复现是科学的唯一标准吗?论文可重复危机的一种解决方案

导语
科学的可重复性是科学区别于伪科学的一大特征,然而随着科学研究的快速发展及不断细化,其不可重复性的隐患不断加剧。针对该问题,美国国家科学研究委员推出了《科学中的可再现性与可重复性》 报告,提出一系列指导建议。本文则在原指导意见的基础上,进一步提出前瞻性研究方法,通过设计好的研究顺序来积累研究证据。并提出利用信息态演化的方法,持续更新不同模型的可信度,提高研究结果与模型预测的匹配程度,从而解决可重复性问题。 James D. Nichols等 | 作者Leo、张澳 | 译者刘培源 | 审校
James D. Nichols等 | 作者Leo、张澳 | 译者刘培源 | 审校
邓一雪 | 编辑
 论文题目:
论文题目:
Opinion: A better approach for dealing with reproducibility and replicability in science
论文地址:https://www.pnas.org/content/118/7/e2100769118
科学会影响我们的日常生活,也指导着国内与国际政策[1]。因此,科研成果极其重要,然而对于研究不可重复性的担忧始终存在[2]。为了解决这一问题,美国国家科学研究委员会牵头了一项共识研究Reproducibility and Replicability in Science(NASEM 2019 报告[3]),在这项研究中,对关键的概念进行了定义,对有关问题进行了讨论,并且对问题的解决方法提供了指导建议。虽然已经有了这些经过深思熟虑的建议,但我们仍然觉得这些建议并不充分。在先前的研究中,尽管承认了分立研究的局限性以及集成研究的必要性[3],但NASEM 2019 报告仍仅考虑了单一研究中的可重复性问题。因此,在本文中,我们提倡一种战略性研究方法,通过设计好的研究顺序来积累研究证据,并以此来试图解决可重复性问题。随着研究的进行,根据不同假设的预测结果会逐步积累不同的证据。  图1. 美国 NASEM 2019 报告《科学中的可复现性与可重复性》 在许多研究领域中,我们很难凭借单一的研究就获得大量的知识。芝加哥大学物理学教授 John Rader Platt [4]所说的那种具有明确结论的“关键实验”可以被找到但是屈指可数。因此,大多数时候,单一研究的结果也只能被视为理论的基石,而理论大厦的构建需要对同一现象进行多次研究[5-7]。基于这一主张,我们可以有计划地制定研究顺序,从而对重要假设的研究做出战略性的规划。 我们主张在研究结果与模型预测之间做比较,这样比在不同研究结果之间做比较,对科学更有益处。后者是比较两个研究的结果是否相似,而前者是在不断评估具体假设及其预测的可信度。当存在众多假设时[8],我们要做的工作就是随着研究结果的积累,对这些假设的相对可信度进行跟踪调查。为了积累研究证据,我们提出了逐步检测模型预测结果的调查流程。
图1. 美国 NASEM 2019 报告《科学中的可复现性与可重复性》 在许多研究领域中,我们很难凭借单一的研究就获得大量的知识。芝加哥大学物理学教授 John Rader Platt [4]所说的那种具有明确结论的“关键实验”可以被找到但是屈指可数。因此,大多数时候,单一研究的结果也只能被视为理论的基石,而理论大厦的构建需要对同一现象进行多次研究[5-7]。基于这一主张,我们可以有计划地制定研究顺序,从而对重要假设的研究做出战略性的规划。 我们主张在研究结果与模型预测之间做比较,这样比在不同研究结果之间做比较,对科学更有益处。后者是比较两个研究的结果是否相似,而前者是在不断评估具体假设及其预测的可信度。当存在众多假设时[8],我们要做的工作就是随着研究结果的积累,对这些假设的相对可信度进行跟踪调查。为了积累研究证据,我们提出了逐步检测模型预测结果的调查流程。
1. 新方法:信息态演变
我们可以通过战略性的规划来促进研究证据的积累,从而解决科学研究可重复性的问题。在这里我们使用了一种被称为“信息态演变”(evolving information state EIS[9])的方法,它基于多个假设及其各自的模型。 具体而言,在任意时间 t ,每一个模型都有与之对应的权重,以此来表示该模型的相对可信度。信息态则被定义为各模型权重所组成的向量,说明了至今为止各模型所积累的可信度。利用贝叶斯定理结合 t 时刻前累计的权重以及各模型对于新数据的预测程度(如[9],[10]),即可对权重(也就是相对可信度)进行更新。而且,调查程序中每个研究的最优设计也取决于其模型当前权重。如果模型中包含有效的假设,那么随着证据的累计,该模型的权重就应该接近1,而其余模型的权重则应接近于0。 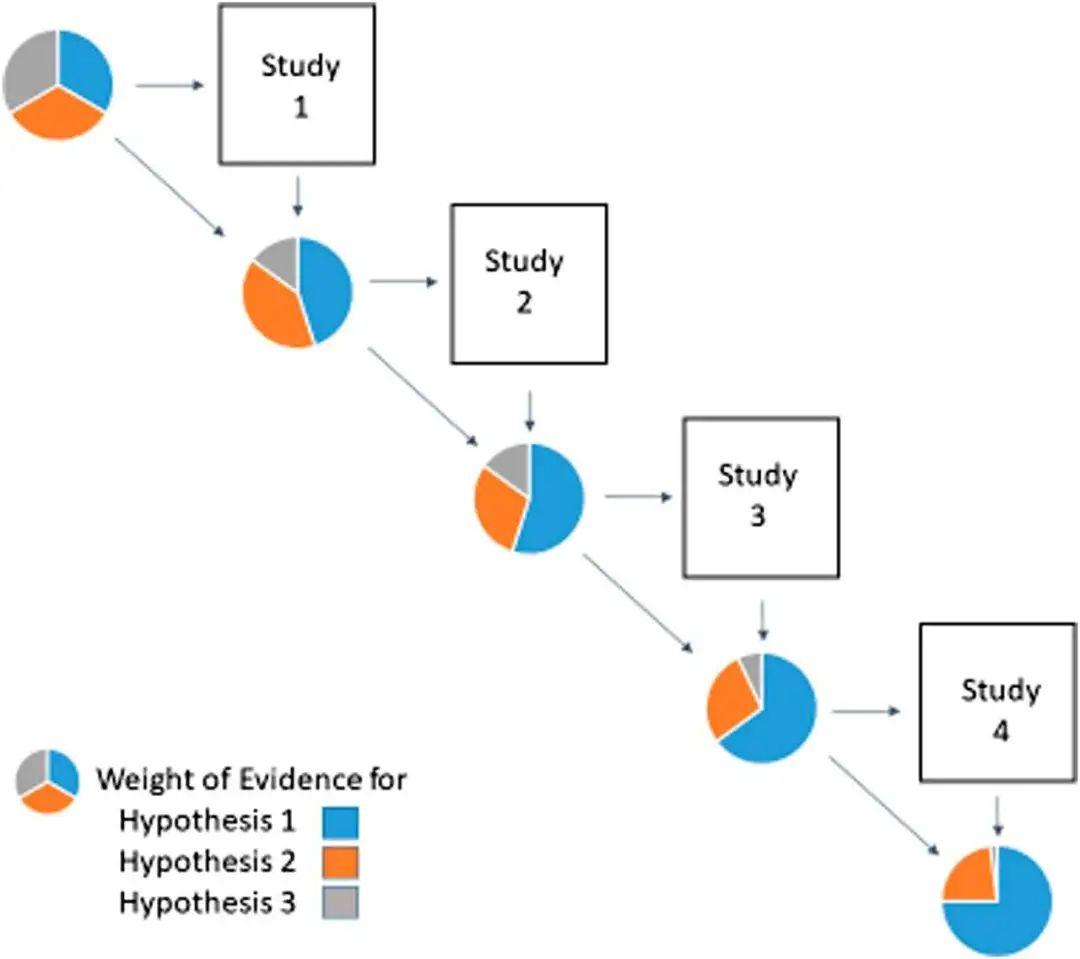 图2. 信息态演变示意图,每一个时刻的饼图都代表信息状态的改变,面积的大小变化则对应着权重的变化。从图中我们能够明显地看到,随着研究的进展,蓝色所代表的假设1的权重在逐渐增强。
图2. 信息态演变示意图,每一个时刻的饼图都代表信息状态的改变,面积的大小变化则对应着权重的变化。从图中我们能够明显地看到,随着研究的进展,蓝色所代表的假设1的权重在逐渐增强。
一个和信息态演变方法相关的实例就是由美国鱼类及野生动物管理局(USFWS [9],[11])牵头的北美中部地区绿头鸭25年管理计划。该管理计划旨在为捕猎管制政策的制定提供信息,并对各生物竞争模型进行比较,从而了解不同管制政策对种群动态的影响。 在该计划实施的每一年中,基于当年(t年)繁殖种群规模的估计(基于大规模的监测计划)以及当年秋冬捕猎季所选择实施的管制政策,四种竞争模型都会给出下一年(t+1年)春天繁殖种群规模的预测。在下一个繁殖季(t+1年),将各模型基于上一年所预测的结果与种群规模的最新预估进行对比,再基于各模型的预测能力,利用贝叶斯定理更新先前各模型的权重。图3展示了各年种群规模的预估及基于模型的预测,以及信息态的演化。 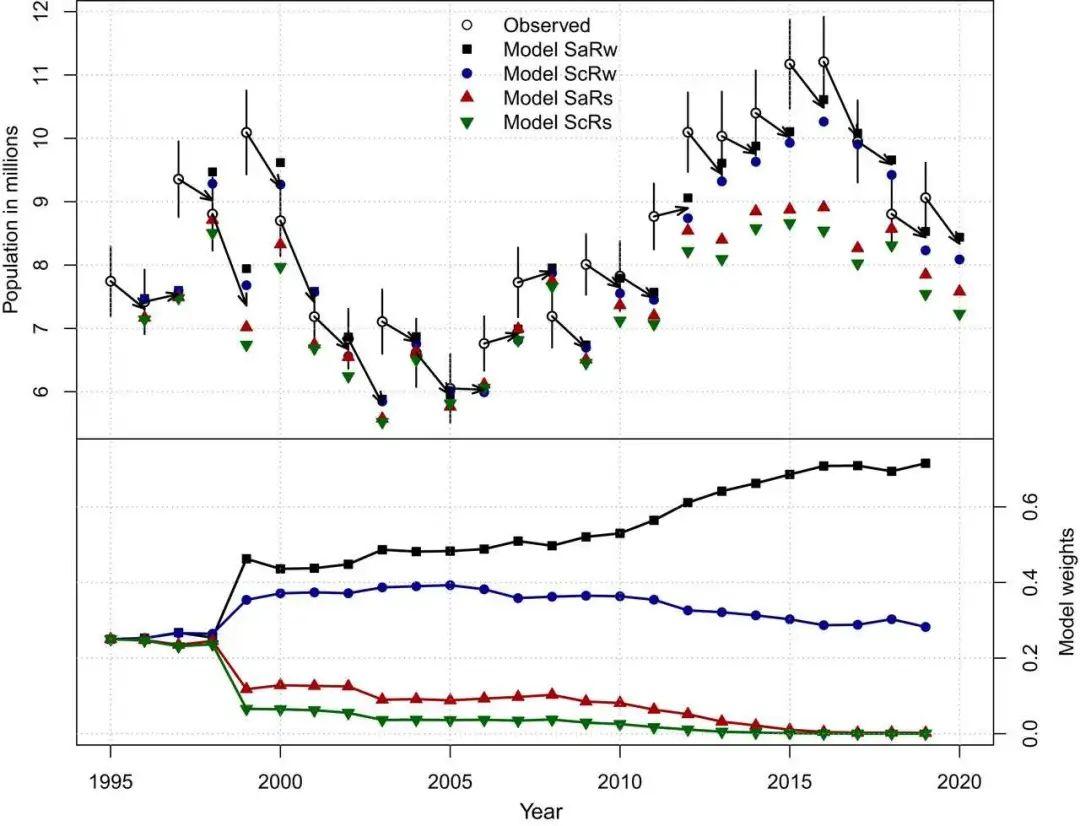 图3. 该图展现了美国中部地区绿头鸭的观测数值与预测数值的逐年比较,以及相应的权重演化。图2上半部分表示的是种群预估与各模型预测结果逐年变化的图示。图中竖线是预估值95%置信区间的误差条,箭头表示所有模型预测的加权结果。图2下半部分则表示的是各模型权重的演化(信息态);研究中各模型在1995年初始权重相同。
图3. 该图展现了美国中部地区绿头鸭的观测数值与预测数值的逐年比较,以及相应的权重演化。图2上半部分表示的是种群预估与各模型预测结果逐年变化的图示。图中竖线是预估值95%置信区间的误差条,箭头表示所有模型预测的加权结果。图2下半部分则表示的是各模型权重的演化(信息态);研究中各模型在1995年初始权重相同。
在该计划开始的时候,USFWS 为四个模型都赋予了相同的权重。到最后,有两个模型的权重已经接近 0。而剩下两个模型,其中一个的权重已经是另一个的两倍以上。我们注意到,这个例子中所涉及的权重变化是发正在一个多模型管理计划中的。该计划的目的是制定狩猎管理政策,而不是为了去学习预测模型[9]、[10]。如果要将该方法应用于学习预测模型,则需要基于积累证据以区分不同模型的目标,对系统操作流程、待评估目标参数、协变量做出周期性的调整。
2. 可再现性与可重复性
在 NASEM 2019 报告 中将可再现性(Reproducibility)定义为“计算可再现,即使用相同的数据、计算步骤、方法、代码与分析条件应当获得一样的结果”[3]。这份指导建议包含了对数据访问方法和计算步骤的详细表述,但较少涉及模型的规范与选择等重要的变异来源。 由此,我们发现可再现性的定义是对单项研究而言的,若我们以多种研究来积累证据,至少也需要检查某些组分研究结果的样本是否一致。这件事是可行的,并且样本间的差异很可能也会被发现。然而,如何利用这些信息为未来的研究提供信息或积累证据,我们尚不清楚。 我们认为可再现性的缺失是影响可重复性的多个变异来源之一,而可重复性是证据积累的内涵所在。若希望减少可重复性方面的问题,其它原因至少应该受到同等重视,这些原因包括对重点模型或假设的具体说明,对预测结果适当的推导等。积累证据的方法应该对变异的不同原因有适应性,即使在这些原因存在时,也能做出有用的推断。 NASEM 2019 报告将可重复性(Replicability)定义为“在所有旨在回答相同科学问题的、且拥有自己数据的的研究中,取得一致的结果”。该定义还讨论了结果间的比较和“两结果间可重复性的评估”。在科学中,我们认为“结果”应该是指模型的预测及其相关假设与收集到的数据相一致的程度,其一致程度被用于评估模型的合理性,或是区分两个及以上相互竞争的模型。 一项研究的重复提供了支持或反对假设预测能力的额外证据。在考虑两个相似研究的结果时,我们认为重点不应该放在比较上,而应该放在它们各自基于假设的预测的一致性上,并结合一致性的评估以获得证据的全貌。事实上,假设与预测间可重复的一致性(或不一致性)提供了可重复性的最终证据。 研究的预注册(preregistration)被认为是提高可重复性的一种方法[3]。通过预注册,在研究开始前就已确定先验假设及其评估方法,从而说明结果是基于“探索性”分析还是“验证性”分析。我们建议采取未雨绸缪的策略,从单打独斗的研究上升为程序型的研究,研究人员通过一系列的实验来反复验证假设,这一系列的实验专为累计证据所用,且是逐步发展的。 NASEM 2019 报告中处理研究集成(research synthesis)的部门即证明了其对于多案例证据的关注。“当前,研究集成是对各类证据进行的系统综述及元分析(meta-analyses)[3],并且描述了研究活动的集合,包括识别、检索、评价、整合、解释及基于语境理解证据,这些证据是从某一特定主题的研究所得”。这种对于多案例证据的重视是有用的。 然而,基于现有研究的回顾性方法是有局限的。研究综合的回顾性方法主要基于现有的出版物,必须处理出版物偏倚等问题,这些问题使得发表的研究结果不一定能代表所有针对指定假设的研究。检测和处理发表偏倚的常用方法存在缺点。而前瞻性的方法则消除了许多回顾性方法的问题,在前瞻性方法中研究人员在某主题下设计并实施一系列用于积累证据的研究[9]。 NASEM 2019 报告报告包含一些声明,承认从多项研究中积累证据的重要性,例如, “有些人会认为,将专注于单一研究的可重复性作为提高科学效率的一种方式是不恰当的。然而,以对于某一主题累积证据的综述来衡量整体效果及其一般性,可能更有用”[3]。 对地球科学和气象预测的认知是基于概率预测和证据积累形成的[3]。因此,尽管关于科学发现如何开展的观点遍布整个报告,但它们并不占主导地位,也不提供报告建议的基础或关于实施收集证据的项目的细节。 集中于证据积累的方法对于解决与可重复性相关的许多问题是有用的。不可重复性的一个来源是“科学假设的先验概率(实验前似然性)”[3]。信息态演化方法将这一概念形式化,并明确地使用它来更新模型权重和积累证据。可信度是基于模型的预测能力,而不是依赖“实验前”的认知。与研究结果不确定性相关的报告经常被强调[3],但我们应该详细说明如何利用这种报告。用于更新模型权重的贝叶斯定理明确地包含了预测结果的不确定性,以及用于评估数据和预测结果之间对应程度的建模过程的不确定性。更大的不确定性可能会减缓学习的速度,但不会改变证据的积累。 我们建议采取额外的前瞻性措施,超越个体研究,进入流程化调查,研究人员在专门为积累证据而设计的研究序列中反复测试特定的假设。 建议预先注册拟进行的调查,以澄清研究结果[3]。信息态演化是一种前瞻性的研究方法,通过一系列拟定的研究,使得加速证据积累的设计考虑成为可能。当考虑两个以上的模型时,信息状态是最优设计[9]的重要决定因素,对“实验前似然性”[3]在研究实施中的使用进行了形式化。 信息态演化方法和积累证据的有关方法主要处理可再现性和可重复性的问题。在信息态更新过程中,会降低可再现性的重要不确定性来源(例如模型选择、合并的随机性)被直接处理。证据的积累将焦点从结果在其它研究中的再现转移到假设对于多个研究的数据得出一致预测的能力。研究降低可重复性的系统特征,如复杂性、噪声和不稳定性[3],并不妨碍证据的积累,而仅减慢了其积累的过程。可避免的非重复性来源[3]要么变得无关(例如发表偏倚),要么只是减慢了证据积累的速度(例如,糟糕的设计,错误)。
3. 进展
除了已提出的关于提高可再现性和可重复性的指导外[3],我们建议研究人员不再强调孤立研究,而是致力于积累证据的连续研究项目。我们理解这一建议说起来容易做起来难,但我们相信,现有的长期研究和监测项目已经预先适应了这种调整,正如前文的绿头鸭案例。研究人员可以组成学会,关注具体问题。未被纳入这类学会的孤立研究人员可以通过设计自己的研究来参与,以促进模型间的区分度[12,13]。只要各研究走在区分某类模型的这条线路上,不同研究者研究计划上的差异就不会构成概念性的问题。 指导中强调学术机构和国家实验室对于培训的提供[3]。此外,我们相信,如果科研机构的管理部门将其奖励制度的重点从独立研究转向旨在积累知识的项目,这将非常有用。报告还对美国国家科学基金会(National Science Foundation,NSF)和其他研究资助者提出了要求,希望他们更重视所资助研究对于方法与数据的详细描述,并尽量资助探索计算可再现、发展标准计算工具以及对已发表工作可再现性与可重复性进行评估回顾等类型的研究。[3] 美国国家科学基金会和其他资助者也确实可以发挥重要作用,将科研文化从单一研究,转向精心设计的研究序列。这样的转变将为研究人员提供动力,使他们能融入旨在积累证据的大型项目中。这种自上而下强调积累证据的做法可能非常有效,并将自然地解决许多再现性和可重复性的问题。 2019年NASEM会议的最终建议向政策制定者和公众呼吁:“任何基于科学证据做出个人或政策决定的人都应该谨慎,不要根据单一研究的结果做出严肃决定,不管这一结果多么有前景。“然而,对决策者而言,并不能简单地保持警惕或等待不确定性被解决(在许多情况下不太可能),而是要使用专门为处理不确定性而开发的决策算法和方法[12-14]。有些方法可以产生好的决策,同时减少不确定性,信息期望值(expected value of information)这一的概念的提出也明确了学习的价值[10, 15]。 近年来,人们越来越认识到,科学研究的进步正在受科学行为问题的拖累,例如经常无法再现或重复已发表的研究结果。正因为孤立研究的目的并不是为整体科研工作提供证据,所以造成可再现、可重复性问题也在所难免。我们建议通过进行有计划的研究序列来积累证据的正式方法。这一整体建议引出了针对个别研究人员、相关机构、资助机构和政策制定者的具体建议。我们认为,从一种孤立的研究文化向一种更综合的科学方法的转变,可以加速认知的形成。此外,这一政策也将改善并在很大程度上解决可再现性和可重复性的问题。
参考文献
[1] B. Ramalingam et al., Adaptive Leadership in the Coronavirus Response: Bridging Science, Policy, and Practice (ODI Coronavirus Briefing Note, London, 2020).
[2] M. Baker, 1,500 scientists lift the lid on reproducibility. Nature 533, 452–454 (2016).
[3]National Academies of Sciences, Engineering, and Medicine, Reproducibility and Replicability in Science (The National Academies Press, Washington, DC, 2019). doi:10.17226/25303.
[4]J. R. Platt, Strong inference: Certain systematic methods of scientific thinking may produce much more rapid progress than others. Science 146, 347–353 (1964).
[5]H. Poincare, Science and Hypothesis (The Science Press, New York, 1905).
[6] B. K. Forscher, Chaos in the brickyard. Science 142, 339 (1963).
[7]J. A. Nelder, Statistics, science and technology. J. Roy. Stat. Soc. A 149, 109–121 (1986).
[8]T. C. Chamberlin, The method of multiple working hypotheses. J. Geol. 5, 837–848 (1897).
[9]J. D. Nichols, W. L. Kendall, G. S. Boomer, Accumulating evidence in ecology: Once is not enough. Ecol. Evol. 9, 13991–14004 (2019).
[10]R. Hilborn, C. J. Walters, Quantitative Fisheries Stock Assessment: Choice, Dynamics, and Uncertainty (Chapman and Hall, New York, 1992).
[11]U.S. Fish and Wildlife Service, Adaptive Harvest Management: 2021 Hunting Season (U.S. Department of the Interior, Washington, D.C., 2020).
[12]P. Fackler, K. Pacifici, Addressing structural and observational uncertainty in resource management. J. Environ. Manage. 133, 27–36 (2014).
[13]B. K. Williams, Integrating external and internal learning in resource management. J. Wildl. Manage. 79, 148–155 (2015).
[14]J. D. Nichols, Confronting uncertainty: Contributions of the wildlife profession to the broader scientific community. J. Wildl. Manage. 83, 519–533 (2019).
[15]B. K. Williams, F. A. Johnson, Value of information in natural resource management: technical developments and application to pink-footed geese. Ecol. Evol. 5, 466–474 (2015).
(参考文献可上下滑动查看)
网络科学新课推荐:网络动力学
集智学园特邀陈关荣、项林英、樊瑛、宣琦、李翔、史定华、李聪、荣智海、周进、王琳等网络科学专家作为导师,依托汪小帆、李翔、陈关荣的经典教材《网络科学导论》,自2月27日起开展系列上线课程,以网络动力学为主线构建网络科学知识体系。欢迎希望进入网络科学领域、提高网络分析能力、与一线专家探讨问题的朋友报名参加!

点击查看课程详情:2021重磅新课:探索网络动力学——网络科学第二期
推荐阅读
Paper过时了?eLife发布交互式论文,线上就能复现结果危机:21篇顶刊社会科学论文仅有13篇可以复现Barabási新书笔记:网络科学揭示5条最重要的成功法则
加入集智,一起复杂!
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











