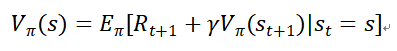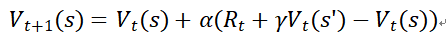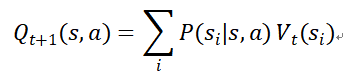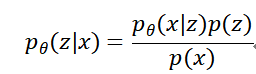
导语:无论是对于生物智能还是人工智能,学习都是一个核心问题。那什么是学习呢?在集智俱乐部「NeuroAI 读书会」中,柳昀哲老师认为,从强化学习的角度,学习即是构建状态空间,并基于状态空间做出一系列选择,目的是趋利避害。柳老师进一步介绍了两种强化学习方式:无模型强化学习(model-free RL)与基于模型的强化学习(model-based RL),并认为在人工智能与生物智能中,两者互相结合可以提高学习表现。本文总结自2022年12月18日柳昀哲老师在集智俱乐部 NeuroAI 读书会的分享报告。
关键词:人工智能,生物智能,强化学习,状态空间
张铄、魏晨 | 作者
刘泉影、李丹、张弛 | 校对
神经计算与控制实验室 | 来源
讲者介绍:柳昀哲老师是北京师范大学认知神经科学与学习国家重点实验室 & 北京脑科学与类脑研究中心研究员。柳昀哲实验室致力于解析人类高级智能行为的计算和神经机制(目前主要关注认知地图的形成与发展)和开发新型的神经编解码模型和脑机接口,为脑疾病和精神疾病的诊疗与调控提供新的手段。
什么是学习?从强化学习的角度,即构建状态空间(state space),并基于状态空间做出的一系列选择,目的是趋利避害。这也是生物智能最核心的功能。本次分享我将从强化学习展开,解读学习的模式,从model-free到model-based;我将讨论如何构建高效的状态空间,以促进学习、决策和泛化。全程将注重神经机制(特别是神经表征)和学习智能的对应。
在报告最开头,柳昀哲老师举了四个心理学的经典研究来引出本次报告“How to learn efficiently”的主要内容。这四个经典研究分别对应了本次报告的四个方面:
1. Learning actions directly from reward(直接从奖励学习)
2. Learning from reward in complex state spaces (在复杂的状态空间中学习)
3. What do those state spaces look like?(状态空间的结构是怎样的)
4. Can we make better state spaces to make learning easy?(如何构建更好的状态空间使学习更加高效)
5. Making state spaces that are good for other things too (like planning) (状态空间用于其他任务,如规划任务)
6. Making state spaces from bits of other state spaces (从其他状态空间构建新的状态空间)
以下我们也将从这六个方面来对这次柳昀哲老师分享报告进行总结。
1. Learning actions directly from reward (直接从奖励学习)
在报告中柳老师提到了强化学习[2](Reinforcement Learning, RL)与马尔科夫决策过程(Markov Decision Process,MDP),并举了一个“PI晋升”的例子来说明现实中如何利用奖励(reward)来学习。
这里我们对比一下监督学习与强化学习,来理解‘直接利用奖励来学习’。
监督学习的学习信号是‘例子’(examplar),通过最小化损失函数来优化模型。最好的监督学习模型应该能够完美模仿训练数据(即,得到与训练数据label一致的输出)。
强化学习的学习信号是‘奖励’(reward),通过贝尔曼方程来进行value迭代、最小化误差(value函数与真实累积奖励的误差)从而优化模型。最好的强化学习模型不是能够完美模仿训练数据,而是能够通过训练数据的奖励来找到一个可以最大化累积奖励的行动策略(类似于强化学习模型会更加偏向于选择能获得更多奖励的action)。
贝尔曼方程(Bellman Equation),也被称作动态规划方程(Dynamic Programming Equation),由理查·贝尔曼(Richard Bellman)提出。贝尔曼方程是动态规划(Dynamic Programming)数学优化方法能够达到最优化的必要条件。此方程把“决策问题在特定时间怎么的值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。因此,借此这个方式,贝尔曼方程把动态最优化问题变成简单的子问题,用来简化强化学习或者马尔可夫决策问题。贝尔曼方程如下:
2. Learning from reward in complex state spaces (在复杂的状态空间中学习)
在复杂的状态空间中学习,需要针对不同的环境和需求,采用不同的学习方式。
在报告中柳老师说明了强化学习中的无模型强化学习 (model-free RL) 与基于模型的强化学习 (model-based RL),并引用多篇文章来说明大脑的学习中同时应用了这两种强化学习方式。
下面我们简单介绍下model-free RL与model-based RL。
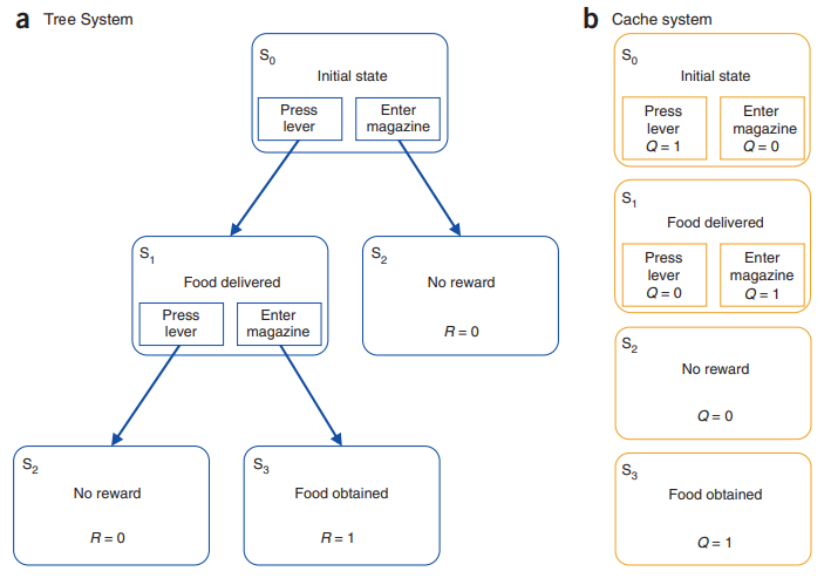
无模型的强化学习:它只编码状态-动作对与价值函数的映射关系 (s,a)→Q(s,a),即只会基于奖励R,学习在某个状态s下做出某个动作a所对应的动作状态价值函数Q(s,a)。在model-free RL学习过程中,模型只是会通过时间差分学习(Temporal Differences learning,TD learning)来更新价值函数,每次学习只更新相应状态的价值函数。
基于模型的强化学习:除了编码价值函数之外,还编码了环境的状态转移概率。在model-based RL对应的学习过程中,模型可以通过状态转移概率来对所有状态的价值函数进行更新。
Model-free RL十分简单(认知负荷低),但价值函数的更新较慢,(数据)效率低,在稳定的环境更加准确,但是不适用于不断变化的环境。
Model-based RL较为复杂(认知负荷高),模型的复杂度会随着状态的增加以指数级的增加,但(数据)效率高,可以成功应用于不断变化的环境中。
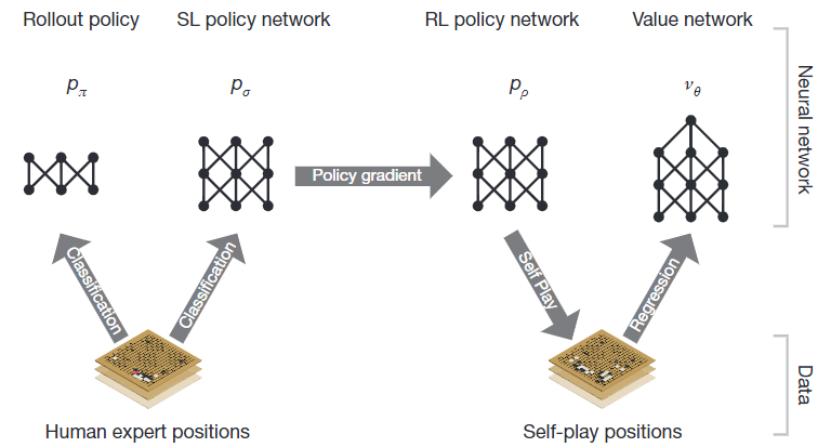
图1:Mastering the game of Go with deep neural networks and tree search, Silver et al (2016)[4]
在人工智能与生物智能中,无模型的学习与基于模型的学习都可以互相结合来提高表现。
在AlphaGo [Silver et al 2016, Nature][4]中,基于模型的树搜索与无模型的Q-learning相结合,通过树搜索N步之后停止,之后的用价值函数替代,如图1,成功将基于模型(数据效率高,价值函数更新速度快)和无模型(复杂度低,表达性强)的优势结合起来。
图2:前额叶和背外侧纹状体系统之间基于不确定性的行为控制竞争,Daw et al (2005)[3]
在生物智能中,有许多研究发现大脑同时利用了基于模型的和无模型的算法,并且两种算法在大脑当中同时存在竞争与合作的关系。
在图2的这篇文章中[Daw et al 2005, Nature Neuroscience][3],作者用小鼠的行为数据论证了基于模型的算法与无模型的算法的竞争关系是与不确定性相关的,即大脑会利用不确定性低的算法:在任务初期,基于模型的算法能够更快的学习到价值函数也就有着更小的不确定性;在任务后期,无模型的算法能够在这种稳定的环境中学习到更加稳定、准确的价值函数,此时无模型的算法的不确定性更小。
在图3的这篇文章中[5],作者用人类被试的行为数据论证了大脑当中同时使用了无模型与基于模型的算法,因为被试的行为数据的模式不同于纯的无模型的算法或基于模型的算法(模拟数据),而更接近于无模型的算法与基于模型的算法的混合。
图3:基于模型的对人类选择的影响和纹状体预测的误差, Daw et al (2011)[5]
在大脑中,无模型的算法的实现与前额皮质系统有关,而基于模型的算法的实现与背外侧纹状体系统有关,除此之外还有许多研究表明[Miller et al 2017] [6]海马体与基于模型的算法的实现也有紧密的联系。
3. What do those state spaces look like?(状态空间的结构是怎样的?)
柳老师向我们阐述了生物如何对物理空间进行建模,以解释状态空间的概念。寻路过程中,生物需要将自己所处的物理空间进行建模,需要对特定地点进行记忆,并判断距离,进行路径规划。为了实现这些目的,生物的大脑需要拥有一种高效的神经机制。
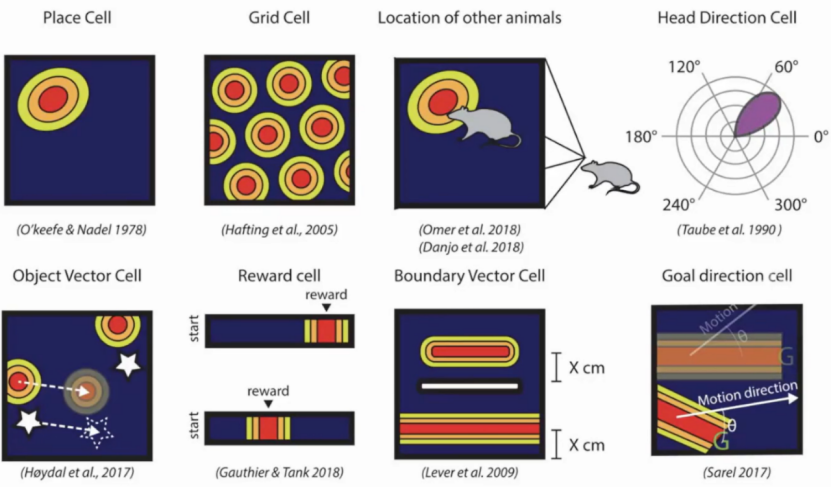
研究发现,海马(Hippocampus)中的位置细胞(Place cell)与该功能密切相关。随后,研究者又发现了多种细胞类型,包括网格细胞(Grid Cell)和方向细胞(Object Vector Cell)等(图4)。在这些细胞中,位置细胞和网格细胞是最重要的两种,分别负责特定位置的表征和相对位置的表征。后续的研究发现,这些细胞不仅可以表征物理空间,还可以表征抽象空间,例如人际关系和物体相似性等。
图4 物理空间表征相关的神经细胞[7][8][9][10][11][12][13][14]
4. Can we make better state spaces to make learning easy?(如何构建更好的状态空间使学习更加高效)
在这一小节,柳老师主要讲了我们如何建立起更好的状态空间。在真实世界中,状态、动作空间都是连续的,我们不可能使用表格来对每一个状态进行表征。在强化学习中对于连续状态、动作空间的处理就是:方程约化 (Function approximation)。目前最火的方程约化的方式就是神经网络,神经网络+强化学习=深度强化学习(图5)。
深度强化学习实际上就是深度学习强大的表征能力与强化学习算法结合,使得强化学习能够应用在更多领域。但是深度学习与深度强化学习学习出来的状态表征实际上是不同的,原因在于深度强化学习仍然也是从奖励信号来学习的。相关研究[Cross, et al, 2021, Neuron][15]中发现:与基于深度学习得到的状态表征相比,基于深度强化学习得到的状态表征可能更加接近真实大脑中的状态表征。
5. Making state spaces that are good for other things too (like planning)(状态空间用于其他任务,如规划任务)
在这一小节,柳老师提出了一个好的状态表征的几个特点:
1. 预测性:预测类似结果的状态(例如,继承表征)
2. 低维:维度越少,学习越好
3. 分层:分别表征粗粒度或细粒度
4. 可迁移:同一表征支持多种不同任务
5. 可解耦/可组合:可独立推理的维度是正交的
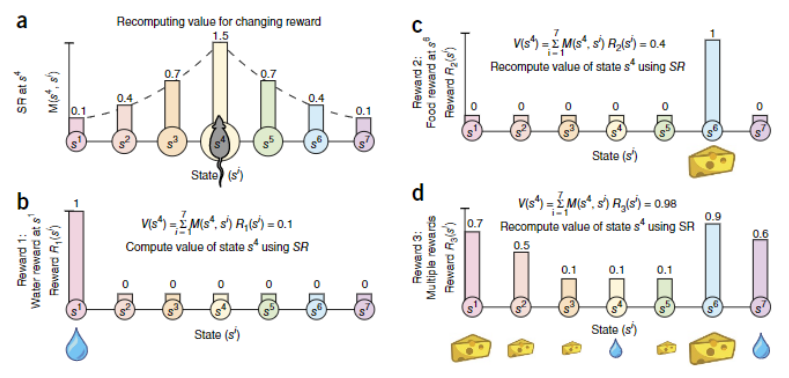
其中预测性这一标准:预测性的表征 (Successor representations) 能够更快的适应奖励条件变化的环境;同时有着无模型学习与基于基于模型的优势(可以通过TD-learning更新的拓展性,对状态进行建模的灵活性)。
图6:海马体是一种预测性地图, Stachenfeld et al (2017)[16]
在相关研究中表明,见[Stachenfeld et al, 2017, Nature Neuroscience][16],与实时的表征相比,大脑对于位置的表征更接近于预测性的表征(编码当前状态的累计频率)(图6)。
在报告中柳老师还提到了一个问题:How do we get these state spaces that our input is sensory?
从贝叶斯统计的角度来看,我们可以通过感官数据来推测出隐变量 (Latent variables) :
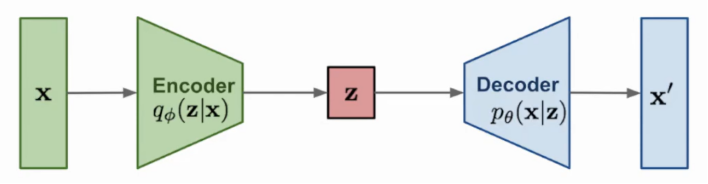
另一方面我们还可以使用生成模型来得到状态表征,例如VAE [Kingma & Welling 2013][17](图7),或GAN [Goodfellow et al 2014][18]。
生成模型(Generative model)是一种可以生成数据的模型(生成的数据应类似于真实数据)。例如,我们接收了从分布P_data取样的若干样本构成我们的训练集,我们的模型可以学习到一个能够模拟这一分布的概率分布P_model。从而通过对P_model采样,可以生成以假乱真的数据。常见的生成模型有autoregressive模型、VAE、GAN、flow模型及其变种等等。
图7:VAE (Variational auto-encoder)示意图, Kingma & Welling (2013)[17]
6. Making state spaces from bits of other state spaces(从其他状态空间构建新的状态空间)
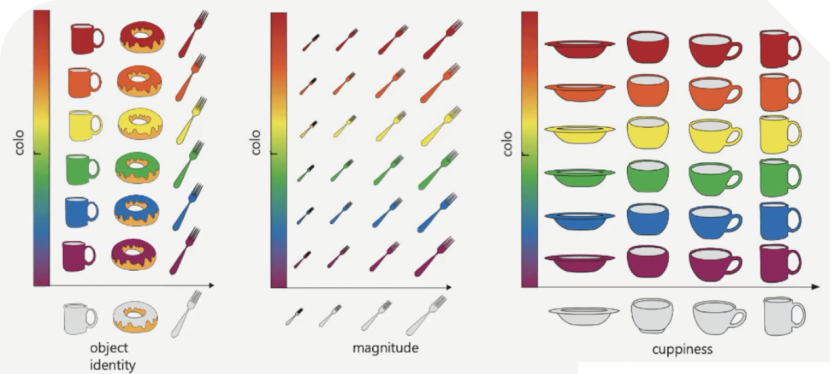
最后一部分,柳老师讲述了如何通过已有的状态空间来构建新的状态空间。解耦/组合(Disentangling/Factorizing)表征指状态空间可以被分成多个独立的子状态空间。
如图8所示[19],可以看到,物体的整体特征可以由许多个单独的特征共同来描述。在具体实现上也非常简单,在上述的VAE的loss中加入对隐变量解耦程度的惩罚项就可以使其中的单个隐变量能够对应单个特征。
图8 解耦状态空间, Behrens et al (2018)[19]
[1] 【脑客中国·科研】第35位讲者:柳昀哲 人类基于认知地图的灵活学习和决策机制:https://www.bilibili.com/video/BV1hQ4y1U77y/
[2] Sutton, R. S., & Barto, A. G. (1998). Introduction to reinforcement learning (Vol. 135, pp. 223-260). Cambridge: MIT press.
[3] Daw, N. D., Niv, Y., & Dayan, P. (2005). Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature neuroscience, 8(12), 1704-1711.
[4] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., … & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. nature, 529(7587), 484-489.
[5] Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P., & Dolan, R. J. (2011). Model-based influences on humans’ choices and striatal prediction errors. Neuron, 69(6), 1204-1215.
[6] Miller, K. J., Botvinick, M. M., & Brody, C. D. (2017). Dorsal hippocampus contributes to model-based planning. Nature neuroscience, 20(9), 1269-1276.
[7] O’keefe, J., & Nadel, L. (1979). Précis of O’Keefe & Nadel’s The hippocampus as a cognitive map. Behavioral and Brain Sciences, 2(4), 487-494.
[8] Hafting, T., Fyhn, M., Molden, S., Moser, M. B., & Moser, E. I. (2005). Microstructure of a spatial map in the entorhinal cortex. Nature, 436(7052), 801-806.
[9] Omer, D. B., Maimon, S. R., Las, L., & Ulanovsky, N. (2018). Social place-cells in the bat hippocampus. Science, 359(6372), 218-224.
[10] Danjo, T., Toyoizumi, T., & Fujisawa, S. (2018). Spatial representations of self and other in the hippocampus. Science, 359(6372), 213-218.
[11] Taube, J. S., Muller, R. U., & Ranck, J. B. (1990). Head-direction cells recorded from the postsubiculum in freely moving rats. I. Description and quantitative analysis. Journal of Neuroscience, 10(2), 420-435.
[12] Gauthier, J. L., & Tank, D. W. (2018). A dedicated population for reward coding in the hippocampus. Neuron, 99(1), 179-193.
[13] Lever, C., Burton, S., Jeewajee, A., O’Keefe, J., & Burgess, N. (2009). Boundary vector cells in the subiculum of the hippocampal formation. Journal of Neuroscience, 29(31), 9771-9777.
[14] Sarel, A., Finkelstein, A., Las, L., & Ulanovsky, N. (2017). Vectorial representation of spatial goals in the hippocampus of bats. Science, 355(6321), 176-180.
[15] Cross, L., Cockburn, J., Yue, Y., & O’Doherty, J. P. (2021). Using deep reinforcement learning to reveal how the brain encodes abstract state-space representations in high-dimensional environments. Neuron, 109(4), 724-738.
[16] Stachenfeld, K. L., Botvinick, M. M., & Gershman, S. J. (2017). The hippocampus as a predictive map. Nature neuroscience, 20(11), 1643-1653.
[17] Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
[18] Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
[19] Behrens, T. E., Muller, T. H., Whittington, J. C., Mark, S., Baram, A. B., Stachenfeld, K. L., & Kurth-Nelson, Z. (2018). What is a cognitive map? Organizing knowledge for flexible behavior. Neuron, 100(2), 490-509.
神经科学和人工智能领域的多位著名学者近日发表 NeuroAI 白皮书认为,神经科学长期以来一直是推动人工智能(AI)发展的重要驱动力,NeuroAI 领域的基础研究将推动下一代人工智能的进程。文章发表后引发热议:神经科学是否推动了人工智能?未来的人工智能是否需要神经科学?
本着促进神经科学、计算机科学、认知科学和脑科学等不同领域的学术工作者的交流与合作,集智俱乐部联合北京师范大学柳昀哲、北京大学鲍平磊和昌平实验室吕柄江三位研究员共同发起了「NeuroAI」读书会,聚焦在视觉、语言和学习领域中神经科学与人工智能的相关研究,期待能够架起神经科学与人工智能领域的合作桥梁,激发跨学科的学术火花。
推荐阅读