为了帮助大家更好地了解因果科学的最新科研进展和资讯,我们因果科学社区团队本周整理了第6期《因果科学周刊》,推送近期因果科学值得关注的论文和资讯信息。本期的主题是”领域自适应“。
本期作者:刘珈麟 许雄锐 赵江杰 陈晗曦 袁蕾 方文毅 杨二茶 龚鹤扬 宫明明
当前机器学习研究的一个重点,是算法的鲁棒性和泛化能力。已有模型均假设训练数据和测试数据独立同分布(IID),实际应用很难满足。更常见的情况是,训练数据和算法部署场景的数据之间存在一定因果关联,对此,Bernhard Scholkopf曾举例:海拔是影响气温的重要因素,不同地区的海拔不同(即目标先验知识发生改变),但海拔对气温的影响机制几乎相同(即条件概率分布相同,或因果机制不变)。天下没有免费的午餐(No Free Launch Theorem),对于如何寻找更合理的假设来代替IID的强假设,因果科学为我们提供了值得借鉴的思路。在第五期的周刊当中,我们介绍了两种解决OOD的方式(利用因果图信息,利用表示学习,stable learning是这两种思路的融合),以及 Y. Bengio 在尝试的元学习思路。本期周刊为大家带来,由墨尔本大学宫明明老师推荐的六篇关于因果与领域自适应相结合的文章。严格范畴的 OOD 问题要求我们不对测试数据的分布做任何假设,相对于从第五期周刊介绍的有关 从 IID 到 OOD 的内容,领域自适应关注算法在测试集上的表现,经常对测试分布如何变化做出了一些假定,例如目标偏移,条件偏移和广义目标偏移。本期周刊推荐的六篇文章探讨了这三种问题,希望能激发相关研究人员进一步的思考。
1)Zhang, Kun, et al. “Domain adaptation under target and conditional shift.” International Conference on Machine Learning. 2013.
2)Gong, Mingming, et al. “Domain adaptation with conditional transferable components.” International conference on machine learning. 2016.
3)Guo, Jiaxian, et al. “Ltf: A label transformation framework for correcting target shift.” ICML, 2020.
4)Teshima, Takeshi, Issei Sato, and Masashi Sugiyama. “Few-shot Domain Adaptation by Causal Mechanism Transfer.” arXiv preprint arXiv:2002.03497 (2020).
5)Magliacane, Sara, et al. “Domain adaptation by using causal inference to predict invariant conditional distributions.” Advances in Neural Information Processing Systems. 2018.
6)Zhang, Kun, et al. “Domain adaptation as a problem of inference on graphical models.” Advances in Neural Information Processing Systems 33 (2020).
我们推荐的6篇论文根据因果模型是否已知可以分为两大类,前4篇是在因果模型已知的条件下,其中前3篇文章探讨了在因果图已知的情况下,领域自适应问题的基本框架,广义目标偏移和表示学习相结合的目标偏移问题,第4篇论文则利用到了J.Pearl的结构因果方程SCM来帮助领域自适应;第5、6篇论文则属于因果模型未知的情况。
Zhang, Kun, et al. “Domain adaptation under target and conditional shift.” International Conference on Machine Learning. 2013.
摘要:用X表示特征,Y表示目标,本文研究以下以下三种情况的领域自适应问题:(1)目标偏移,边缘概率 改变,条件概率
改变,条件概率 不变;(2)条件偏移,不变,条件概率在限定条件下改变;(3)广义目标偏移,改变,条件概率在限定条件下改变。利用背景因果知识,我们可以对手中的问题进行正确的分类。我们利用重要性重估和样本变换来找到在测试集上性能良好的学习算法,思路是对训练集数据进行重新加权评估或变换来重现测试集上的协变量分布。因为边缘概率分布和条件概率分布都有核方法表示,本文提出的方法避免了直接重新估计协变量分布,也适用于高维数据分布。在仿真数据和真实数据上的数值实验证明了本文所提方法的有效性。
刘珈麟简评:Zhang Kun(CMU,MPI)老师这篇文章,将领域自适应问题梳理成四个类别:协变量偏移,目标偏移,条件偏移和广义目标偏移。并针对上述三种未得到解决的问题给出了基本解决框架。
Gong, Mingming, et al. “Domain adaptation with conditional transferable components.” International conference on machine learning. 2016.
摘要:领域自适应在监督学习中用于研究训练集和测试集存在数据分布不一致的情况。在之前的工作中,大部分的领域自适应工作都集中在协变量偏移的研究, 用X和Y分别表示特征和目标,当出现跨领域时,仅考虑特征分布P(X)的改变,并没有考虑条件概率P(Y|X)的变化。为了降低领域偏差,最近的研究通过最小化不同领域分布差异的方法,寻找不变因子 (invariant components) T(x),T(x)的概率分布P(T(x))在不同领域中是近似相等的。然而在不同的领域中,当P(Y|X)发生变化时,并不能确定它们的P(Y|T(X))也是近似相等的。此外,可迁移的因子 (transferable components) 并一定是不变的。只要其中有一些因子的变化是可识别的,就可以利用这些因子在目标领域进行预测。本文主要关注在Y causes X的因果系统中,研究P(X|Y)和P(Y)都发生变化的情况。在合适的假设前提下,我们的目标是提取那些通过局部缩放 (location-scale) 变换之后,在不同领域内的条件概率P(T(X)|Y)保持不变的条件可迁移因子 (conditional transferable components),并同时识别P(Y)在不同领域间是如何变化的。本文在人工合成数据与真实世界数据上进行了理论分析和实证评估,来表明我们方法的有效性。
刘珈麟简评:本文在第一篇文章的基础上,考虑广义目标偏移条件下的领域自适应。与推荐论文1关注样本重要性跨领域重估不同的是,本文关注另一大类方法:不变因子发现。已有研究忽略了一个重要现象,即不变因子可能改变,本文作者针对这种情况提出了新的方法来统一已有的不变因子发现相关研究。
Guo, Jiaxian, et al. “Ltf: A label transformation framework for correcting target shift.” ICML, 2020.
摘要:分布偏移是当前深度学习模型在现实世界中部署时遇到的主要障碍。用Y表示标签、X表示特征,我们关注的是分布偏移中的一种——target shift,这里是指目标变量的边缘分布发生变化而条件分布不变的情况。现有方法通过密度估计的方法来估计源域和目标域的标签分布密度率。然而,这些方法要么对大规模数据有很高的计算量,要么限定在离散标签偏移的情况。本文中,我们提出了一种端到端的标签转换框架 (Label Transformation Framework, LTF) 来修正target shift,LTF把的偏移和条件分布用神经网络建模。由于深度网络的灵活性,我们提出的框架可以针对大数据用统一的框架处理连续、离散甚至多维标签。此外,对高维特征X,例如图像,我们发现X中冗余的信息严重降低了估计准确率。为了解决这一问题,我们提出一种基于生成模型隐式地匹配分布,将特征分布匹配到低维特征空间,且丢弃那些和Y无关的信息。理论和经验研究都表明我们的方法比先前的工作有更卓越的性能。
刘珈麟简评:本文和宫明明老师,Zhang Kun老师的研究思路一脉相承。前两篇文章分别指出了领域自适应的重点也是难点:从源域到目标域的迁移机制,这在样本重估中是ratio,都是针对概率密度进行直接或间接的重估。一个自然的想法就是用神经网络来代替这个重估过程。结合System1表示学习的成果研究领域自适应是本文的亮点。
Teshima, Takeshi, Issei Sato, and Masashi Sugiyama. “Few-shot Domain Adaptation by Causal Mechanism Transfer.” arXiv preprint arXiv:2002.03497 (2020).
摘要:我们研究回归中的少样本有监督领域自适应(DA)问题,在该问题中我们只能获得少量的目标域有标签数据和大量的源域有标签数据。现在大多数的DA方法都是将他们的迁移假设建立在分布变化的参数形式或是明显的分布相似处上,比如说相同的条件或是小的分布差异。然而,这些假设可能限制了复杂变化的或是明显非常不同分布的自适应可能性。为了克服这个问题,我们提出了机制迁移——一种跨领域时数据产生机制不变的元分布情形。机制迁移的假设能够在给DA提供坚实的统计基础的同时考虑到导致明显不同分布的非参数变化情形。我们将因果模型中的结构方程作为案例并且提出了一种创新的且通过理论和实验证明有用的DA方法。我们的方法可以被视作在DA中完全发挥结构因果模型的重要作用的第一次尝试。
刘珈麟简评:Elias Bareinboim在文章“On Pearl’s Hierarchy and the Foundations of Causal Inference”中指出,因果推理本质上是在SCM未知的情况下,通过经验(数据)和知识(因果假设限制)来做分类回归等推理。本文同样是基于这样一个假设(在数据分布背后存在一个普世的因果生成机制),通过对这个生成机制做假设可以避免直接对迁移过程做假设(Zhang Kun老师第一篇文章中假设迁移服从局部变换),是SCM框架和领域自适应问题的一次结合。
Magliacane, Sara, et al. “Domain adaptation by using causal inference to predict invariant conditional distributions.” Advances in Neural Information Processing Systems. 2018.
摘要:领域自适应和因果推理的一个共同的重要目标是当源(或训练)领域和目标(或测试)领域的分布不同时做出准确的预测。在许多情况下,这些不同的分布可以被建模为一个单一底层系统下的不同环境,其中每个分布对应于系统的不同扰动,或者使用因果术语——干预。我们专注于这样的一类因果领域自适应问题,问题给出了一个或多个源域的数据,任务是通过对一个或多个目标域中其他变量的测量来预测某个目标变量的分布。我们提出了一种解决这些问题的方法,该方法利用因果推理,不依赖于对因果图、干预类型或干预目标的先验知识。我们通过在模拟和真实数据上评估一个可能的实现来展示我们的方法。
龚鹤扬简评:文章的一个核心假设是存在一个协变量子集 A,使得给定这些协变量的情况下,Y 的条件分布在训练集和测试集上是不变的。
Zhang, Kun, et al. “Domain adaptation as a problem of inference on graphical models.” Advances in Neural Information Processing Systems 33 (2020).
摘要:本文致力于解决数据驱动的无监督领域自适应问题。无监督领域自适应问题的难点在于事先无法得知联合分布是如何跨领域变化的,也就是说,无法得知在不同的领域中对变量分布有作用的哪些因素或模块是保持不变的,抑或是变化的。为了得到一种解决多源域领域自适应问题的自动化方法,我们使用了能从数据中学习到的图模型作为编码联合分布中变化属性的压缩方法,然后将领域自适应问题视作在图模型上的贝叶斯推断问题。这样的一种图模型能够将分布中的不变模块和变化模块区分开来,并能确定跨领域的变化属性,这可以为推导目标域中目标变量Y的后验分布提供变化模块的先验知识。该方法提供了一种领域自适应的端到端的框架,在这个框架中,如果有额外的关于联合分布变化的知识,这些知识就能被直接纳入框架中使用从而改进图的表示。我们在本文中讨论了如何在所提出的框架中表述基于因果的领域自适应问题。在仿真和真实数据中的实验结果也证明了所提出的领域自适应框架的有效性。本文中涉及的代码可以在 https://github.com/mgong2/DA_Infer 获取。
龚鹤扬简评:这是解决领域自适应问题的一种新思路,其中一个关键假设是不同领域数据的部分是某个 mother 分布 i.i.d 采样得到的。
2020年11月22日,因果科学与Causal AI读书会第九期——“因果推理和迁移学习”如期进行,宫明明、郭家贤、丁晨炜作了精彩分享。
宫明明,墨尔本大学讲师,研究方向为因果推断,基于因果的机器学习,迁移学习,计算机视觉。
郭家贤, 悉尼大学在读博士,研究方向为深度迁移学习,强化学习。
丁晨炜,悉尼大学在读博士,研究方向为因果发现,计算机视觉。
大数据的出现使得许多学科在学习和预测方面取得了革命性的成功。但是,当前的机器学习模型的一个主要缺点是缺乏对新领域的适应性和泛化能力。也就是说,标准的监督学习模型在数据分布发生变化时预测性能会显著下降。在本次读书会,我们将重点讲述如果利用因果模型理解和建模不同领域的分布变化。因为因果系统的独立模块性质,我们可以将复杂的分布分解成小的模块,发掘分布在不同领域的不变性和变化性,从而开发出具有领域自适应能力的高效迁移学习算法。以下是本次读书会的大纲:
答:每个causal module,参数是由不同部分变成。这些就是同步变化的参数,可以看成是confounder。这种变量叫做二层变量,叫共同影响的因子。公司文化或者制度对个体的影响。C可以是企业文化,每个人采样都采V1,V2,V3,V4的四个变量,比如工资多少,加班时间等等。对于同一个公司的不同人都是一样的,只是影响的不同因素。
问:Wi-Fi和augmented的真实应用是什么?
不变;(2)条件偏移,不变,条件概率在限定条件下改变;(3)广义目标偏移,改变,条件概率在限定条件下改变。利用背景因果知识,我们可以对手中的问题进行正确的分类。我们利用重要性重估和样本变换来找到在测试集上性能良好的学习算法,思路是对训练集数据进行重新加权评估或变换来重现测试集上的协变量分布。因为边缘概率分布和条件概率分布都有核方法表示,本文提出的方法避免了直接重新估计协变量分布,也适用于高维数据分布。在仿真数据和真实数据上的数值实验证明了本文所提方法的有效性。
刘珈麟简评:Zhang Kun(CMU,MPI)老师这篇文章,将领域自适应问题梳理成四个类别:协变量偏移,目标偏移,条件偏移和广义目标偏移。并针对上述三种未得到解决的问题给出了基本解决框架。
Gong, Mingming, et al. “Domain adaptation with conditional transferable components.” International conference on machine learning. 2016.
摘要:领域自适应在监督学习中用于研究训练集和测试集存在数据分布不一致的情况。在之前的工作中,大部分的领域自适应工作都集中在协变量偏移的研究, 用X和Y分别表示特征和目标,当出现跨领域时,仅考虑特征分布P(X)的改变,并没有考虑条件概率P(Y|X)的变化。为了降低领域偏差,最近的研究通过最小化不同领域分布差异的方法,寻找不变因子 (invariant components) T(x),T(x)的概率分布P(T(x))在不同领域中是近似相等的。然而在不同的领域中,当P(Y|X)发生变化时,并不能确定它们的P(Y|T(X))也是近似相等的。此外,可迁移的因子 (transferable components) 并一定是不变的。只要其中有一些因子的变化是可识别的,就可以利用这些因子在目标领域进行预测。本文主要关注在Y causes X的因果系统中,研究P(X|Y)和P(Y)都发生变化的情况。在合适的假设前提下,我们的目标是提取那些通过局部缩放 (location-scale) 变换之后,在不同领域内的条件概率P(T(X)|Y)保持不变的条件可迁移因子 (conditional transferable components),并同时识别P(Y)在不同领域间是如何变化的。本文在人工合成数据与真实世界数据上进行了理论分析和实证评估,来表明我们方法的有效性。
刘珈麟简评:本文在第一篇文章的基础上,考虑广义目标偏移条件下的领域自适应。与推荐论文1关注样本重要性跨领域重估不同的是,本文关注另一大类方法:不变因子发现。已有研究忽略了一个重要现象,即不变因子可能改变,本文作者针对这种情况提出了新的方法来统一已有的不变因子发现相关研究。
Guo, Jiaxian, et al. “Ltf: A label transformation framework for correcting target shift.” ICML, 2020.
摘要:分布偏移是当前深度学习模型在现实世界中部署时遇到的主要障碍。用Y表示标签、X表示特征,我们关注的是分布偏移中的一种——target shift,这里是指目标变量的边缘分布发生变化而条件分布不变的情况。现有方法通过密度估计的方法来估计源域和目标域的标签分布密度率。然而,这些方法要么对大规模数据有很高的计算量,要么限定在离散标签偏移的情况。本文中,我们提出了一种端到端的标签转换框架 (Label Transformation Framework, LTF) 来修正target shift,LTF把的偏移和条件分布用神经网络建模。由于深度网络的灵活性,我们提出的框架可以针对大数据用统一的框架处理连续、离散甚至多维标签。此外,对高维特征X,例如图像,我们发现X中冗余的信息严重降低了估计准确率。为了解决这一问题,我们提出一种基于生成模型隐式地匹配分布,将特征分布匹配到低维特征空间,且丢弃那些和Y无关的信息。理论和经验研究都表明我们的方法比先前的工作有更卓越的性能。
刘珈麟简评:本文和宫明明老师,Zhang Kun老师的研究思路一脉相承。前两篇文章分别指出了领域自适应的重点也是难点:从源域到目标域的迁移机制,这在样本重估中是ratio,都是针对概率密度进行直接或间接的重估。一个自然的想法就是用神经网络来代替这个重估过程。结合System1表示学习的成果研究领域自适应是本文的亮点。
Teshima, Takeshi, Issei Sato, and Masashi Sugiyama. “Few-shot Domain Adaptation by Causal Mechanism Transfer.” arXiv preprint arXiv:2002.03497 (2020).
摘要:我们研究回归中的少样本有监督领域自适应(DA)问题,在该问题中我们只能获得少量的目标域有标签数据和大量的源域有标签数据。现在大多数的DA方法都是将他们的迁移假设建立在分布变化的参数形式或是明显的分布相似处上,比如说相同的条件或是小的分布差异。然而,这些假设可能限制了复杂变化的或是明显非常不同分布的自适应可能性。为了克服这个问题,我们提出了机制迁移——一种跨领域时数据产生机制不变的元分布情形。机制迁移的假设能够在给DA提供坚实的统计基础的同时考虑到导致明显不同分布的非参数变化情形。我们将因果模型中的结构方程作为案例并且提出了一种创新的且通过理论和实验证明有用的DA方法。我们的方法可以被视作在DA中完全发挥结构因果模型的重要作用的第一次尝试。
刘珈麟简评:Elias Bareinboim在文章“On Pearl’s Hierarchy and the Foundations of Causal Inference”中指出,因果推理本质上是在SCM未知的情况下,通过经验(数据)和知识(因果假设限制)来做分类回归等推理。本文同样是基于这样一个假设(在数据分布背后存在一个普世的因果生成机制),通过对这个生成机制做假设可以避免直接对迁移过程做假设(Zhang Kun老师第一篇文章中假设迁移服从局部变换),是SCM框架和领域自适应问题的一次结合。
Magliacane, Sara, et al. “Domain adaptation by using causal inference to predict invariant conditional distributions.” Advances in Neural Information Processing Systems. 2018.
摘要:领域自适应和因果推理的一个共同的重要目标是当源(或训练)领域和目标(或测试)领域的分布不同时做出准确的预测。在许多情况下,这些不同的分布可以被建模为一个单一底层系统下的不同环境,其中每个分布对应于系统的不同扰动,或者使用因果术语——干预。我们专注于这样的一类因果领域自适应问题,问题给出了一个或多个源域的数据,任务是通过对一个或多个目标域中其他变量的测量来预测某个目标变量的分布。我们提出了一种解决这些问题的方法,该方法利用因果推理,不依赖于对因果图、干预类型或干预目标的先验知识。我们通过在模拟和真实数据上评估一个可能的实现来展示我们的方法。
龚鹤扬简评:文章的一个核心假设是存在一个协变量子集 A,使得给定这些协变量的情况下,Y 的条件分布在训练集和测试集上是不变的。
Zhang, Kun, et al. “Domain adaptation as a problem of inference on graphical models.” Advances in Neural Information Processing Systems 33 (2020).
摘要:本文致力于解决数据驱动的无监督领域自适应问题。无监督领域自适应问题的难点在于事先无法得知联合分布是如何跨领域变化的,也就是说,无法得知在不同的领域中对变量分布有作用的哪些因素或模块是保持不变的,抑或是变化的。为了得到一种解决多源域领域自适应问题的自动化方法,我们使用了能从数据中学习到的图模型作为编码联合分布中变化属性的压缩方法,然后将领域自适应问题视作在图模型上的贝叶斯推断问题。这样的一种图模型能够将分布中的不变模块和变化模块区分开来,并能确定跨领域的变化属性,这可以为推导目标域中目标变量Y的后验分布提供变化模块的先验知识。该方法提供了一种领域自适应的端到端的框架,在这个框架中,如果有额外的关于联合分布变化的知识,这些知识就能被直接纳入框架中使用从而改进图的表示。我们在本文中讨论了如何在所提出的框架中表述基于因果的领域自适应问题。在仿真和真实数据中的实验结果也证明了所提出的领域自适应框架的有效性。本文中涉及的代码可以在 https://github.com/mgong2/DA_Infer 获取。
龚鹤扬简评:这是解决领域自适应问题的一种新思路,其中一个关键假设是不同领域数据的部分是某个 mother 分布 i.i.d 采样得到的。
2020年11月22日,因果科学与Causal AI读书会第九期——“因果推理和迁移学习”如期进行,宫明明、郭家贤、丁晨炜作了精彩分享。
宫明明,墨尔本大学讲师,研究方向为因果推断,基于因果的机器学习,迁移学习,计算机视觉。
郭家贤, 悉尼大学在读博士,研究方向为深度迁移学习,强化学习。
丁晨炜,悉尼大学在读博士,研究方向为因果发现,计算机视觉。
大数据的出现使得许多学科在学习和预测方面取得了革命性的成功。但是,当前的机器学习模型的一个主要缺点是缺乏对新领域的适应性和泛化能力。也就是说,标准的监督学习模型在数据分布发生变化时预测性能会显著下降。在本次读书会,我们将重点讲述如果利用因果模型理解和建模不同领域的分布变化。因为因果系统的独立模块性质,我们可以将复杂的分布分解成小的模块,发掘分布在不同领域的不变性和变化性,从而开发出具有领域自适应能力的高效迁移学习算法。以下是本次读书会的大纲:
答:每个causal module,参数是由不同部分变成。这些就是同步变化的参数,可以看成是confounder。这种变量叫做二层变量,叫共同影响的因子。公司文化或者制度对个体的影响。C可以是企业文化,每个人采样都采V1,V2,V3,V4的四个变量,比如工资多少,加班时间等等。对于同一个公司的不同人都是一样的,只是影响的不同因素。
问:Wi-Fi和augmented的真实应用是什么?
答:Wifi变量之间的关系做adaptation domain。这个应用本身就是做wifi定位的时候,知道具体位置,这样可以搜到一系列wifi信号,通过每个路由器信号强弱来判断距离。早上、晚上和中午拍出来的信号随着时间变化,今天和明天不一样。这个应用就是用一个model可以穿到各种各样时间段里,不用采集那么多数据。
因果科学社区简介:它是由集智俱乐部、智源社区共同推动,面向因果科学领域的垂直型学术讨论社区,目的是促进因果科学专业人士和兴趣爱好者们的交流和合作,推进因果科学学术、产业生态的建设和落地,孕育新一代因果科学领域的学术专家和产业创新者。
因果科学社区愿景:回答因果问题是各个领域迫切的需求,当前许多不同领域(例如 AI 和统计学)都在使用因果推理,但是他们所使用的语言和模型各不相同,导致这些领域科学家之间沟通交流困难。因此我们希望构建一个社区,通过组织大量学术活动,使得科研人员能够掌握统计学的核心思想,熟练使用当前 AI 各种技术(例如 Pytorch/Pyro 搭建深度概率模型),促进各个领域的研究者交流和思维碰撞,从而让各个领域的因果推理有着共同的范式,甚至是共同的工程实践标准,推动刚刚成型的因果科学快速向前发展。具备因果推理能力的人类紧密协作创造了强大的文明,我们希望在未来社会中,因果推理融入到每个学科,尤其是紧密结合和提升 AI ,期待无数具备攀登因果之梯能力的 Agents (Causal AI) 和人类一起协作,共建下一代的人类文明!
如果您有适当的数学基础和人工智能研究经验,既有科学家的好奇心也有工程师思维,希望参与到”因果革命“中,教会机器因果思维,为因果科学作出贡献,请加入我们微信群:扫描下面社区小助手二维码加入(请备注“因果科学”)👇
大数据时代的下一场变革——因果革命正在酝酿之中,通过融合因果推理和机器学习而构建出来的Causal AI系统,有望奠定强人工智能的基石。
集智俱乐部联合北京智源人工智能研究院,邀请了一批对因果科学与Causal AI感兴趣的研究者,开展为期2-3个月的系列线上读书会,研读经典和前沿论文,并尝试集体撰写一部书籍。如果你也从事相关的研究、应用工作,欢迎报名,参与读书会的讨论!
时间:9月20日起,每周日晚19:00-21:00,持续约2-3个月
模式:线上闭门读书会;收费-退款的保证金模式;读书会成员认领解读论文
了解读书会具体规则、报名读书会请点击下方文章:
目前读书会已经有超过130余人的海内外高校科研院所的一线科研工作者以及互联网一线从业人员参与,如果你也对这个主题感兴趣,就快加入我们吧!
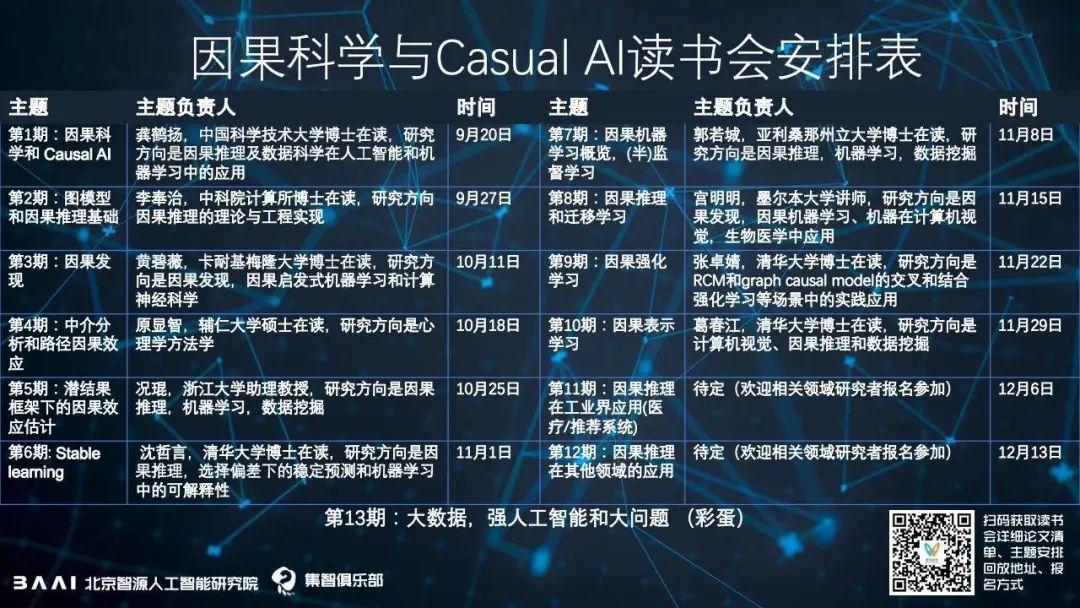
图注:针对读书会的主题,由发起人龚鹤扬设置好了内容框架,每个主题下有一个负责人来负责维护组织相关内容,目前已经定好的如图所示,欢迎对主题感兴趣的联系相关负责人,以及来认领相关主题。













