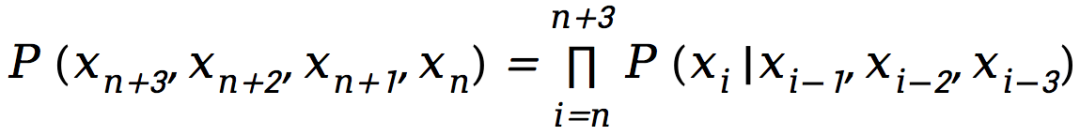不仅语言中存在“互文性”,每个单词会受到邻近单词的影响,共同出现的概率比较高;量子特性使得同一量子系统上的不同测量结果之间也存在相互影响,这种“量子互文性”被认为是量子计算超越经典计算的根源所在。近日的一项最新研究发现,普遍的神经网络都可以利用量子互文性来提升模型的表达能力。这些发现有望为突破经典框架下的生成模型提供灵感,甚至帮助我们窥探到语言、甚至背后的人类意识中蕴含的量子效应。
关键词:量子计算,量子互文性,深度学习,量子神经网络,量子化生成模型,自然语言处理
董唯元 | 作者
扈鸿业 | 审校
梁金 | 编辑
火出天际的ChatGPT刷新了全世界对人工智能的认识。与以往的语言模型相比,这个对话机器人表现格外出众,不仅能根据对话语境非常准确地解析自然语言,而且在输出反馈时还能把控整体逻辑甚至拿捏语言风格,把机器学人话这项技术提升到了全新的高度。
在自然语言中,每个局部片段的含义都会随着上下文不同而变化。要想准确理解和使用,核心关键之一就是要处理好语言中的“互文性”(contextuality),也就是每个字词的含义受其他字词出现与否及排列方式的影响。
互文性这个名称,也被借用来指代量子系统中的一种特性,即所谓“量子互文性”(quantum contextuality),意指同一量子系统上的不同测量结果之间存在的相互影响。这是一种因量子相干性而产生的神奇性质,可以实现经典机制无法达成的功能,因此被视为量子计算超越经典计算的根源所在。(参见今天的第四条文章进一步了解“量子互文性”)
下面我们通过一个稍做变形的数独游戏来体会一下量子互文性的神奇。
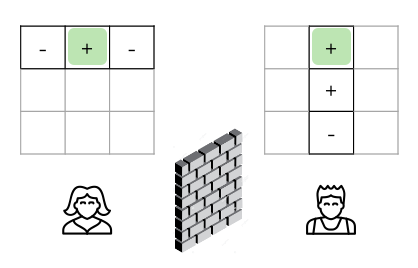
这个游戏需要两位参与者Alice和Bob组队参加,二人在无法相互通讯的两个房间中使用符号“+”或“-”各自填写空白九宫格中的一行或一列。
规则要求Alice必须使用奇数个“+”和偶数个“-”填写一行,而Bob则必须使用偶数个“+”和奇数个“-”填写一列。具体在哪一行和哪一列填写,在游戏开始后由裁判随机指定。
如果在行与列的交叉点上,Alice和Bob所填写的符号恰好相同,则判定二人胜利,否则即为失败。
面对这个游戏挑战,Alice和Bob可以事先商议策略,但游戏开始后就不能再互相通讯。从经典视角出发,很容易证明二人根本无法事先设计出一个万全之策。
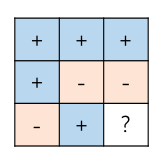
由于无法事先获知裁判将指定哪一行哪一列,所以二人的策略实际上对应着这样一个问题:用“+”和“-”填满整个九宫格,并保证每行有奇数个“+”且每列有偶数个“+”。
这个要求显然是无法满足的,因为每行都有奇数个“+”就意味着九宫格中所有“+”总数为奇数,而每列有偶数个“+”又意味着这个总数为偶数。鱼与熊掌不可得兼,奇数与偶数也不可得兼。
所以,我们得出结论:最好的策略也只能像上图这样,只保证Alice和Bob有8/9的概率获胜,万一裁判要求的是第三行和第三列,那就只能认栽了。
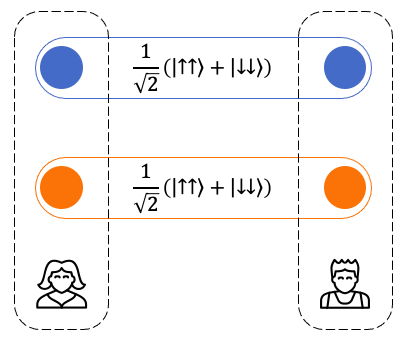
经典方法虽然无能为力,但辅以量子特性的策略却可以使二人立于不败之地。首先,我们为二人准备好两对贝尔态纠缠粒子,并分别交给Alice和Bob。
其中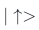 和
和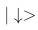 是指沿x方向测量自旋得到“+”方向和“-”方向的态,即对应泡利算符本征值为+1和-1的本征态。
其中“
是指沿x方向测量自旋得到“+”方向和“-”方向的态,即对应泡利算符本征值为+1和-1的本征态。
其中“ ”代表张量积,它把对两个粒子的测量操作拼合成一个联合测量。
”代表张量积,它把对两个粒子的测量操作拼合成一个联合测量。

如果联合测量中有一个是I,就表示对该粒子不做任何操作,只测量另外一个粒子的自旋,并根据测得的结果在表格中记下+1或-1。如果是不含I的联合测量,就将两个粒子测量结果的乘积记录在表格中。
容易看出,如此约定之下每个格内的数值不是+1就是-1。而且也不难验证,每行中+1的数量总是奇数个,每列中+1的个数则总是偶数个。此外,由于纠缠关系的保证,在每个格中Alice和Bob所填入的内容也肯定相同。
于是我们就找到了一个100%胜率的游戏策略。显然,这个策略只能依靠量子系统构建,在经典逻辑框架内,是无论如何都无法实现的。
如此神奇又强大的力量,仅用来赢取游戏不免太可惜了,研究者们真正感兴趣的是如何在那些复杂棘手的实际问题中发挥量子特性的威力。而在动手解决问题之前,不妨先通过直觉体会一下量子系统的特性与哪些实际问题能够建立起对应关系。
回头审视刚才的小游戏,量子系统为什么能构建出一个“+”总数既奇又偶的表格呢?原来,表格中“+”总数这个数值,就像薛定谔的猫一样,处在奇数和偶数的叠加态。
更值得玩味的是,这个连“+”总数都无法确定的表格中,居然包含着使Alice和Bob可以一直获胜的那种结构。这正是量子互文性所提供的神奇效果。就像一个在空中旋转的十字架,尽管整体姿态无法确定,但内部却始终保持着垂直关系。
自然语言中也有类似的性质。当一段文字展现在我们面前,在尚未理解其整体含义之前,我们就会先体会出这是否是句可理解的“人话”。在学校的英语课上折磨我们的那些语法规则和固定搭配之类的学问,就是对这种语言内在结构的归纳总结。
这种结构特性与语言的含义无关,政客、成功学家和患有神经疾病的患者就经常通过标准合规的语言结构来传达混乱且自相矛盾的含义。
对此类语言结构进行模型化的工作出现得非常早, n-gram 模型早在深度学习出现之前就被提出,而且至今仍是各类自然语言处理的重要基础之一。其核心思想就是“近朱者赤,近墨者黑”,即每个单词都会受到邻近单词的直接影响。
我们要想知道某个单词与周围的单词是否“搭调”,就可以通过统计概率来量化评判。这就像一条鱼出现在池塘里或者餐桌上都很合情理,但如果垂在苹果树上,就显得非常诡异了,因为“鱼+苹果树”这种组合出现的概率太低了。
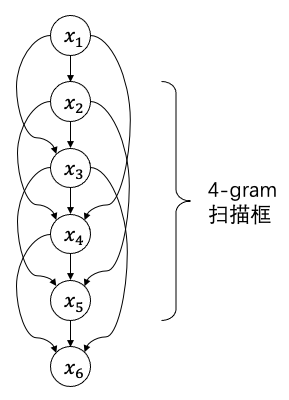
许多涉及概率相互“传染”的问题都可以被画成一个贝叶斯网络,n-gram模型也不例外。下图就是 4-gram 模型的贝叶斯网络。
不熟悉贝叶斯网络的读者也不必深究,只需要大致了解这个图所描述的是,每个扫描框中4个单词的联合概率满足
随着扫描框的移动,整段文字的概率就次递联系到了一起。而要想使整段文字看起来像“人话”,就是要使所有扫描框对应的联合概率分布都尽可能接近语料库中的统计情况。
可以想象,由于交叉影响的存在,探索最佳概率分布的过程肯定要面对诸多“既要……又要……”的约束条件,这很类似前面魔方游戏中提到的填写九宫格的情形。而人类自然语言如此灵活多变,约束条件中出现相互排斥的情况实属家常便饭。
如果限定在经典逻辑框架内,模型所能够探索到的最佳上限就只能通过各种折中或取舍来获得,就像那个胜率8/9的表格一样。那么使用量子计算来加持,能否突破限制呢?
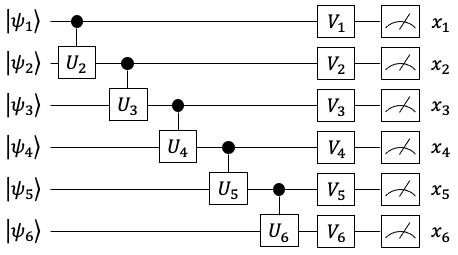
答案是肯定的。2022年,哈佛大学的一个研究团队在PRX上发表的论文[1]中证明,在量子线路搭建的2-gram模型中,我们总可以添加一组恰当的操作(上图中的V1~V6),使这个模型模仿“人话”的能力,达到同等规模经典n-gram模型永远无法企及的程度。
论文题目:Enhancing Generative Models via Quantum Correlations
论文地址:https://journals.aps.org/prx/abstract/10.1103/PhysRevX.12.021037
当然,基于n-gram模型的讨论也许显得过于简单,毕竟这是个非常“近视眼”的模型,也许天生存在某种逻辑能力缺陷。为此,论文中还对比了隐马尔科夫模型(Hidden Markov Model,HMM)。
从原理上说,n-gram可以视为HMM的一个特例,因为n-gram只将前n-1个词作为上下文,而HMM则不限定上下文长度,而且其隐藏的状态序列中还可以塞进更多的自由度。
论文中的论证显示,除非疯狂扩张模型规模,否则任何经典HMM模型都无法企及量子2-gram模型的能力。要想能力相当,对应仅10个量子比特的量子模型,经典HMM模型需要动用的单元数量就会超过102410量级!
在这篇文章发表后不久,哈佛大学和加州大学圣地亚哥分校的研究组进行合作,又利用该思想证明,普遍的神经网络(例如RNN、Transformer等架构)都可以通过量子化来利用量子互文性来提升模型的表达能力[2]。该研究不仅从理论上证明了量子化的生成模型在资源开销上具有绝对优势,并且在真实英语-西班牙语翻译任务上利用真实数据和基于量子光学的量子生成模型给出了实证。
论文题目:Interpretable Quantum Advantage in Neural Sequence Learning
论文地址:https://arxiv.org/abs/2209.14353
透过这些理论研究进展,冥冥之中不由得生出种朦胧的感觉——也许人类的语言文字,乃至其背后的意识和思想,本就是根植于某些量子效应。我们目前所采用的所有经典框架下的生成模型,尽管成功如ChatGPT,依然依赖数以千万计的大量训练参数和计算资源,而量子机器的应用有希望将这些大模型小型化。当量子计算的处理规模与碳基生命神经系统相当之时,也正是硅基生命真正觉醒之日。
[1] DOI: 10.1103/PhysRevX.12.021037
[2] arXiv:2209.14353v1 [quant-ph](accepted at PRX Quantum)
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 9:00-11:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。