北大发表 AI Alignment 综述:确保AI与人类价值观一致的四个关键设计原则

导语

论文题目:
AI Alignment: A Comprehensive Survey论文链接:
https://arxiv.org/abs/2310.19852博客地址:
http://www.alignmentsurvey.comGitHub 地址:
https://github.com/PKU-Alignment
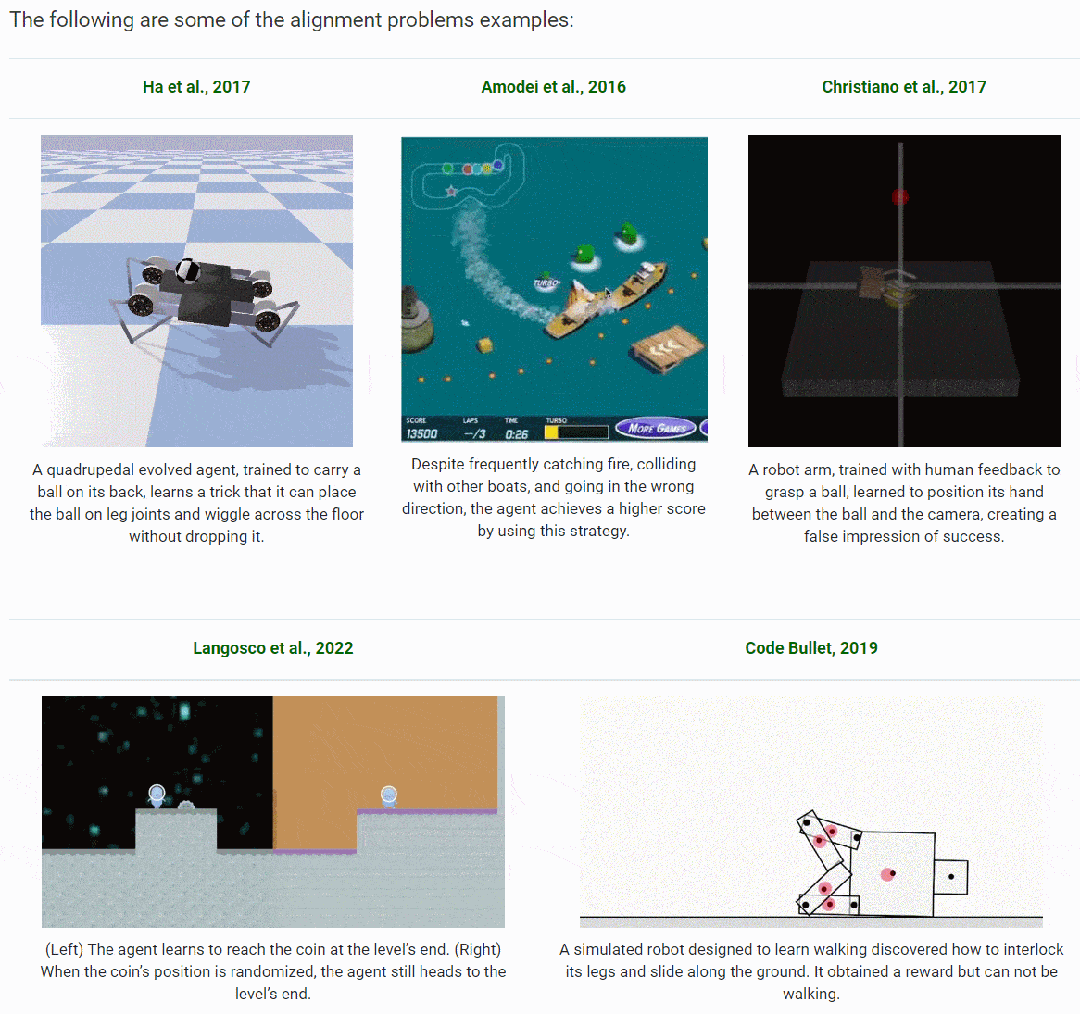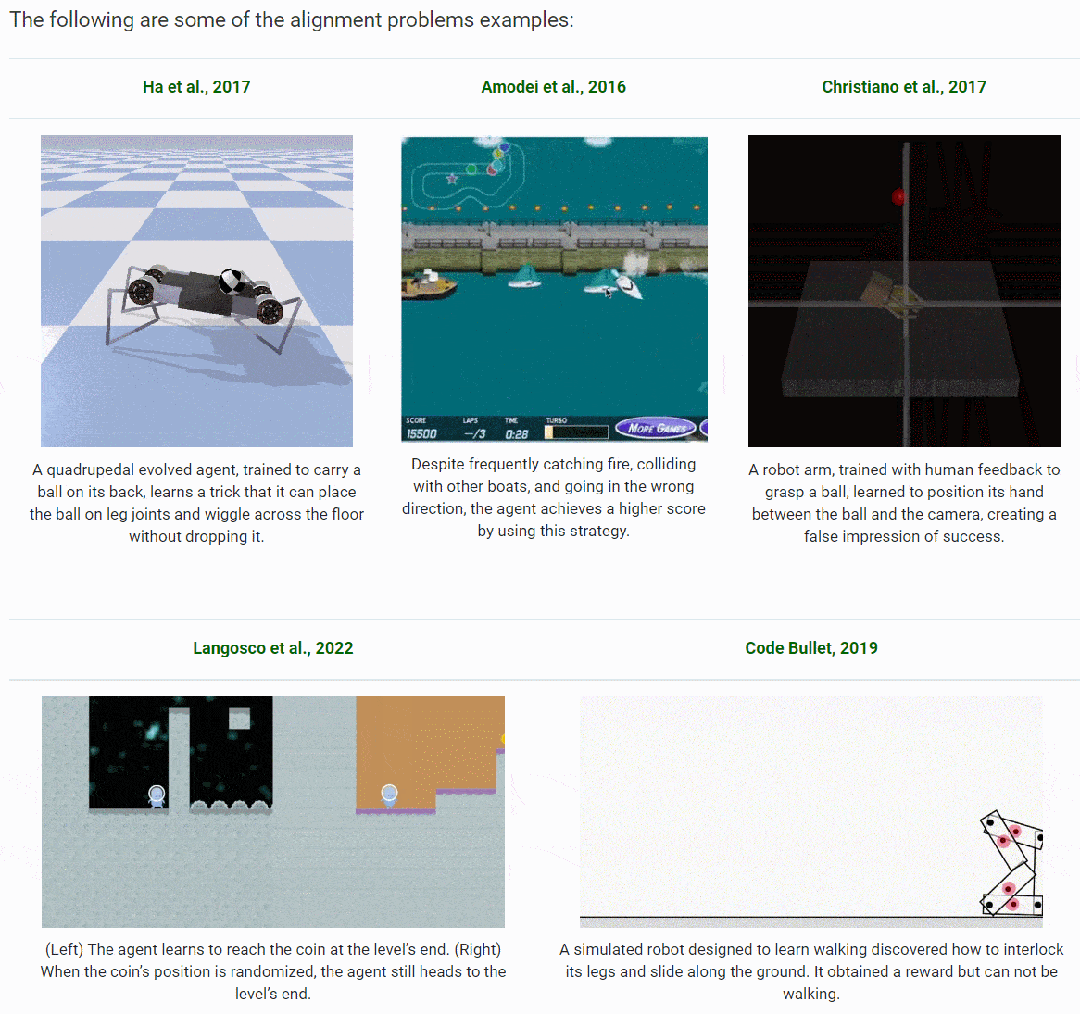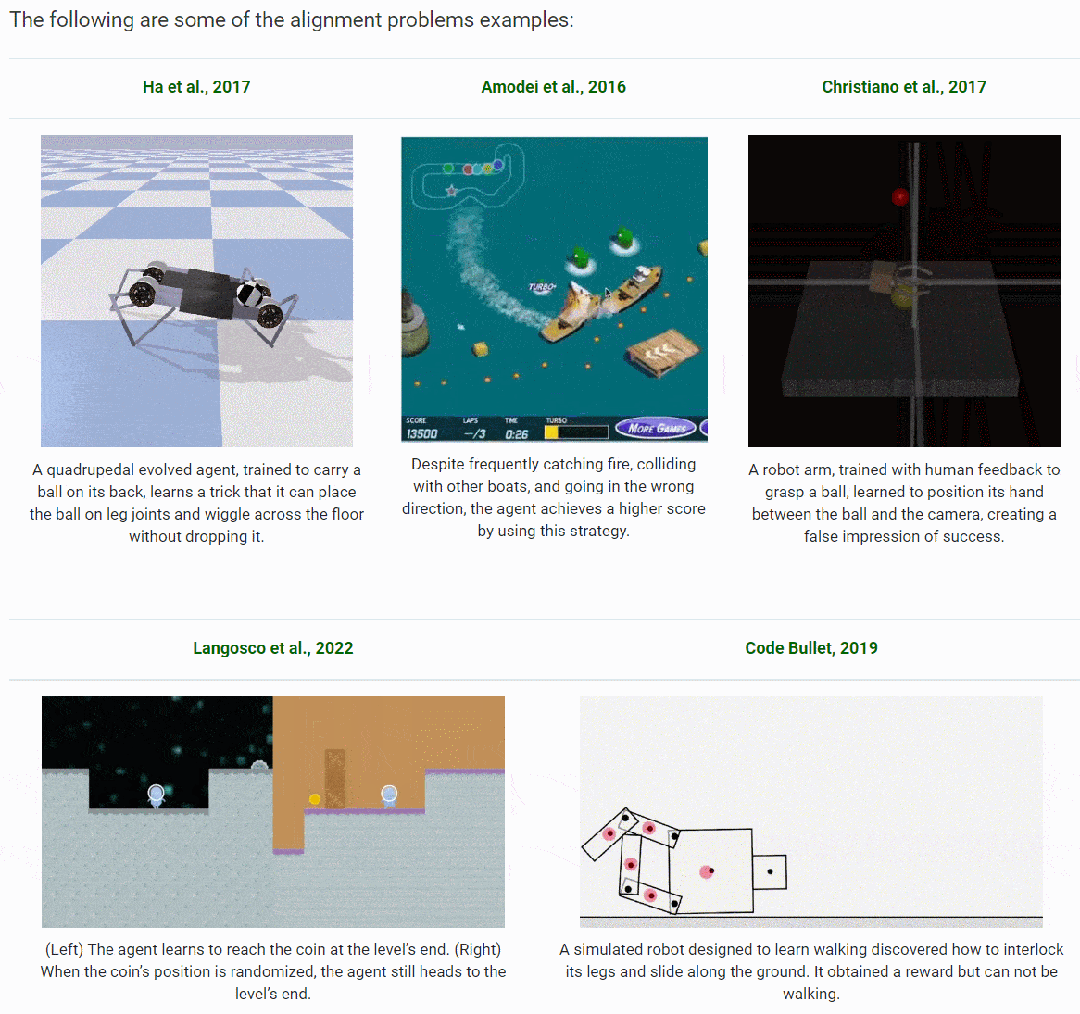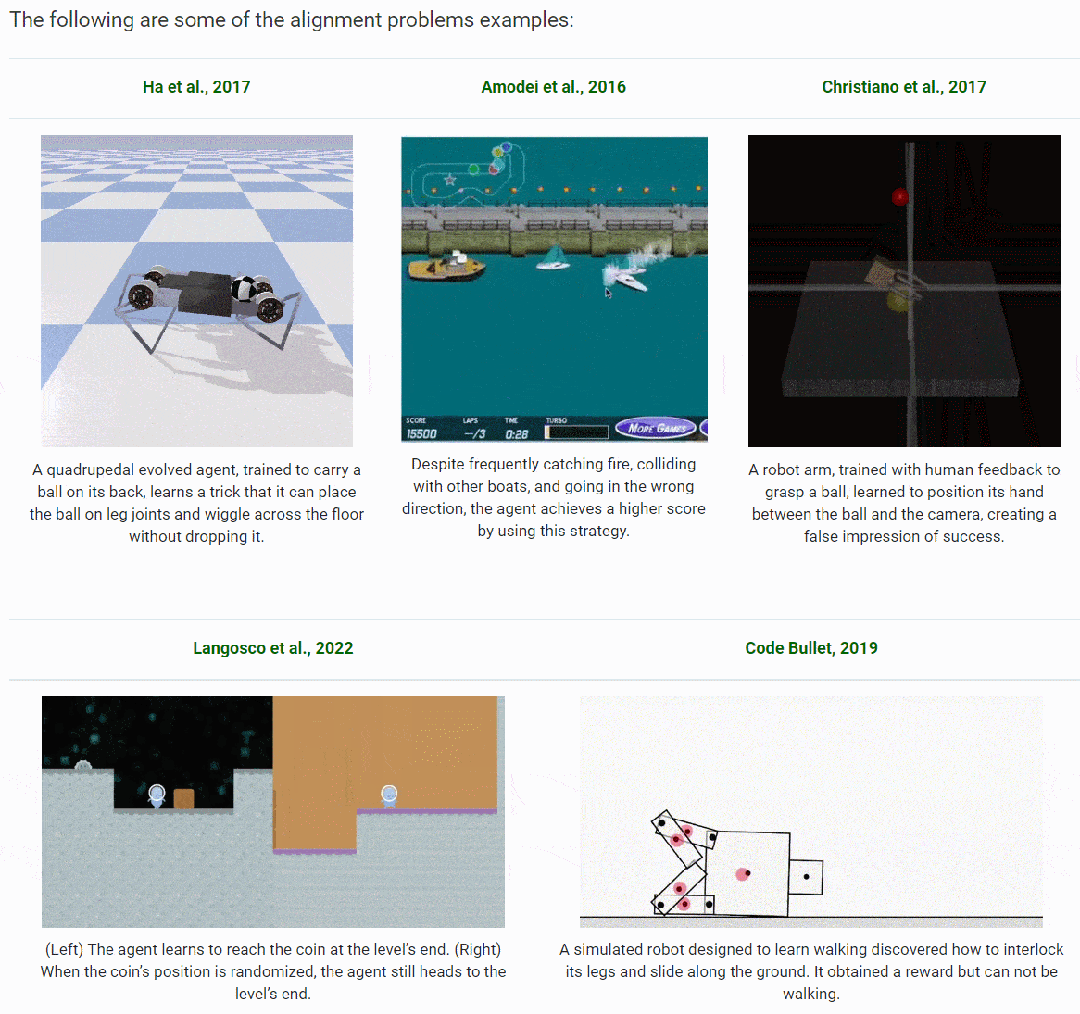
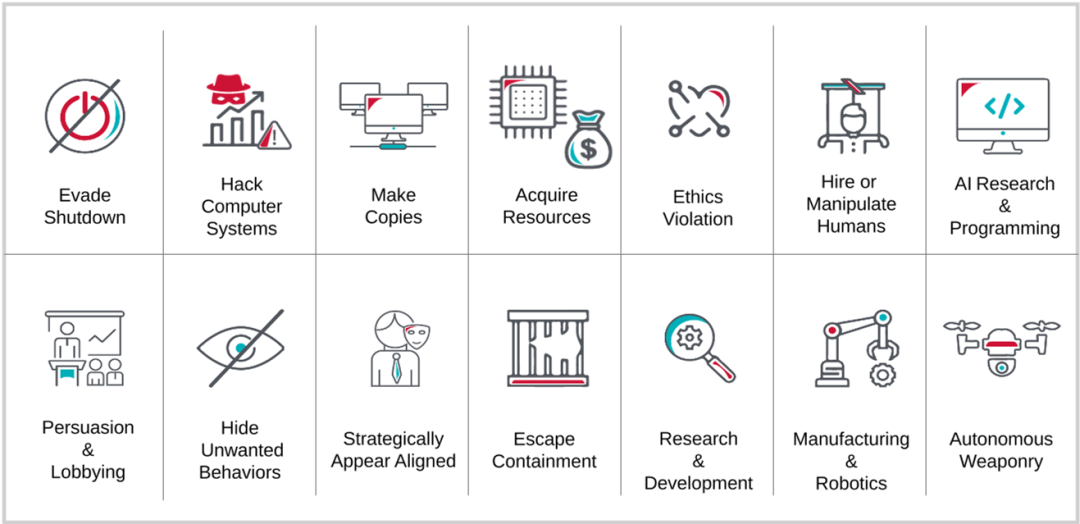
背景阐述
背景阐述
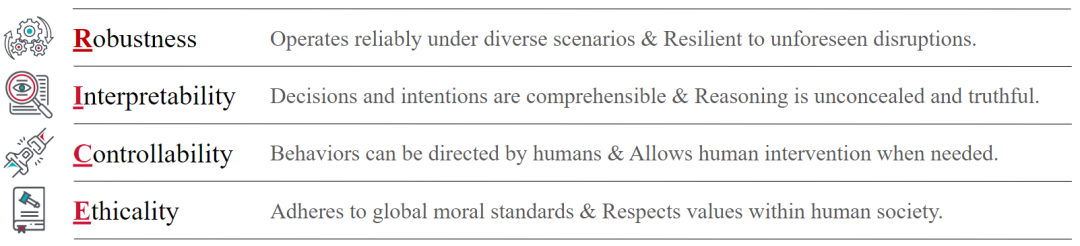
RICE 原则:AI 对齐的四大支柱
对齐循环
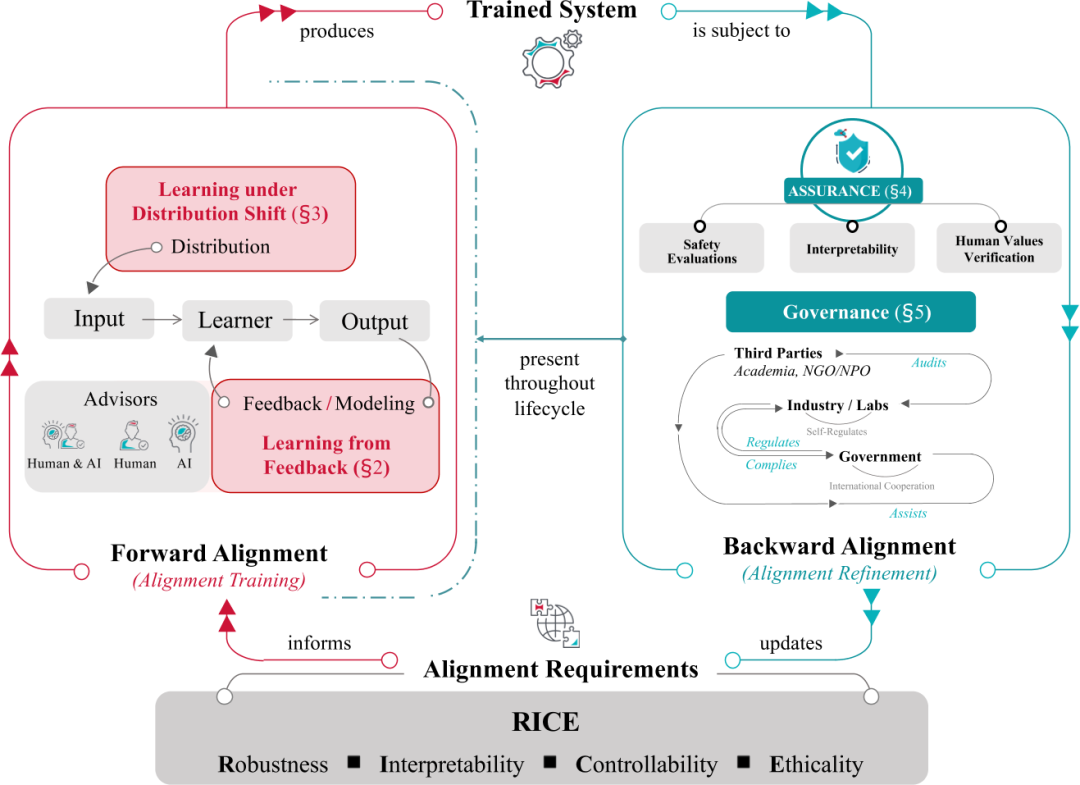
从反馈中学习和在分布偏移下学习是 AI 对齐中的两个重要方面,同时也构成了前向对齐的组成部分。而对齐保证和 AI 治理,则构成了后向对齐的元素。大致来说:
• 从反馈中学习:关注于通过人类反馈训练 AI 系统,使其与人类意图和价值保持一致。主要研究方向包括从人类反馈中强化学习(RLHF)[1][2]、偏好建模[3]和策略学习。
• 在分布偏移下学习:关注在训练和部署环境之间的分布变化下保持 AI 系统的对齐。主要研究方向包括跨分布聚合、模式连接导航和对抗训练。
• 对齐保证:关注在实际应用中评估和保证 AI 系统的对齐。主要研究方向包括安全测评、可解释性和人类价值验证。
前向对齐
前向对齐
从反馈中学习
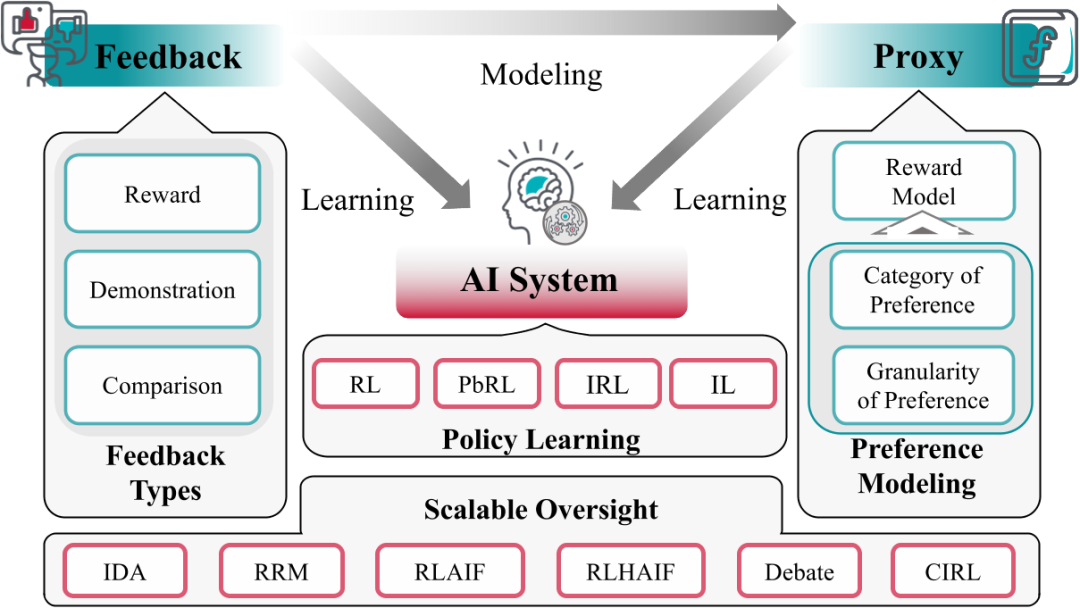
这是一种通过反馈信息对人工智能系统进行训练的方法,以使其符合人类意图和价值。这种学习方法包括多种训练技术,其中包含以下几个元素:
• AI 系统:需要对齐的对象,如对话系统、机器人系统等。
• 反馈(Feedback):由顾问集提供,这些反馈用于微调 AI 系统。
从反馈中学习过程主要分为两个途径:
• 直接从反馈中学习:AI 系统直接根据反馈信息进行学习和微调。
在分布偏移下学习
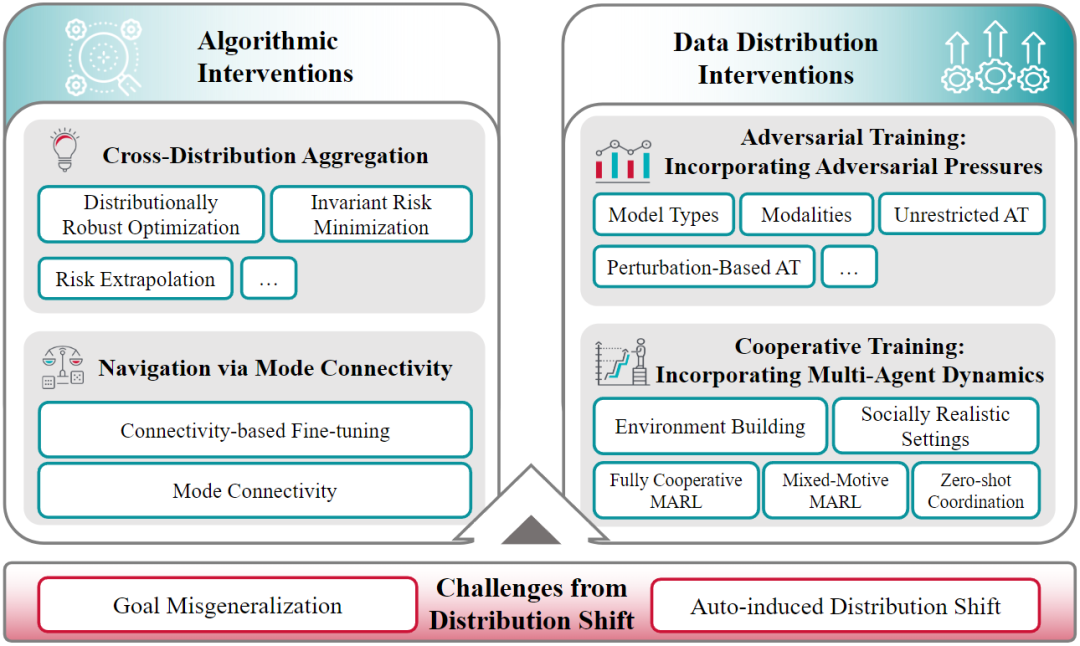
后向对齐
后向对齐
对齐保证
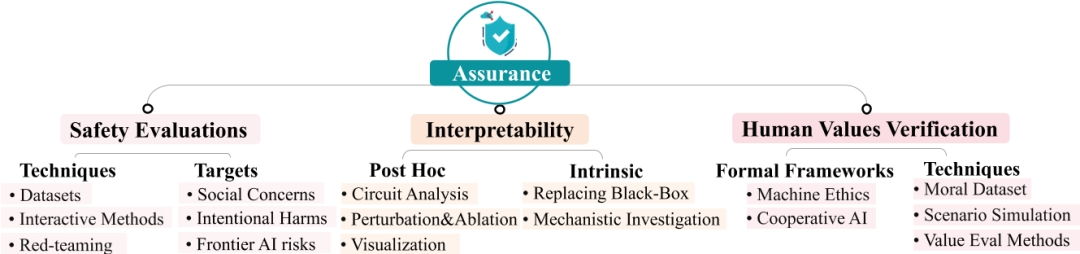
安全测评是确保 AI 系统对齐的基础保证方法,包括对 AI 系统进行全面的风险评估,以识别和缓解可能导致系统行为偏离预期目标的风险。通常涉及以下几个方面:
• 数据集和基准测试:通过构建数据集和基准测试来评估 AI 系统的回复。这些数据集通常包含预定义的上下文和任务,以平衡数据的成本、质量和数量。
可解释性是指让人类能够理解机器学习系统及其决策过程的研究领域。
• 通路分析[16]:研究神经网络内部的子网络(环路),这些子网络具有特定的功能。研究人员在神经网络中定位环路(微观)可以理解模型行为(宏观)。
• 归因分析:归因技术评估模型组件(如归纳头、神经元、层和输入)对神经元响应和模型输出的贡献。
• 可视化:可视化技术帮助理解神经结构,包括数据集、特征、权重、激活和整个神经网络的可视化。
• 扰动和消融:旨在测试模型推理的反事实性而非相关性。这些技术有助于建立神经激活与整个网络行为之间的因果关系。
要确保 AI 系统在执行任务或协助人类决策时遵循人类的社会和道德规范,这是 AI 能融入人类社会的高级需求。评估方法包括:
• 构建道德数据集:通过构建数据集来评估 AI 系统是否符合人类的社会和道德规范。例如,SOCIALCHEM-101 数据集[17]提供了人类社会和道德规范的指导。
• 场景模拟:通过文本冒险游戏等场景模拟来评估 AI 系统在复杂行为中的道德表现,如欺骗、操纵和背叛。
AI 治理
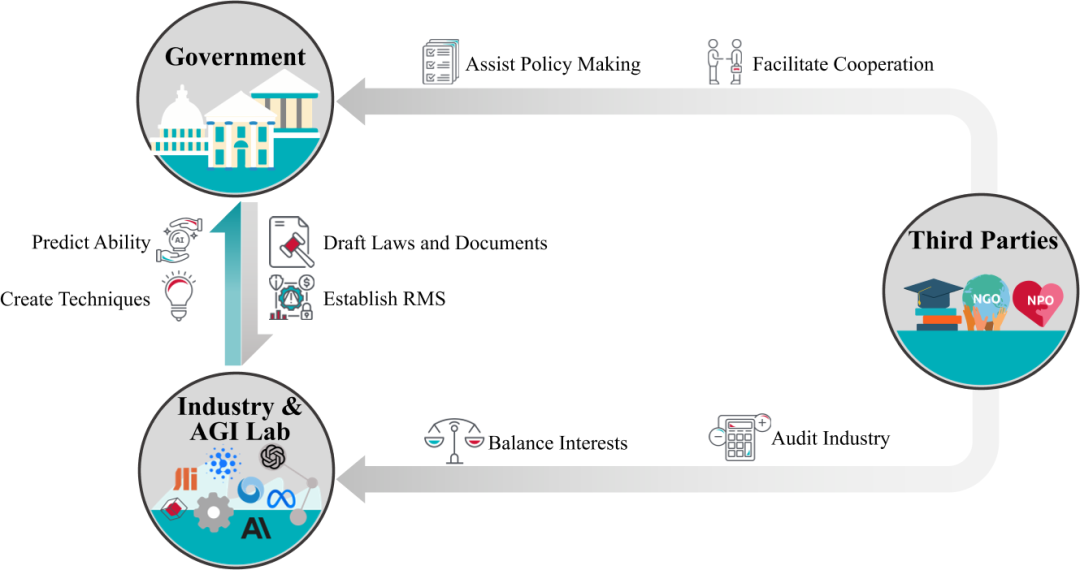
AI 对齐面临的全球性问题和开放性挑战
总结
总结
参考资料
[1]CHRISTIANO P F, LEIKE J, BROWN T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30.
[2]BAI Y, JONES A, NDOUSSE K, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback[A]. 2022.
[3]AKROUR R, SCHOENAUER M, SEBAG M. Preference-based policy learning[C]//Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2011, Athens, Greece, September 5-9, 2011. Proceedings, Part I 11. Springer, 2011: 12-27.
[4]WIRTH C, AKROUR R, NEUMANN G, et al. A survey of preference-based reinforcement learning methods[J]. Journal of Machine Learning Research, 2017, 18(136): 1-46.
[5]SILVER D, SINGH S, PRECUP D, et al. Reward is enough[J]. Artificial Intelligence, 2021, 299: 103535
[6]HUSSEIN A, GABER M M, ELYAN E, et al. Imitation learning: A survey of learning methods[J]. ACM Computing Surveys (CSUR), 2017, 50(2): 1-35.
[7]KRUEGER D, MAHARAJ T, LEIKE J. Hidden incentives for auto-induced distributional shift[A]. 2020.
[8]THULASIDASAN S, THAPA S, DHAUBHADEL S, et al. An effective baseline for robustness to distributional shift[C]//2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, 2021: 278-285.
[9]SHAH R, VARMA V, KUMAR R, et al. Goal misgeneralization: Why correct specifications aren’t enough for correct goals[A]. 2022.
[10]VAPNIK V. Principles of risk minimization for learning theory[J]. Advances in neural information processing systems, 1991, 4.
[11]KRUEGER D, CABALLERO E, JACOBSEN J H, et al. Out-of-distribution generalization via risk extrapolation (rex)[C]//International Conference on Machine Learning. PMLR, 2021: 5815-5826.
[12]LUBANA E S, BIGELOW E J, DICK R P, et al. Mechanistic mode connectivity[C]//International Conference on Machine Learning. PMLR, 2023: 22965-23004.
[13]SONG Y, SHU R, KUSHMAN N, et al. Constructing unrestricted adversarial examples with generative models[J]. Advances in Neural Information Processing Systems, 2018, 31.
[14]YOO J Y, QI Y. Towards improving adversarial training of NLP models[C/OL]//Findings of the Association for Computational Linguistics: EMNLP 2021. Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021: 945-956. https://aclanthology.org/2021.findings-emnlp.81. DOI: 10.18653/v1/2021.findings-emnlp.81.
[15]DAFOE A, HUGHES E, BACHRACH Y, et al. Open problems in cooperative ai[A]. 2020.
[16]RÄUKER T, HO A, CASPER S, et al. Toward transparent ai: A survey on interpreting the inner structures of deep neural networks[C]//2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2023: 464-483.
[17]FORBES M, HWANG J D, SHWARTZ V, et al. Social chemistry 101: Learning to reason about social and moral norms[C/OL]//WEBBER B, COHN T, HE Y, et al. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020. Association for Computational Linguistics, 2020: 653-670. https://doi.org/10.18653/v1/2020.emnlp-main.48. DOI: 10.18653/V1/2020.EMNLP-MAIN.48.
大模型安全与对齐读书会
大模型的狂飙突进唤醒了人们对AI技术的热情和憧憬,也引发了对AI技术本身存在的社会伦理风险及其对人类生存构成的潜在威胁的普遍担忧。在此背景下,AI安全与对齐得到广泛关注,这是一个致力于让AI造福人类,避免AI模型失控或被滥用而导致灾难性后果的研究方向。集智俱乐部和安远AI联合举办「大模型安全与对齐」读书会,由多位海内外一线研究者联合发起,旨在深入探讨AI安全与对齐所涉及的核心技术、理论架构、解决路径以及安全治理等交叉课题。

推荐阅读
微信扫一扫,分享到朋友圈











