自由能原理与强化学习读书会启动:探索感知和行动的统一原理

导语
自由能原理被认为是“自达尔文自然选择理论后最包罗万象的思想”,它试图从物理、生物和心智的角度提供智能体感知和行动的统一性规律,从第一性原理出发解释智能体更新认知、探索和改变世界的机制,从而对人工智能,特别是强化学习世界模型、通用人工智能研究具有重要启发意义。
集智俱乐部联合北京师范大学系统科学学院博士生牟牧云,南京航空航天大学副教授何真,以及骥智智能科技算法工程师、公众号 CreateAMind 主编张德祥,共同发起「自由能原理与强化学习读书会」,希望探讨自由能原理、强化学习世界模型,以及脑与意识问题中的预测加工理论等前沿交叉问题,探索这些不同领域背后蕴含的感知和行动的统一原理。读书会从3月10日开始,每周日上午10:00-12:00,持续时间预计8-10周。欢迎感兴趣的朋友报名参与!

读书会背景
读书会背景
读书会框架
读书会框架
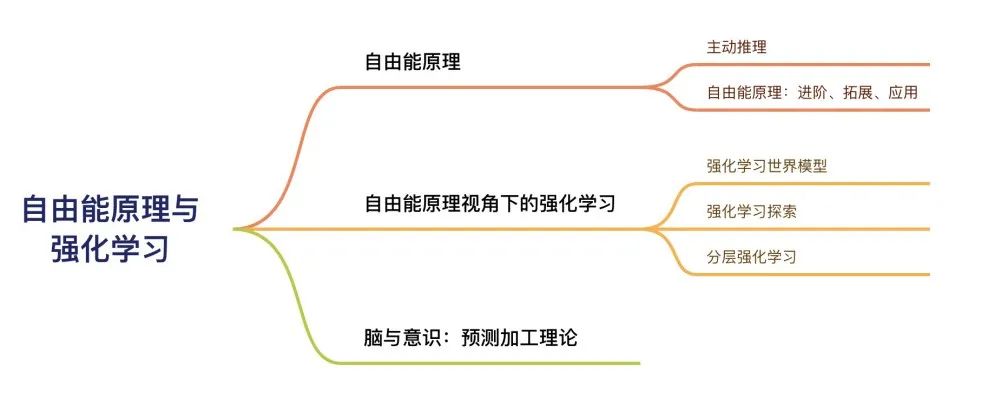
与复杂系统的关系
与复杂系统的关系
读书会发起人
读书会发起人



本季读书会运营负责人
梁金,统计物理硕士,集智俱乐部副主编。兴趣领域:物理,因果涌现,科普写作。
读书会讲者招募
读书会讲者招募
报名参与读书会
报名参与读书会
本读书会适合参与的对象
-
基于复杂系统相关学科研究,对自由能原理、强化学习世界模型、脑认知与意识理论等主题有有浓厚兴趣的科研工作者; -
具有一定复杂系统建模、人工智能、神经科学、物理、控制论、信息论、生物等相关领域学科背景,想进一步进行交叉学科研究与交流的学者、研究生、本科生。 -
对复杂科学充满激情,对认知、智能和意识问题充满好奇的探索者,且具备一定的英文文献阅读能力。 -
想锻炼自己科研能力或者有出国留学计划的高年级本科生及研究生。
本读书会谢绝参与的对象
运行模式
举办时间
参与方式

扫码报名读书会
加入社区后可以获得的资源
-
在线会议室沉浸式讨论:与主讲人即时讨论交流
-
交互式播放器高效回看:快速定位主讲人提到的术语、论文、大纲、讨论等重要时间点
-
高质量的主题微信社群:硕博比例超过80%的成员微信社区,闭门夜谈和交流
-
超多学习资源随手可得:从不同尺度记录主题下的路径、词条、前沿解读、算法、学者等
-
参与社区内容共创任务:读书会笔记、百科词条、公众号文章、论文解读分享等不同难度共创任务,在学习中贡献,在付出中收获。
-
共享追踪主题前沿进展:在群内和公众号分享最新进展,领域论文速递
参与共创任务,共建学术社区
-
读书会笔记:在交互式播放器上记录术语和参考文献
-
集智百科词条:围绕读书会主题中重要且前沿的知识概念梳理成词条。例如:
-
论文解读分享:认领待读列表中的论文,以主题报告的形式在社区分享
-
公众号文章:以翻译整理或者原创生产形式生产公众号文章,以介绍前沿进展。例如:
-
论文翻译
-
科普文章翻译
-
讲座整理
阅读材料
阅读材料

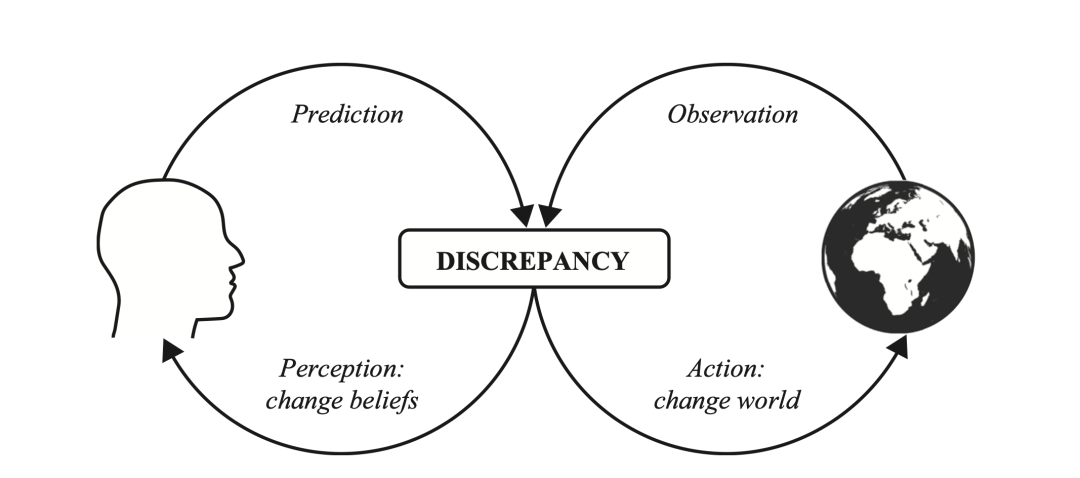
1.1 自由能原理概览介绍
-
Parr, Thomas, Giovanni Pezzulo, and Karl J. Friston. Active inference: the free energy principle in mind, brain, and behavior. MIT Press, 2022.

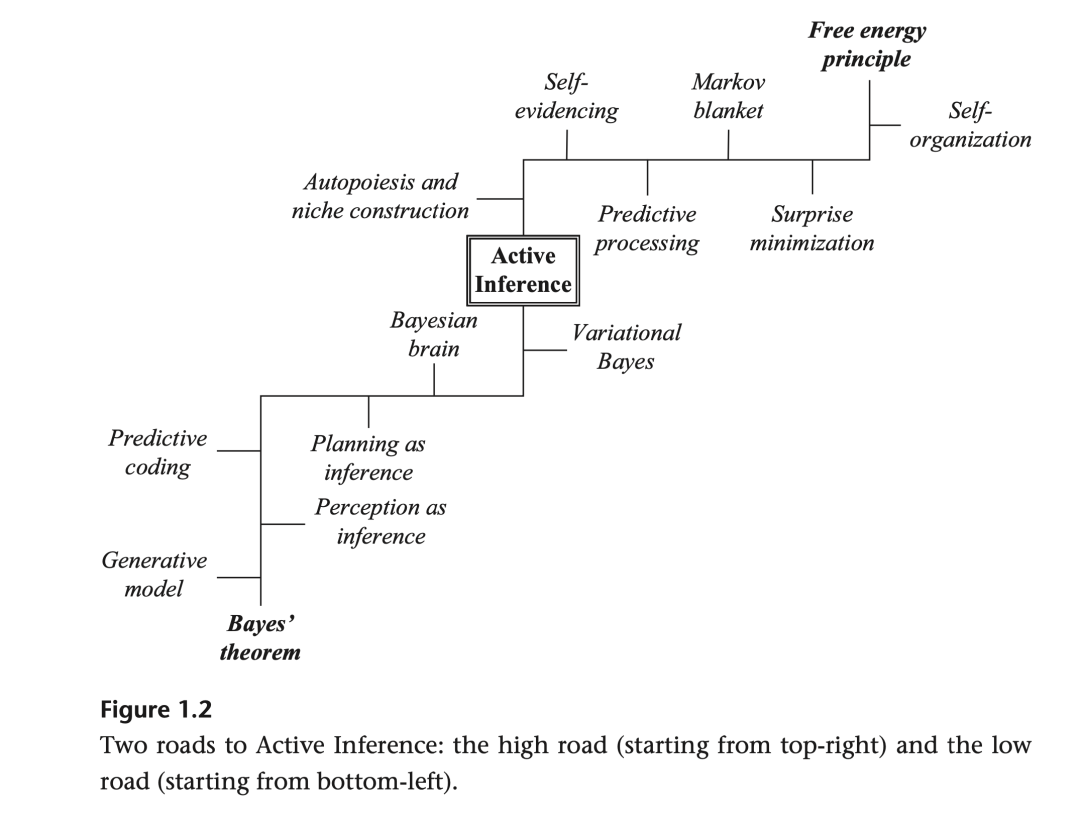
《主动推理》书中第一章所描述的“主动推理的两条道路”
1.2 自由能原理详细介绍
-
Friston, Karl, James Kilner, and Lee Harrison. A free energy principle for the brain. Journal of physiology-Paris 100.1-3 (2006): 70-87.
自由能原理奠基性论文。本文从统计物理学出发得到关于感知推理和学习的模型,展示了感知过程是符合自由能原理的系统涌现行为的一个方面。这里考虑的自由能度量了作用于系统的环境数量的概率分布与系统构型的任意分布之间的差异。系统有两种方式来最小化自由能,通过改变其构型以影响对环境的采样方式,或者改变它所编码的分布。这些变化分别对应于行动和感知,并导致与环境的适应性交换,这是生物系统的特征。文章研究了如何通过最小化自由能来解释大脑的动力学和结构。
-
Friston, K. The free-energy principle: a unified brain theory?. Nat Rev Neurosci 11, 127–138 (2010). https://doi.org/10.1038/nrn2787
自由能原理经典奠基性综述
-
Smith, Ryan, Karl J. Friston, and Christopher J. Whyte. A step-by-step tutorial on active inference and its application to empirical data. Journal of mathematical psychology 107 (2022): 102632.
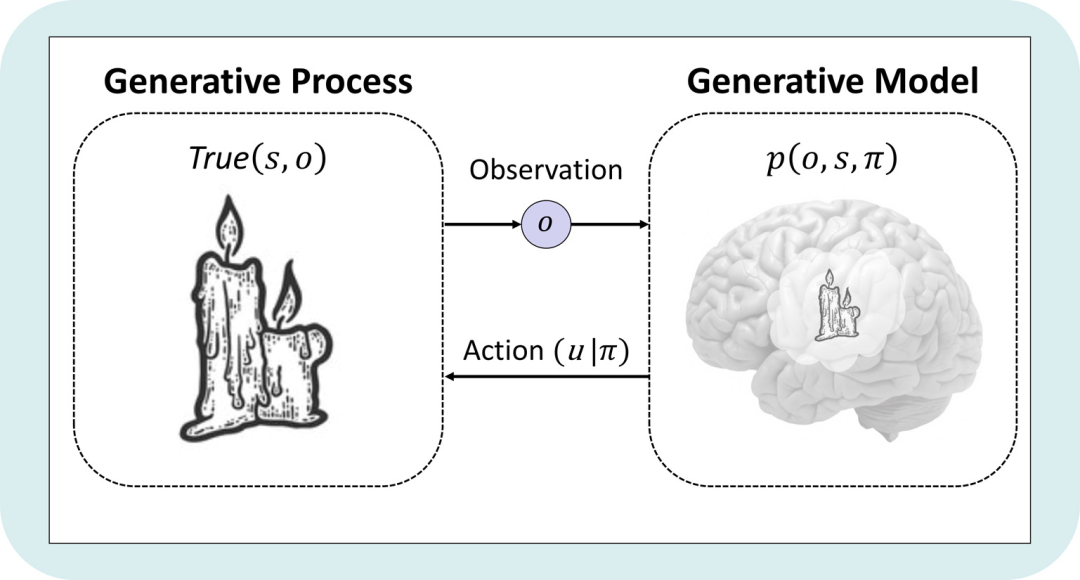
-
Friston K J, Salvatori T, Isomura T, et al. Active Inference and Intentional Behaviour[J]. arXiv preprint arXiv:2312.07547, 2023.
理论生物学的进展表明,基础认知和感知行为分别是体外细胞培养和神经元网络的涌现特性。这种神经网络在没有奖励或强化的情况下自发学习结构化行为。本文通过自由能量原理视角对这种自组织的有目的行为进行了刻画。
-
Friston, Karl, et al. The free energy principle made simpler but not too simple. Physics Reports 1024 (2023): 1-29. https://www.sciencedirect.com/science/article/pii/S037015732300203X

-
Smith, Ryan, Maxwell JD Ramstead, and Alex Kiefer. Active inference models do not contradict folk psychology. Synthese 200.2 (2022): 81.
对自由能原理公式的含义进行了细致深入的讲解
-
Pezzulo, Giovanni, Thomas Parr, and Karl Friston. Active inference as a theory of sentient behavior. Biological Psychology (2024): 108741. https://www.sciencedirect.com/science/article/pii/S0301051123002612
更多相关论文
-
Friston, K., Rigoli, F., Ognibene, D., Mathys, C., Fitzgerald, T., & Pezzulo, G. (2015). Active inference and epistemic value. Cognitive neuroscience, 6(4), 187-214. -
van de Laar, T., Koudahl, M., van Erp, B., & de Vries, B. (2022). Active Inference and Epistemic Value in Graphical Models. Frontiers in Robotics and AI, 9, 794464. -
Ororbia, A., & Friston, K. (2023). Mortal computation: A foundation for biomimetic intelligence. arXiv preprint arXiv:2311.09589. -
Andrews, Mel. The math is not the territory: navigating the free energy principle. Biology & Philosophy 36.3 (2021): 30. -
Friston, Karl, et al. Active inference: a process theory. Neural computation 29.1 (2017): 1-49. -
Friston, Karl, et al. Path integrals, particular kinds, and strange things. Physics of Life Reviews (2023).
1.3 自由能原理的工程实现
-
Feldman, Harriet, and Karl J. Friston. Attention, uncertainty, and free-energy. Frontiers in human neuroscience 4 (2010): 215.
这篇文章通过不确定性和自由能原理的视角探讨了注意力的概念,提出注意力可以被理解为在分层感知过程中推断出的不确定性或精确度水平。
-
De Vries, Bert, and Karl J. Friston. A factor graph description of deep temporal active inference. Frontiers in computational neuroscience 11 (2017): 95. -
Friston, Karl J., Thomas Parr, and Bert de Vries. The graphical brain: Belief propagation and active inference. Network neuroscience 1.4 (2017): 381-414. -
Da Costa, Lancelot, et al. Active inference on discrete state-spaces: A synthesis. Journal of Mathematical Psychology 99 (2020): 102447. -
Friston, Karl, Thomas Parr, and Peter Zeidman. Bayesian model reduction. arXiv preprint arXiv:1805.07092 (2018).
这篇文章中提出贝叶斯模型约简方法,使用自由能作为模型比较和选择的指标,通过最小化变分自由能来最大化模型的证据,从而有效地评估候选网络结构的证据。
-
Friston, Karl J., et al. Bayesian model reduction and empirical Bayes for group (DCM) studies. Neuroimage 128 (2016): 413-431.
使用贝叶斯模型约简方法来进行动态因果建模,以推断功能性大脑结构和潜在有效连接的非线性状态空间模型。
-
Mazzaglia, Pietro, et al. The free energy principle for perception and action: A deep learning perspective. Entropy 24.2 (2022): 301.
2.1 强化学习世界模型
强化学习算法可以分为无模型(model-free)强化学习与有模型(model-based)强化学习,后者中的模型也被称为世界模型。在基于世界模型的强化学习方法中,智能体首先学习一个关于环境的内嵌的模型,在内嵌的模型中学习行为决策,从而提高在真实环境中的表现。强化学习世界模型的优点是减少对真实环境的采样需求,提高数据利用率,增强泛化能力和适应性;挑战则是如何构建准确和可靠的环境模拟,如何平衡模拟和真实的探索,如何处理模型偏差和不确定性等。
-
Moerland T M, Broekens J, Plaat A, et al. Model-based reinforcement learning: A survey[J]. Foundations and Trends in Machine Learning, 2023, 16(1): 1-118.
基于模型的强化学习综述,涉及状态抽象、动作分层
-
Luo F M, Xu T, Lai H, et al. A survey on model-based reinforcement learning[J]. arXiv preprint arXiv:2206.09328, 2022.
基于模型的强化学习综述文章
-
Friston K, Moran R J, Nagai Y, et al. World model learning and inference[J]. 2021.
这篇文章在自由能原理框架下对人类认知和行为进行解释,并讨论世界模型在真实机器人中的前沿方法,最后比较了人工智能和人类智能,强调了世界模型和概率推理的重要性。
-
Wang T, Du S S, Torralba A, et al. Denoised mdps: Learning world models better than the world itself[J]. arXiv preprint arXiv:2206.15477, 2022.
-
【Dreamer V1】Hafner D, Lillicrap T, Ba J, et al. Dream to control: Learning behaviors by latent imagination[J]. arXiv preprint arXiv:1912.01603, 2019.
基于模型的强化学习方法,学习隐空间的世界模型,提高了数据利用率与计算效率,同时取得了很好的控制效果。
-
【Dreamer V2】Hafner D, Lillicrap T, Norouzi M, et al. Mastering atari with discrete world models[J]. arXiv preprint arXiv:2010.02193, 2020.
Dreamer 后续改进,将隐空间的连续高斯分布改进为离散的类别分布。
-
【Dreamer V3】Hafner D, Pasukonis J, Ba J, et al. Mastering diverse domains through world models[J]. arXiv preprint arXiv:2301.04104, 2023.
-
Saxena V, Ba J, Hafner D. Clockwork variational autoencoders[J]. Advances in Neural Information Processing Systems, 2021, 34: 29246-29257.
学习时空多尺度的生成模型。
-
Hafner D, Ortega P A, Ba J, et al. Action and perception as divergence minimization[J]. arXiv preprint arXiv:2009.01791, 2020.
这篇文章中将主动推理的思想用于解释各种不同的深度学习强化学习算法,包括最大似然估计、VAE,强化学习中的Skill Discovery、Empowerment、最大熵奖励等。
在强化学习中,智能体需要在探索和利用之间找到平衡(exploration and exploitation),即在利用已知的最优策略获得最大即时奖励的同时,也要探索未知的状态和动作,以期望获得更大的长期奖励。强化学习探索的方法大致可以分为基于状态不确定性的探索和基于智能体内在动机的探索。在基于模型的强化学习中,智能体进行有效探索可以提高模型学习准确性,更好地理解和适应环境,从而在各种任务中取得更好的性能。
-
Ladosz P, Weng L, Kim M, et al. Exploration in deep reinforcement learning: A survey[J]. Information Fusion, 2022, 85: 1-22.
在稀疏奖励问题中,智能体难以通过随机行动获得奖励,因而需要考虑更复杂的探索方法。这篇文章提供了现有强化学习探索方法的全面综述。
-
Hao J, Yang T, Tang H, et al. Exploration in deep reinforcement learning: From single-agent to multiagent domain[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023.
如何高效地探索环境并收集信息,从而帮助策略学习?这篇论文提供了关于单智能体和多智能体强化学习探索方法的全面综述。
-
Sekar R, Rybkin O, Daniilidis K, et al. Planning to explore via self-supervised world models[C]//International Conference on Machine Learning. PMLR, 2020: 8583-8592.
2.3 分层强化学习
分层强化学习(Hierarchical reinforcement learning,简称 HRL)是一种强化学习方法,通过将复杂的任务分解为多个层级的子任务来提高学习效率和泛化能力。主要动机是解决强化学习中的稀疏奖励、长时序决策和弱迁移能力等问题。基本思想是模仿人类和动物的分层学习机制,利用时间和空间的抽象,构建不同层次的策略和目标,实现自上而下的控制和自下而上的反馈。
分层强化学习的优点是可以减少探索空间,提高样本利用率,增强泛化能力和适应性,缓解维度灾难和信用分配问题。挑战是如何设计合适的层级结构,平衡探索和利用,处理层级间的协调和冲突,评估分层强化学习的性能等。分层强化学习已经在许多领域和应用中取得了成果,包括机器人控制、自然语言处理、视频游戏、推荐系统等。
分层强化学习综述:
-
Nachum, Ofir, et al. Why does hierarchy (sometimes) work so well in reinforcement learning?. arXiv preprint arXiv:1909.10618 (2019). -
Pateria, Shubham, et al. Hierarchical reinforcement learning: A comprehensive survey. ACM Computing Surveys (CSUR) 54.5 (2021): 1-35. -
Hutsebaut-Buysse, Matthias, Kevin Mets, and Steven Latré. Hierarchical reinforcement learning: A survey and open research challenges. Machine Learning and Knowledge Extraction 4.1 (2022): 172-221.
-
Shi, Lucy Xiaoyang, Joseph J. Lim, and Youngwoon Lee. Skill-based model-based reinforcement learning. arXiv preprint arXiv:2207.07560 (2022).
-
Friston, Karl J., Jean Daunizeau, and Stefan J. Kiebel. Reinforcement learning or active inference?. PloS one 4.7 (2009): e6421.
3. 脑与意识:预测加工理论
预测加工理论可以看作是自由能原理在感知和学习领域的应用,解释大脑如何通过最小化预测误差来理解环境。该模块从脑与认知的角度出发,重点讨论和主动推理密切相关的预测加工理论如何解释各种看似功能各异的认知现象。
-
《预测算法:具身智能如何应对不确定性》,机械工业出版社(2020)
物质如何产生感知、思维、梦境和创造力?我们的大脑如何理解思想、理论和概念?所有这些非物质的精神状态,包括意识本身到底根植于何处?这本书从预测加工理论出发,认为高级生物已经演化成为善于预测传入感知刺激流的复杂装置,这些预测会引发行动,构建我们的世界,并改变我们需要参与和预测之物。

-
《千脑智能》,浙江教育出版社(2020)
通俗易懂的科普读物,该书中提出的“千脑智能”理论与主动推理、预测加工等理论类似,认为大脑通过运动进行学习,但该理论认为大脑不只学习一种世界模型,而是学习若干互补模型。此外,大脑利用参考系存储知识,以跟踪我们的感官相对于世界上食物的位置。
-
Park HJ, Friston K. Structural and functional brain networks: from connections to cognition. Science. 2013 Nov 1;342(6158):1238411. doi: 10.1126/science.1238411. PMID: 24179229.
不同的功能是如何从看似静态的神经结构中产生的?这篇较早的文章总结了对大脑网络理解的进展,研究它们是如何阐明大脑多对一的(简并的)功能-结构关系。文章得出结论,从静态的结构连接中产生动态的功能连接,这需要形式化(计算)的方法来处理神经信息,这可能解决结构与功能之间的辩证关系。
-
Salvatori, Tommaso, et al. Brain-inspired computational intelligence via predictive coding. arXiv preprint arXiv:2308.07870 (2023). -
Friston, Karl J., et al. Bayesian model reduction and empirical Bayes for group (DCM) studies. Neuroimage 128 (2016): 413-431. https://www.sciencedirect.com/science/article/pii/S105381191501037X -
Friston, Karl, Thomas Parr, and Peter Zeidman. Bayesian model reduction. arXiv preprint arXiv:1805.07092 (2018). https://arxiv.org/abs/1805.07092

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











