracking)问题(给出诸如x=[1,0,0,0];x[2],x[3]=x[3],x[2]这样的序列,要求给出最终x的状态,在此仅进行了一次交换,实际可以任意多次),确定性有限自动机(Deterministic Finite Automata, DFA)模拟等。这表明固定深度的Transformer在不依赖思维链情况下的表达能力十分有限,但若用思维链,考虑二次复杂度问题,又会导致上下文更长,成本会大幅上升。
以上是理论上Transformer模型存在的问题,而在目前最火热的大语言模型实践中,也确实发现这些问题越来越难以忽视。主要问题有二:第一、被Grok3和GPT-4.5验证的“预训练撞墙”说,及与之对应的测试时规模法则(Test Time Scaling Law)。第二,智能体(Agent)应用与推理模型的巨量上下文使用问题;
自2024年中开始,就有消息称GPT-5训练不顺利,OpenAI灵魂人物Ilya也称由于数据已到上限,仅靠预训练已无法让模型能力进一步提升,未来需要合成数据、后训练。单纯模型、数据规模的规模法则(Scaling Law)已失效,未来是测试时规模法则,当时对此还有些争议,后来o1发布,验证了这个说法的一半,也就是通过增加在使用时的符元数确实能提高模型性能,但对预训练是否撞墙,依然存在争议。直到Grok3和GPT-4.5推出,在姗姗来迟,使用了超多计算资源的情况下并没有达到如GPT-3.5到GPT-4的提升,“预训练撞墙”这一说法终于被大家所认可。这可能与Transformer本身表达能力限制有关。
既然确实“预训练撞墙”了,那么解决方案有二:第一、更高效架构,在使用同等数据情况下性能更高;第二、在推理时更多计算,使用更多符元提高模型效果,典型代表就是o1。这要求模型具更高训练数据效率,且能以较低的成本使用长上下文。
自2024年10月22日以来,随Claude Sonnet 3.5新版本发布,大语言模型能力达到了新台阶,如Windsurf、Cline等诸多基于其能力的智能体应用如雨后春笋般涌现。智能体应用的特点就是上下文使用量巨大。与问答、聊天应用使用上下文长度较少不同,这种可以感知并操作外部世界(浏览器、用户工作目录及文件也是外部世界)的智能体由于需要大量上下文输入外部世界情况,输出模型本身思考、动作,并在需要时存在反馈过程,很容易使用巨量上下文。典型例子就是复杂程序调试,智能体完成程序-运行-报错-修改-运行-报错…可能要经过多轮上述循环才能完成调试,过程中可能还需查阅文档,整个过程需要超多上下文才能完成。
综上,现在我们确实需要一个使用训练数据效率更高,且能以较低成本使用长上下文的模型。
RWKV-7能达到什么效果?
RWKV-7能达到什么效果?
总体上,RWKV-7训练数据、计算效率高于现有顶尖模型(如Qwen2.5),由于其线性模型性质,推理时内存占用恒定,单符元所需计算恒定,上下文越长,成本优势越高,且表达力严格强于标准Transformer模型。
具体来说,RWKV-7目前推出了约1.9亿、4亿、15亿、29亿参数模型,在训练数据、计算量远少于其他顶级模型(如Qwen-2.5,Llama-3.2)的情况下,达到了多语言性能达到同规模世界最强、英语性能与同规模最顶级模型相当的表现。并且可以在固定深度下完成经典Transformer在定深情况下无法完成的状态追踪与确定性有限自动机模拟任务,能解决超出复杂性类TC0的任务,也就是说表达能力超过经典Transformer。
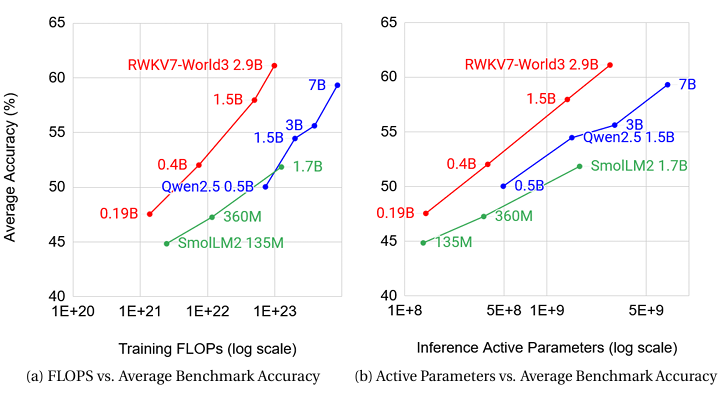
图1 RWKV-7与典型顶尖模型多语言性能比较,左图:训练FLOPs vs 平均精度;右图:推理激活参数 vs 平均精度
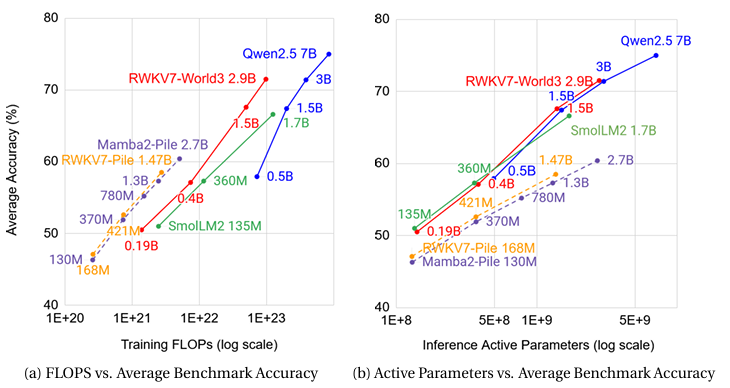
图2 RWKV-7与典型顶尖模型英语性能比较,左图:训练FLOPs vs 平均精度;右图:推理激活参数 vs 平均精度

图3 RWKV-7与SmollM2、Qwen2.5、Llama3.2等模型在英语评测上的表现
从图1、图2和图3可以明显看出,RWKV-7在多语言性能上同规模表现最好,在英语性能上与同规模顶尖模型表现相当,同时训练所需算力和数据要少得多。图中,RWKV7-World3是使用RWKV的World3数据集训练出的模型,而RWKV7-Pile则是使用Pile数据集训练出的。值得注意的是,图3中除RWKV系列模型,其他均为全注意力模型,可以看到,在MMLU这一指标上,RWKV-7并不逊于SmolLM2、Llama3.2这两个非常优秀的模型。考虑到训练RWKV-7使用的数据量远少于其他模型,可以认为RWKV-7这一RNN模型在MMLU这一之前RNN一直劣于Transformer的指标上不再有劣势,根据图中不同模型训练符元量与mmlu指标表现的对比,合理推测在同等数据下,同规模RWKV-7的MMLU会优于Transformer模型。
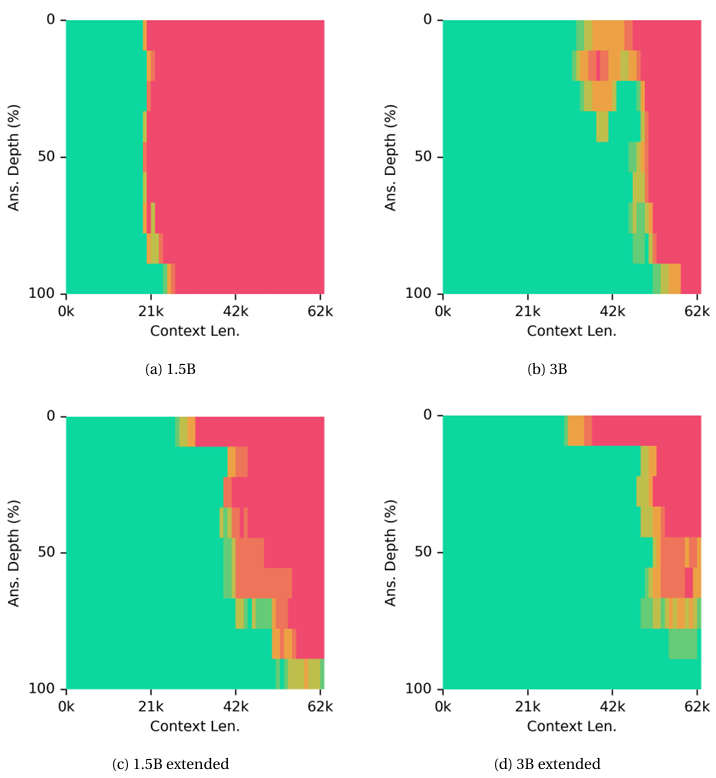
图4 不同参数量RWKV-7的“大海捞针”测试结果,图(a)(b)模型分别为RWKV7-World3-1.5B和RWKV7-World3-3B,均是在4096上下文长度下训练的,而图(c)(d)中则是在128K上下文数据集微调后模型测试的结果
线性模型的长文本能力经常被人怀疑,其中一个经典测试就是所谓的“大海捞针”,仅在4096上下文长度训练过的RWKV7-World3-1.5B模型在19600符元长度的大海捞针实验中实现了完美检索,在超过20600符元时性能出现大规模下降,而RWKV7-World3-2.9B模型则完美通过了约35000符元的大海捞针实验,但在超过之后性能就开始下降。对RWKV7-World3-1.5B和RWKV7-World3-2.9B在长度为128k符元的训练数据上进行了微调,发现RWKV-7-1.5B可以可靠检索多达约两万九千个符元,仅在约四万左右符元长度下观察到性能出现较大退化。而微调后的RWKV-7-2.9B则能可靠检索三万个符元,在五万符元长度处性能出现较大退化,见图4。
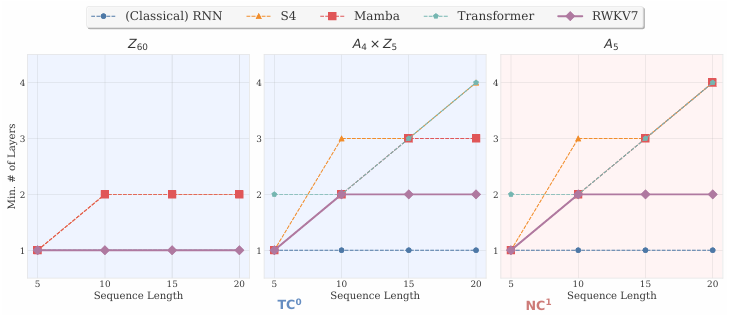
图5 不同架构在不同群状态追踪问题在验证集上达到95%正确率所需要的最小层数
图5的实验结果表明,两层的RWKV-7即可完成A5群的状态追踪任务,这验证了RWKV-7附录中的证明。另外,论文中还证明了四层的RWKV-7可以模拟任何确定性有限自动机。而这两个任务(状态追踪,模拟确定性有限自动机)均无法通过固定深度的Transformer完成。以上结果表明,RWKV-7确实在保持可以并行训练推理的前提下,表达力超过了经典的Transformer模型。
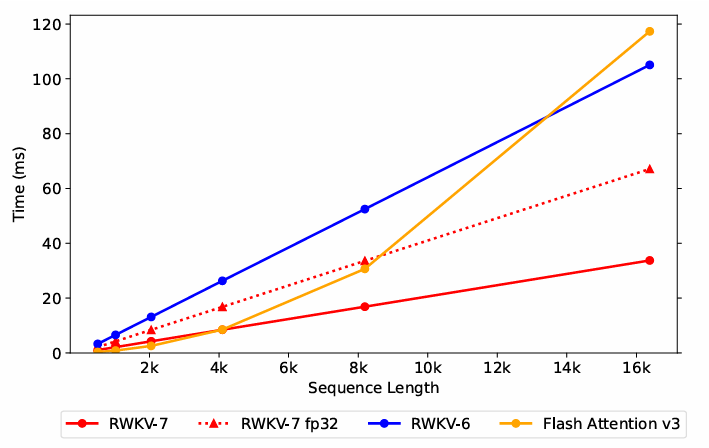
图6 推理时间随序列长度增长变化图
从图6可以看出,在序列长度超过约4000时,RWKV-7的推理效率要超过目前最快的Flash Attention v3,而序列越长,推理速度优势越大。同时,RWKV系列还具有推理所需内存不随序列长度增加而增加的性质。
RWKV-7如何做到的?
RWKV-7如何做到的?
(本部分参考了RWKV-7架构提出者彭博的知乎文章https://zhuanlan.zhihu.com/p/9397296254,按我的理解提高了可读性)
RWKV-7能做到这些的核心正是前文所说的第一性原理:模型的内部世界持续拟合外部世界。
首先回顾经典的Transformer所使用的QKV-softmax-attention,其数学形式如下,在本文中,如无特殊说明,向量默认为行向量:
对维度为D的输入向量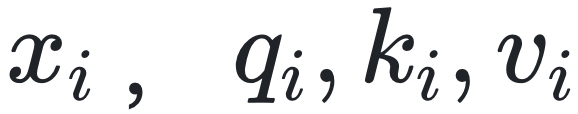 分别为
分别为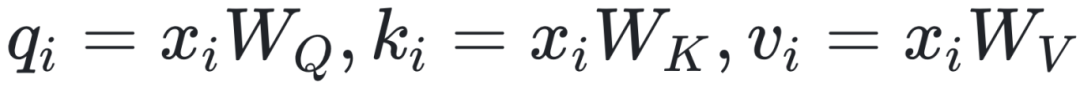 ,其中,
,其中,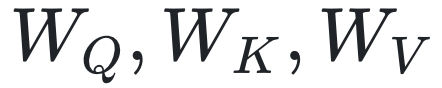 为D×D矩阵。将
为D×D矩阵。将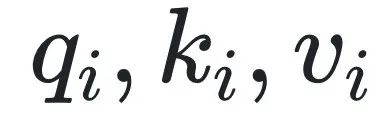 排列得到矩阵Q,K,V,即Q,K,V矩阵中第i行分别为
排列得到矩阵Q,K,V,即Q,K,V矩阵中第i行分别为 ,则输出为
,则输出为 。
。
这个式子实际上的目的是,对许多组(k1, v1), (k2, v2), …,给出一个q,使若q≈ki,则输出≈vi,若q≈(ki+kj)/2,则输出≈(vi+vj)/2(当然,attention机制并不追求精确寻找用k的线性组合表示q,在此仅为方便理解)。
一个很自然的想法是,如果学到了ki到vi的变换,就能在给出q的情况下,通过这一变换得到输出了,这也满足QKV-softmax-attention中若q≈ki,则输出≈vi,若q≈(ki+kj)/2,则输出≈(vi+vj)/2的性质。这一变换可根据(k1, v1), (k2, v2), …,动态进行学习。在这一视角下,这个变换就可以认为是模型的内部模型,持续拟合外部世界。
形式化的说,就是给定两组向量{kt}和{vt},RWKV-7会使用内模型S (一个线性变换,以矩阵形式表示)进行学习,目标是使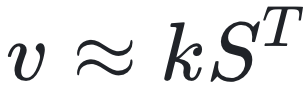 ,此时,对给定输入向量r(起QKV-softmax-attention中q的作用),输出为rST,在此使用v与kST间差值的平方,即L2损失作为目标,也就是
,此时,对给定输入向量r(起QKV-softmax-attention中q的作用),输出为rST,在此使用v与kST间差值的平方,即L2损失作为目标,也就是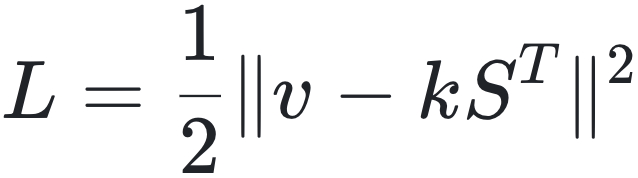 ,为最小化该损失,使用梯度下降更新内模型。计算梯度为
,为最小化该损失,使用梯度下降更新内模型。计算梯度为

则状态(内模型S)的更新公式为:

加入每维度权重衰减率wt及学习率ηt(均为向量),完整的内模型更新公式为:
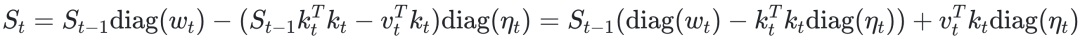
通过上式这种梯度下降的方式,内模型S可以持续减小v与kST间的误差,即可理解为持续拟合并适应外部世界的变化。
以上是RWKV-7的核心思想,也就是从模型的内部世界必须持续拟合外部世界这一想法出发得到的模型,当然还有许多重要的额外处理和周边组件,对此感兴趣的读者可以阅读论文,在此不再赘述。
总结与展望
总结与展望
RWKV-7这种”7代”架构还包括DeltaNet、Titans、TTT等等。彭博介绍,与这些架构相比,RWKV-7的优势是细节权衡更优,因此性能更好。后续还会有RWKV-8等性能更强的新架构。
本文简短介绍了RWKV-7架构的基本思想和达到的效果,若读者对此感兴趣,可阅读论文,其中的论述、结果要远比本文详细、丰富和深入。
在如今视角下回顾ChatGPT出现后大语言模型的发展,我认为,架构决定成本,一定程度上影响模型表现,而如何训练决定模型表现。
在2023年,大语言模型竞争刚刚拉开序幕时,有人认为架构已经确定,接下来就是拼算力和数据就行了。但事实证明,到如今,经典的全注意力架构远远不能满足大语言模型发展的需要。
从公开信息看,DeepSeek探索出了MLA、NSA架构,MiniMax-01使用的线性混合架构,谷歌Gamma3使用的滑动窗口注意力+全注意力混合架构,腾讯混元Turbo S使用的是Hybrid-Mamba-Transformer架构。可以看到,最近公开的新模型都不是纯粹的经典全注意力架构。
谷歌、OpenAI的闭源模型并未透露相关信息,但谷歌对新架构探索非常积极,提出了Titans等全新架构,不排除其Gemini的新模型是采用混合架构的可能;而OpenAI的GPT-4o有报道称其响应延迟是亚二次的,很可能是一种混合模型。
当然这里值得注意的是,与RWKV-7在诸如状态追踪等方面表达力高于全注意力架构不同,MLA、NSA等架构,虽然确有诸多优势,但其表达力是严格低于全注意力架构的。
实际上全注意力架构存在一个悖论:目前看,全注意力强在长上下文表现,但全注意力长上下文推理成本又过高,导致难以实际使用。目前业界对此的解决方案是使用混合架构,即线性注意力与全注意力混合,以降低长上下文推理成本。
我个人认为,这种混合模型还是一种过渡,最终还是会往以RWKV为代表的纯RNN/线性注意力架构进一步演进。因为随智能体应用的普及,模型更多不只是依赖自身能力完成任务,而是在可以调用外界资源、与外界进行交互的情况下完成任务。很多长上下文能力测试,如果允许模型编写程序解决,无疑是过于简单的,例如大海捞针任务。人也不能看一遍就记下几万字、几十万字的长文,但人可以通过记笔记、调用工具的方式完成许多远比这复杂的任务。人能写程序解决的问题,也算人能解决,模型也一样。
如果给模型一个虚拟环境,任务所需信息以文件形式存储,让模型可以在其中编写并调用程序,写入新的文件记录自身想法,也可随时查看记录的文件内容,这种环境中模型可以完成的任务是比单纯靠模型自己要多得多的。在这种情况下,记忆可以通过外部文件外置,即使过于久远的记忆不准确也可以接受,因为可以调用外部文件的记录来重温。但若模型推理成本越来越高,那即使在这种环境中,发挥也会很受限制,因为不能不受限制的写入和阅读外部文件。因此纯RNN/线性模型在此时是更占优势的。
实际上目前Aider、Cursor、Windsurf、Cline、auto-coder等AI编程工具的Agent(智能体)模式已经很接近这种形态了,但模型训练还没充分加强这方面能力。随智能体形态应用的进一步普及,显然业界在训练上会更加重视模型调用外界资源的能力,也会使得纯RNN/线性模型更能充分发挥其优势。
最后,以彭博的一句话结尾:
我们需要实现的,不是【人脑】,而是【人脑+外部工具】的整体效果。这是问题的关键。
致谢:感谢彭博、张锐翀、王婷对本文提出的宝贵意见。
作者简介:

AI+Science 读书会
6. 加入集智,一起复杂!
微信扫一扫,分享到朋友圈











