理解大语言模型——10篇论文的简明清单

导语
理解大语言模型的一份最短阅读清单,应该包含哪些论文?近日一位博主梳理了10篇里程碑式的论文。
关键词:语言模型,机器学习

Sebastian Raschka | 作者
范思雨 | 译者
邓一雪 | 编辑
http://jalammar.github.io/illustrated-transformer/
https://lilianweng.github.io/posts/2020-04-07-the-transformer-family/
https://amatriain.net/blog/transformer-models-an-introduction-and-catalog-2d1e9039f376/
https://github.com/karpathy/nanoGPT
理解大语言模型的结构和任务
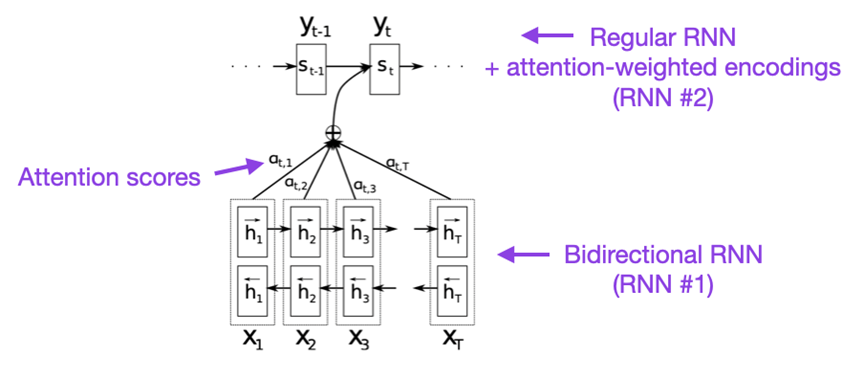
论文题目:Neural Machine Translation by Jointly Learning to Align and Translate (2014) 论文作者:Bahdanau, Cho, Bengio 论文地址:https://arxiv.org/abs/1409.0473
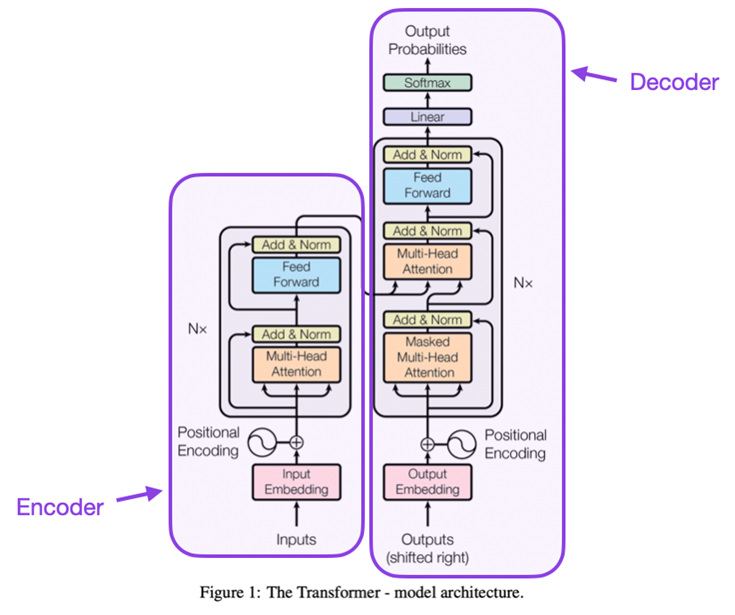
论文题目:Attention Is All You Need (2017) 论文作者:Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin 论文地址:https://arxiv.org/abs/1706.03762
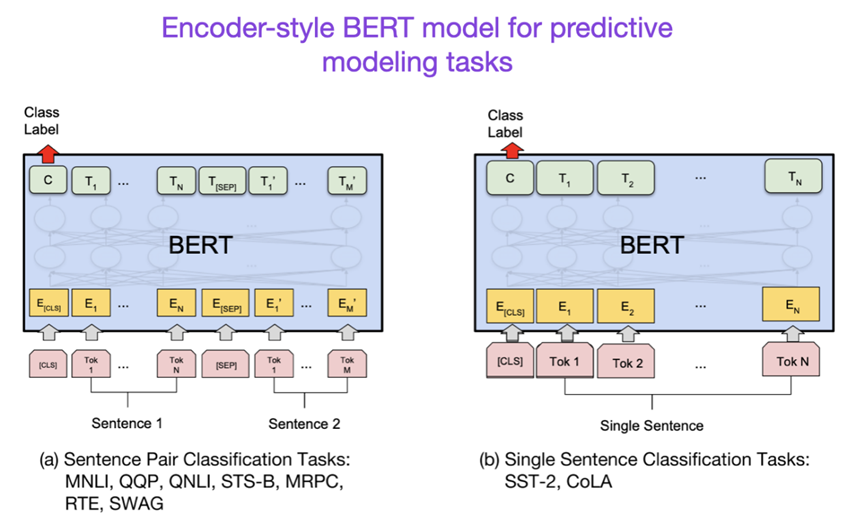
论文题目:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018) 论文作者:Devlin, Chang, Lee, and Toutanova 论文地址:https://arxiv.org/abs/1810.04805
论文题目:RoBERTa: A Robustly Optimized BERT Pretraining Approach 论文地址:https://arxiv.org/abs/1907.11692
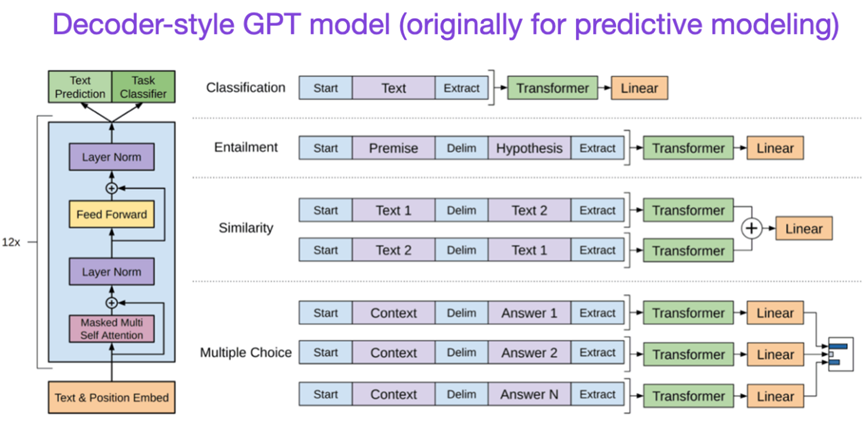
论文题目:Improving Language Understanding by Generative Pre-Training (2018) 论文作者:Radford and Narasimhan 论文地址:https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035
GPT-2 论文 论文题目:Language Models are Unsupervised Multitask Learners 论文地址:https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe
GPT-3 论文 论文题目:Language Models are Few-Shot Learners 论文地址:https://arxiv.org/abs/2005.14165
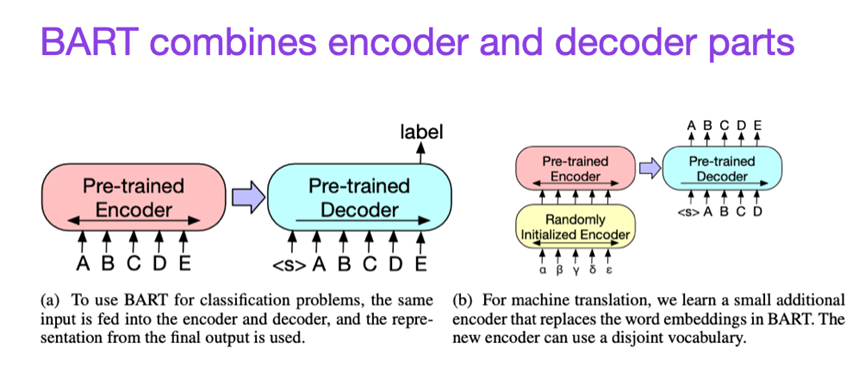
论文题目:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019) 论文作者:Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, and Zettlemoyer 论文地址:https://arxiv.org/abs/1910.13461
规模法则和模型效率提升
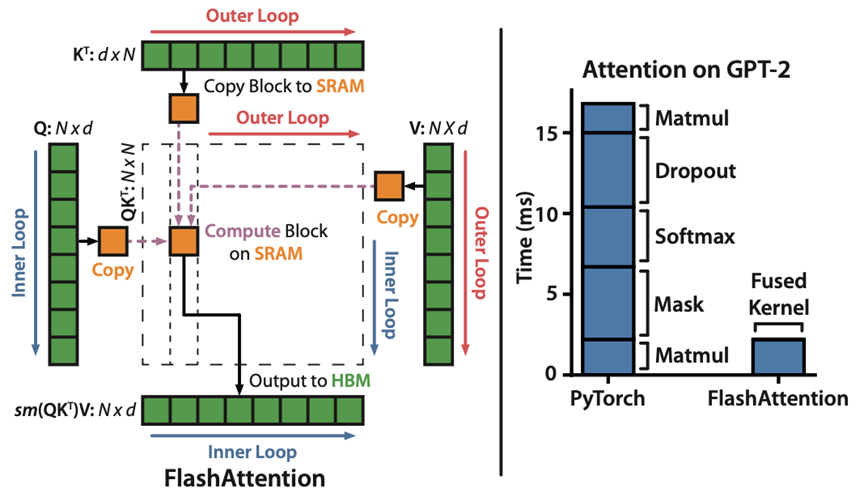
论文题目:Flash Attention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022) 论文作者:Dao, Fu, Ermon, Rudra, and Ré 论文地址:https://arxiv.org/abs/2205.14135
论文题目:Cramming: Training a Language Model on a Single GPU in One Day (2022) 论文作者:Geiping and Goldstein 论文地址:https://arxiv.org/abs/2212.14034

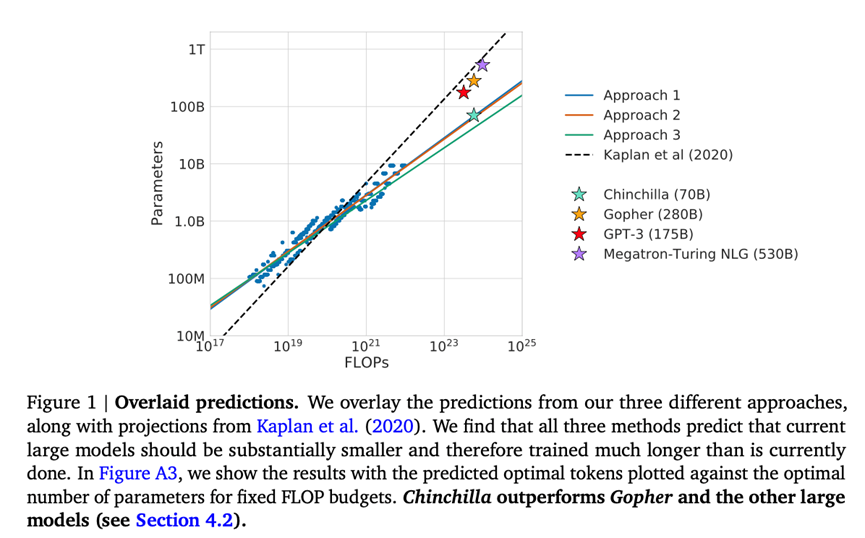
论文题目:Training Compute-Optimal Large Language Models (2022) 论文作者:Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals, and Sifre 论文地址:https://arxiv.org/abs/2203.15556
对齐——引导大语言模型完成训练目标
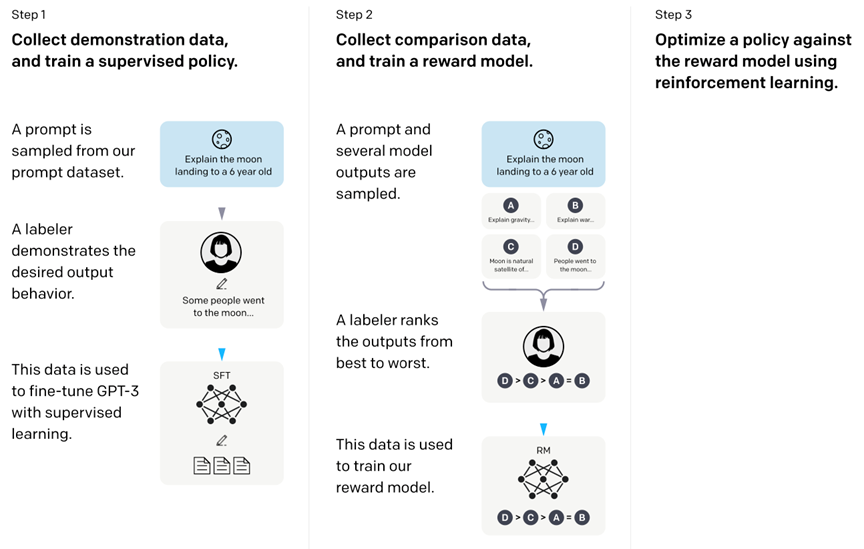
论文题目:Training Language Models to Follow Instructions with Human Feedback (2022) 论文作者:Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, and Lowe 论文地址:https://arxiv.org/abs/2203.02155
论文题目:Constitutional AI: Harmlessness from AI Feedback (2022) 论文作者:Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann, Amodei, Joseph, McCandlish, Brown, Kaplan 论文地址:https://arxiv.org/abs/2212.08073
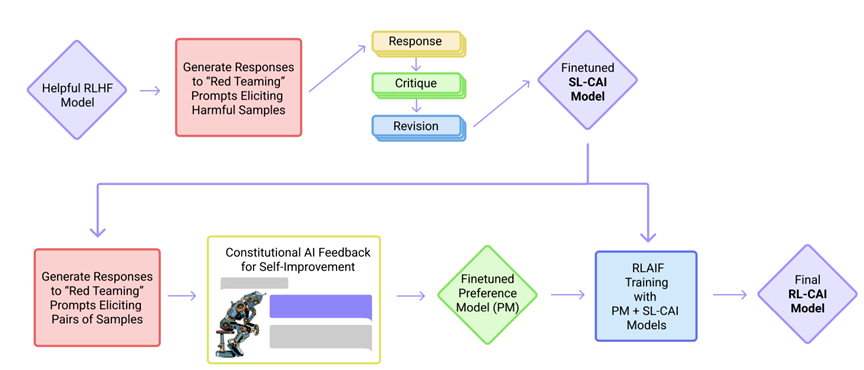
附加阅读清单:
基于人类反馈的强化学习(RLHF)
论文题目:Asynchronous Methods for Deep Reinforcement Learning (2016) 论文作者:Mnih, Badia, Mirza, Graves, Lillicrap, Harley, Silver, and Kavukcuoglu 论文地址:https://arxiv.org/abs/1602.01783
论文题目:Proximal Policy Optimization Algorithms (2017) 论文作者:Schulman, Wolski, Dhariwal, Radford, Klimov 论文地址:https://arxiv.org/abs/1707.06347
论文题目:Learning to Summarize from Human Feedback (2022) 论文作者:Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei, Christiano 论文地址:https://arxiv.org/abs/2009.01325
这篇文章介绍了实现 RLHF 的三步过程:
1. 预训练 GPT-3 模型
2. 对模型进行监督微调
3. 以有监督方法训练奖励模型,然后使用该奖励模型叠加近端策略优化方法以训练出微调模型。

结论以及延伸阅读
-
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model (2022), https://arxiv.org/abs/2211.05100 -
OPT: Open Pre-trained Transformer Language Models (2022), https://arxiv.org/abs/2205.01068
-
LaMDA: Language Models for Dialog Applications (2022), https://arxiv.org/abs/2201.08239 -
(Sparrow) Improving Alignment of Dialogue Agents via Targeted Human Judgements (2022), https://arxiv.org/abs/2209.14375 -
BlenderBot 3: A Deployed Conversational Agent that Continually Learns to Responsibly Rngage, https://arxiv.org/abs/2208.03188
-
ProtTrans: 通过自监督学习和高性能计算破解生命的代码语言
-
使用 AlphaFold 进行高精度蛋白质结构预测
-
利用大语言模型生成跨多个家族和功能的蛋白质序列
原文链接: https://sebastianraschka.com/blog/2023/llm-reading-list.html
“后ChatGPT”读书会启动

推荐阅读
微信扫一扫,分享到朋友圈











