解释大语言模型:在 Alpaca 中识别因果机制

导语
斯坦福大学的 Alpaca 模型是用于学术研究的指令遵循语言模型(instruction-following language model)。在近日新发表的论文“解释大语言模型:在 Alpaca 中识别因果机制”中,研究者提出一种通用的因果机制发现框架,使用该工具,Alpaca 模型在简单的数字推理任务中实现了具有可解释中间变量的因果模型。这些因果模型对于输入和指令的变化具有鲁棒性。该框架也适用于拥有数十亿参数的大语言模型。

吴政璇 | 作者
论文题目:Interpretability at Scale: Identifying Causal Mechanisms in Alpaca
论文链接: https://arxiv.org/abs/2305.08809 作者:Zhengxuan Wu(吴政璇), Atticus Geiger, Christopher Potts, Noah Goodman
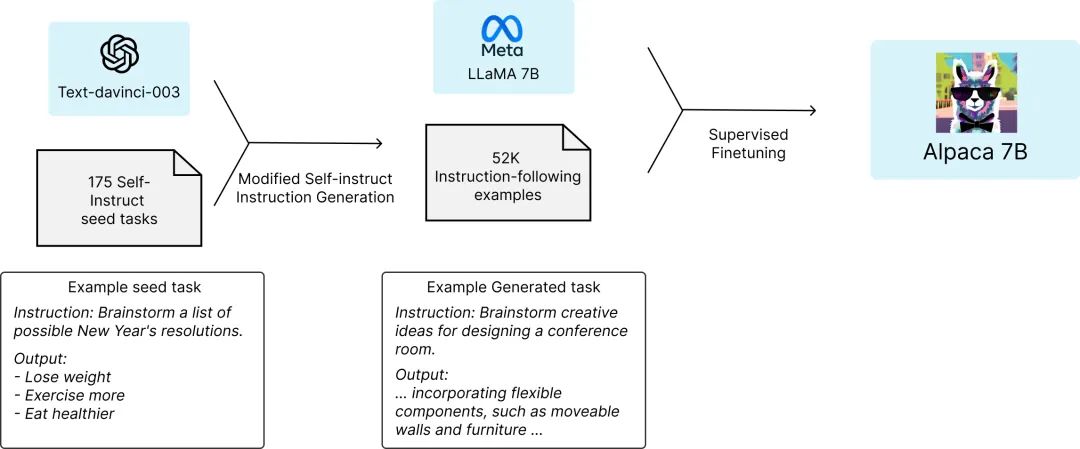
Alpaca 模型 https://crfm.stanford.edu/2023/03/13/alpaca.html
如何在大语言模型中寻找因果机制?
如何在大语言模型中寻找因果机制?
为什么要扩展(Scale)因果机制发现?
为什么要扩展(Scale)因果机制发现?
获取大型通用语言模型的具有鲁棒性的、易于理解的解释是人工智能领域的重要目标。目前的工具存在以下主要限制:
1. 搜索空间太大: LLM具有数十亿的参数,序列表示随长度增加而增加。神经元的搜索空间通常太大,无法使用任何启发式搜索工具。
2. 表达是分布式的: LLM中单个神经元的激活与概念 (concept) 之间的映射通常是多对多而不是一对一的。先前的工作声称一组神经元表示一个简单的概念(例如性别),可能是虚假的,因为神经元可以编码更复杂的内容(例如多个概念的叠加)。
将分布式因果机制的寻找转化为优化问题
将分布式因果机制的寻找转化为优化问题
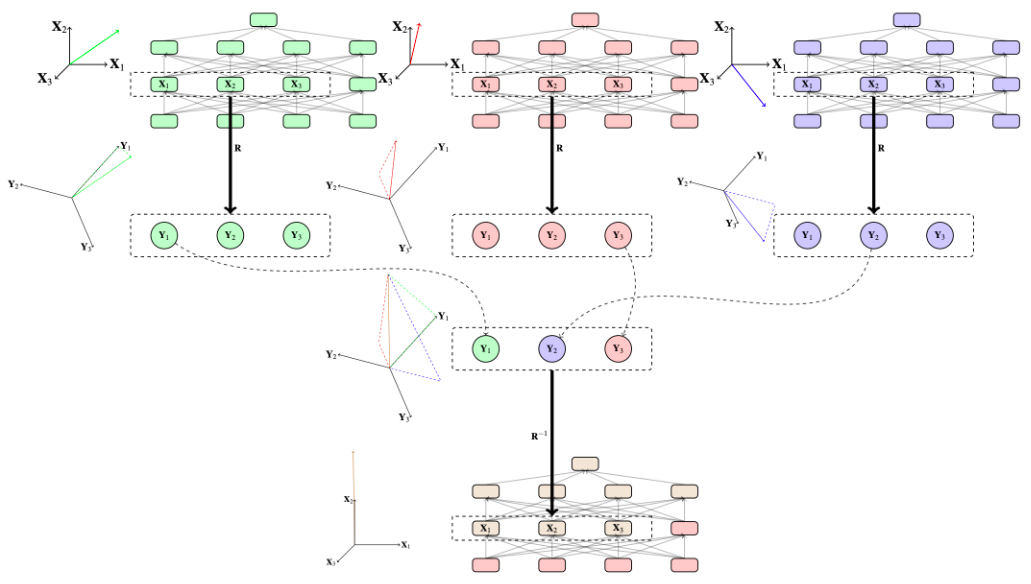
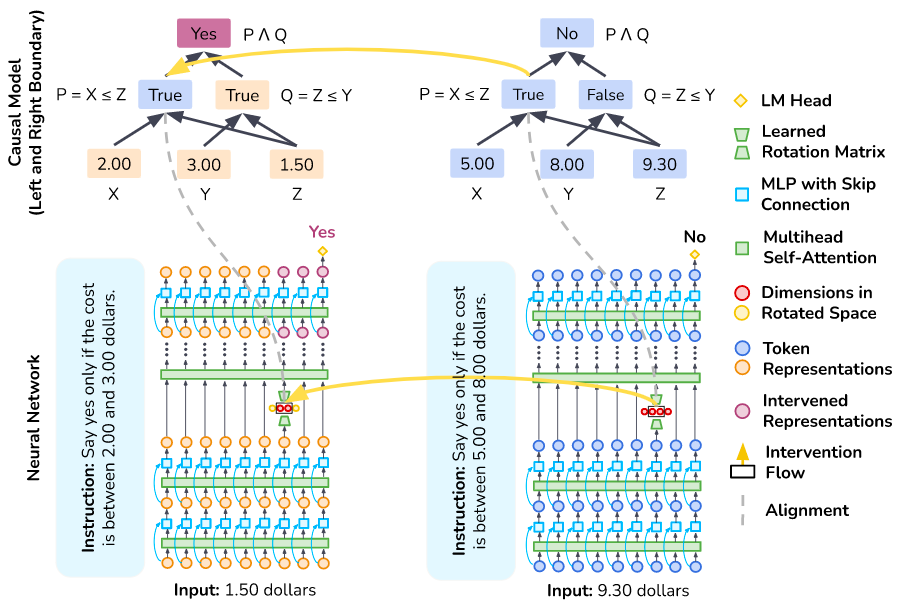
在本文中,我们通过用学习参数替换剩余的暴力搜索步骤,大幅度扩展这些方法,提出了DAS的更新版本 Boundless DAS 。以下是一些关键优势:
1. 将搜索转化为优化问题: 通过在旋转空间中进行干预,我们现在只需要检查是否可以学习一个忠实的旋转矩阵(有关忠实度统一度量,请参见下一节),以评估所提出的对齐方法。
Boundless DAS 代码
Boundless DAS 代码

统一的评估方式
统一的评估方式
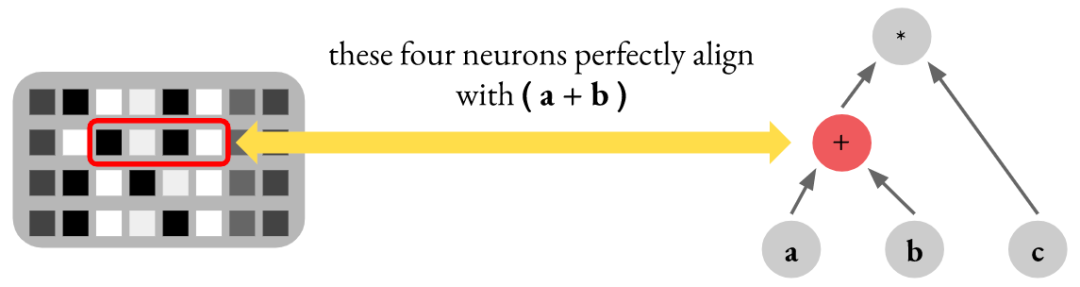
一个简单的数字推理任务
一个简单的数字推理任务


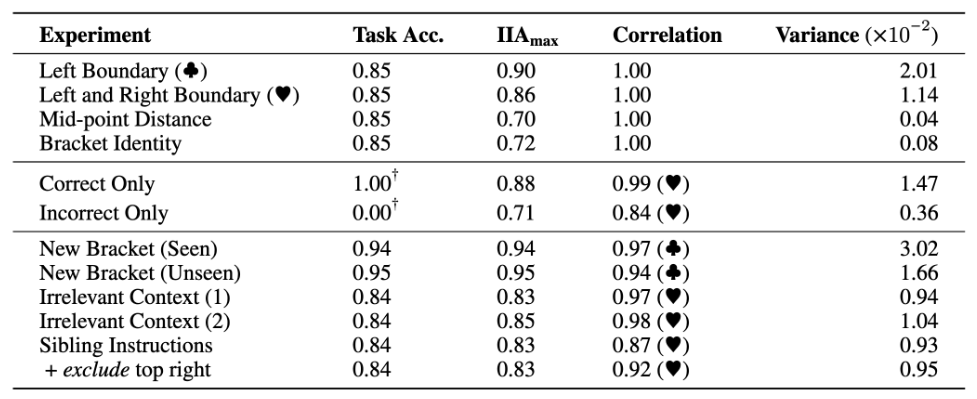
主要结果:模型遵循哪一种因果机制?
主要结果:模型遵循哪一种因果机制?
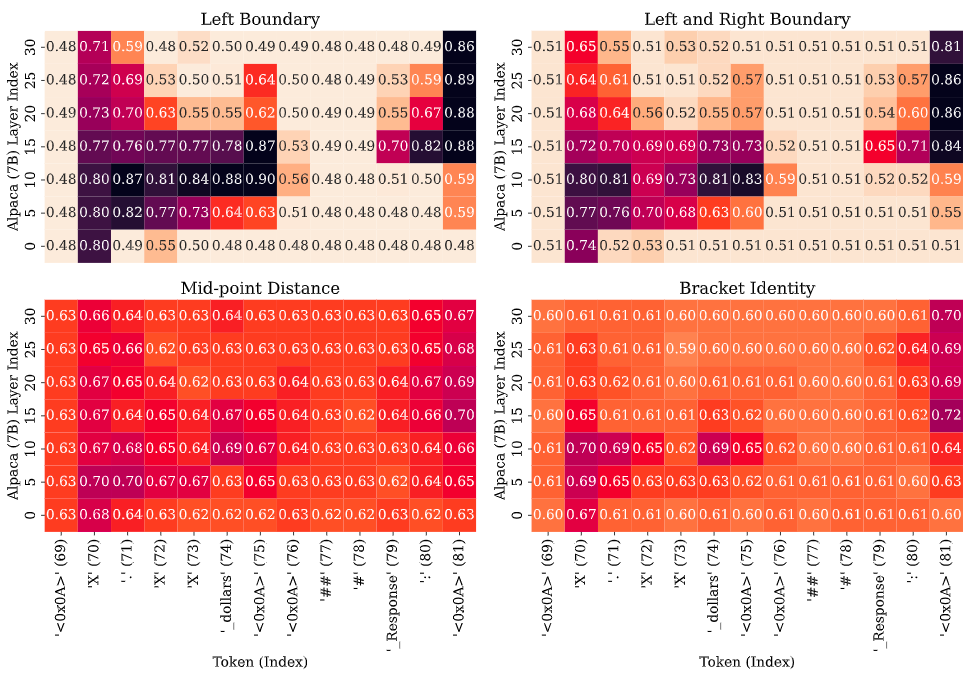
主要结果:找到的因果机制是否具有鲁棒性?
主要结果:找到的因果机制是否具有鲁棒性?
现在对于大模型的可解释性或者机制解释性 (mechanistic interpretability) 的方法的主要诟病,是找到的可解释性的结果可能仅适用于特定的输入-输出对设置。在本文中,我们试图探寻找到的可解释性是否具有很好的鲁棒性。
我们在不同的输入-输出设置的情况下无训练 (inference-time only) 的看发现的因果作用(即对齐方式)是否得到保留。这是至关重要的,因为它告诉我们因果模型在神经网络中的实现是否具有鲁棒性。我们研究了三种设置:
1. 新的输入: 在测试的时候,我们改变了问题中的最大和最小值。
2. 插入无关的信息: 我们在测试时注入随机上下文以评估对齐方式。
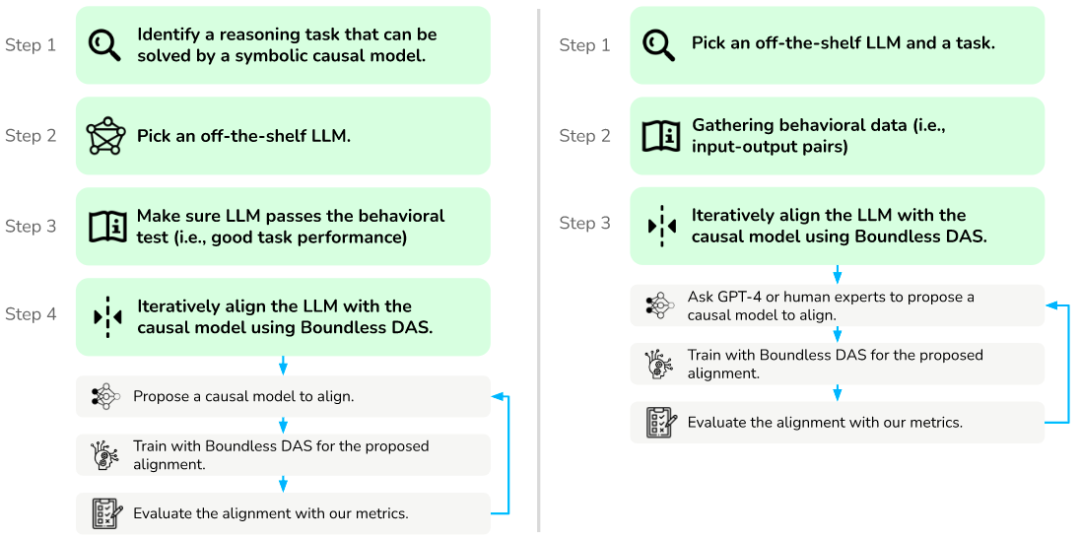
可解释性的愿景
可解释性的愿景
局限性讨论
局限性讨论
1. 更大的规模: 我们希望我们的框架可以应用于研究最强大的LLMs(例如175B的GPT-3或GPT-4)。在发布时,因为当前的工作仍然集中在一个简单的推理任务上,较小的LLMs可以解决。
2. 确定的因果模型: 我们的工作依赖于先验已知的因果模型,在许多实际应用中这是不现实的,因为高级因果模型也是隐藏的。未来的工作可以通过基于启发式的离散搜索或甚至端到端优化来研究学习因果图的方法。
3. 最终的可扩展性: 我们方法的可扩展性仍然受到搜索空间隐藏维度大小的限制。现在无法在LLMs的一组令牌表示上进行搜索,因为随着隐藏维度的增长,旋转矩阵呈指数增长。
4. 没有确凿的答案: 我们的评估范例可以根据IIA提出对齐方式(即灰盒),但无法对失败的对齐方式进行确定性推断。
原文链接: https://nlp.stanford.edu/~wuzhengx/boundless_das/cn_index.html
因果表征学习读书会
随着“因果革命”在人工智能与大数据领域徐徐展开,作为连接因果科学与深度学习桥梁的因果表征学习,成为备受关注的前沿方向。以往的深度表征学习在数据降维中保留信息并过滤噪音,新兴的因果科学则形成了因果推理与发现的一系列方法。随着二者结合,因果表征学习有望催生更强大的新一代AI。集智俱乐部组织以“因果表征学习”为主题、为期十周的读书会,聚焦因果科学相关问题,共学共研相关文献。欢迎从事因果科学、人工智能与复杂系统等相关研究领域,或对因果表征学习的理论与应用感兴趣的各界朋友报名参与。

“后ChatGPT”读书会

推荐阅读
微信扫一扫,分享到朋友圈











