无心插柳:苏联数学家柯尔莫哥洛夫与神经网络的新生

编者按
早期神经网络的发展
早期神经网络的发展

罗森布拉特和他的感知机(Frank Rosenblatt,1928-1971)。图源:维基百科

其实罗森布拉特此前也已预感到感知机存在局限,特别是在“符号处理”方面,并以自己神经心理学家的经验指出,某些大脑受到伤害的人也不能处理符号。但感知机的缺陷被明斯基以一种敌意的方式呈现出来,对罗森布拉特是个致命打击。最终,政府资助机构也逐渐停止对神经网络研究的支持。1971年,罗森布拉特在43岁生日那天划船时溺亡,有说法认为这是自杀。


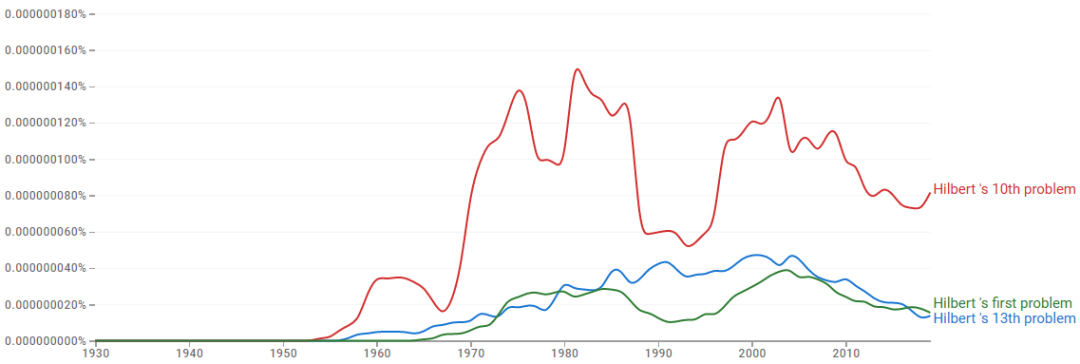
希尔伯特第13问题与神经网络
希尔伯特第13问题与神经网络
我们知道5次以上的方程是没有求根公式的。但一元5次和6次方程可以分别变换为:
爱尔兰数学家哈密尔顿1836年证明7次方程可以通过变换简化为:
在罗森布拉特做感知机(Perceptron)的同时,柯尔莫哥洛夫和阿诺德正在研究“叠加”问题。柯尔莫哥洛夫1956年首先证明任意多元函数可用有限个三元函数叠加构成。阿诺德在此基础上证明两元足矣。他们的成果被称为柯尔莫哥洛夫-阿诺德表示定理,或柯尔莫哥洛夫叠加定理,有时也被称为阿诺德-柯尔莫哥洛夫叠加(AK叠加),因为是阿诺德完成了最后的临门一脚。本文中以下统称KA叠加定理或KA表示定理。柯尔莫哥洛夫的本意不完全是为了解决希尔伯特第13问题,但叠加定理事实上构成了对希尔伯特对第13问题原来猜测的(基本)否定。再后阿诺德和日本数学家志村五郎合作在这个问题上进一步推进。

至于是否柯尔莫哥洛夫和阿诺德“叠加”是希尔伯特第13问题的彻底解决,数学界有不同看法,有些数学家们认为希尔伯特原来说的是代数函数,而柯尔莫哥洛夫和阿诺德证明的是连续函数。希尔伯特的原话是“连续函数”,但考虑到黎曼-克莱因-希尔伯特的传统,数学家们认为希尔伯特的本意是代数函数。希尔伯特第13问题的研究并没有因为KA叠加定理完结,而是还在继续,这超出了本文范围。无论如何,叠加定理,歪打正着,为后续神经网络研究奠定了理论基础。

KA叠加定理如下:
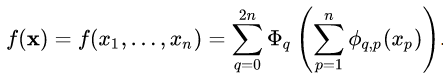
即,任意多元的连续函数都可以表示为若干一元函数和加法的叠加。加法是唯一的二元函数。简单的函数都可以通过加法和一元函数叠加而成,这个道理并不难理解,如下所示,减、乘、除可由加法叠加而成:
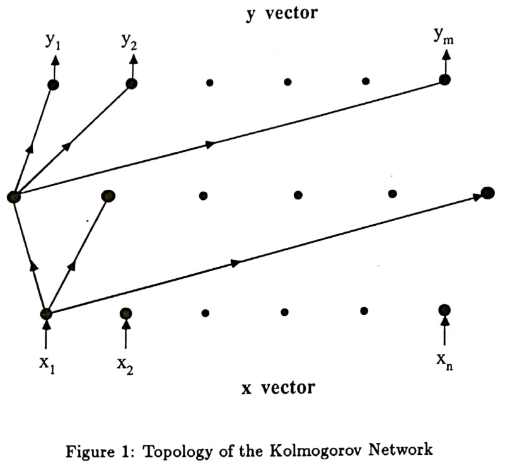
赫克-尼尔森指出,KA叠加定理可以通过两层网络实现,每层实现叠加中的一个加号。他干脆就把这个实现网络称为“柯尔莫哥洛夫网络”。法国数学家卡汉(Jean-Pierre Kahane,1926-2017),在1975年改进了KA叠加定理,如下:
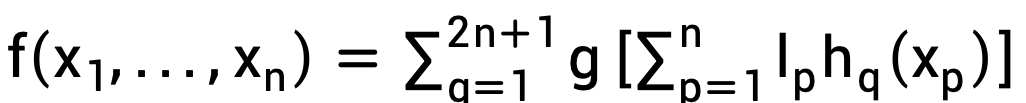
其中,h被进一步限制为严格单调函数,lp是小于1的正常量。





一段历史和一个思想实验:第谷机器
一段历史和一个思想实验:第谷机器
尾声
尾声
参考文献
(参考文献可上下滑动查看)
AI+Science 读书会
人工智能与数学读书会
数十年来,人工智能的理论发展和技术实践一直与科学探索相伴而生,尤其在以大模型为代表的人工智能技术应用集中爆发的当下,人工智能正在加速物理、化学、生物等基础科学的革新,而这些学科也在反过来启发人工智能技术创新。在此过程中,数学作为兼具理论属性与工具属性的重要基础学科,与人工智能关系甚密,相辅相成。一方面,人工智能在解决数学领域的诸多工程问题、理论问题乃至圣杯难题上屡创记录。另一方面,数学持续为人工智能构筑理论基石并拓展其未来空间。这两个关键领域的交叉融合,正在揭开下个时代的科学之幕。
为了探索数学与人工智能深度融合的可能性,集智俱乐部联合同济大学特聘研究员陈小杨、清华大学交叉信息学院助理教授袁洋、南洋理工大学副教授夏克林三位老师,共同发起“人工智能与数学”读书会,希望从 AI for Math,Math for AI 两个方面深入探讨人工智能与数学的密切联系。读书会已完结,现在报名可加入社群并解锁回放视频权限。
详情请见:
人工智能与数学读书会启动:AI for Math,Math for AI
推荐阅读
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











