关键词:自动数据提取,大语言模型,
论文题目:Extracting accurate materials data from research papers with conversational language models and prompt engineering
论文期刊:Nature Communications
https://www.nature.com/articles/s41467-024-45914-8
自动数据提取越来越多地用于开发材料科学和其他领域的数据库。自动化方法需要花费大量的精力来设置,要么准备解析规则(即预先定义用于识别相关单元的规则列表或识别属性的特定短语等),要么微调或重新训练模型或两者的某种组合,专门用于执行特定任务的方法。微调非常耗费资源和时间,并且需要大量准备训练数据,而大多数研究人员可能无法获得这些数据。大语言模型(LLM)出现使得准确提取复杂数据的能力显著增强,但专业知识和编码等前期工作仍然必不可少。
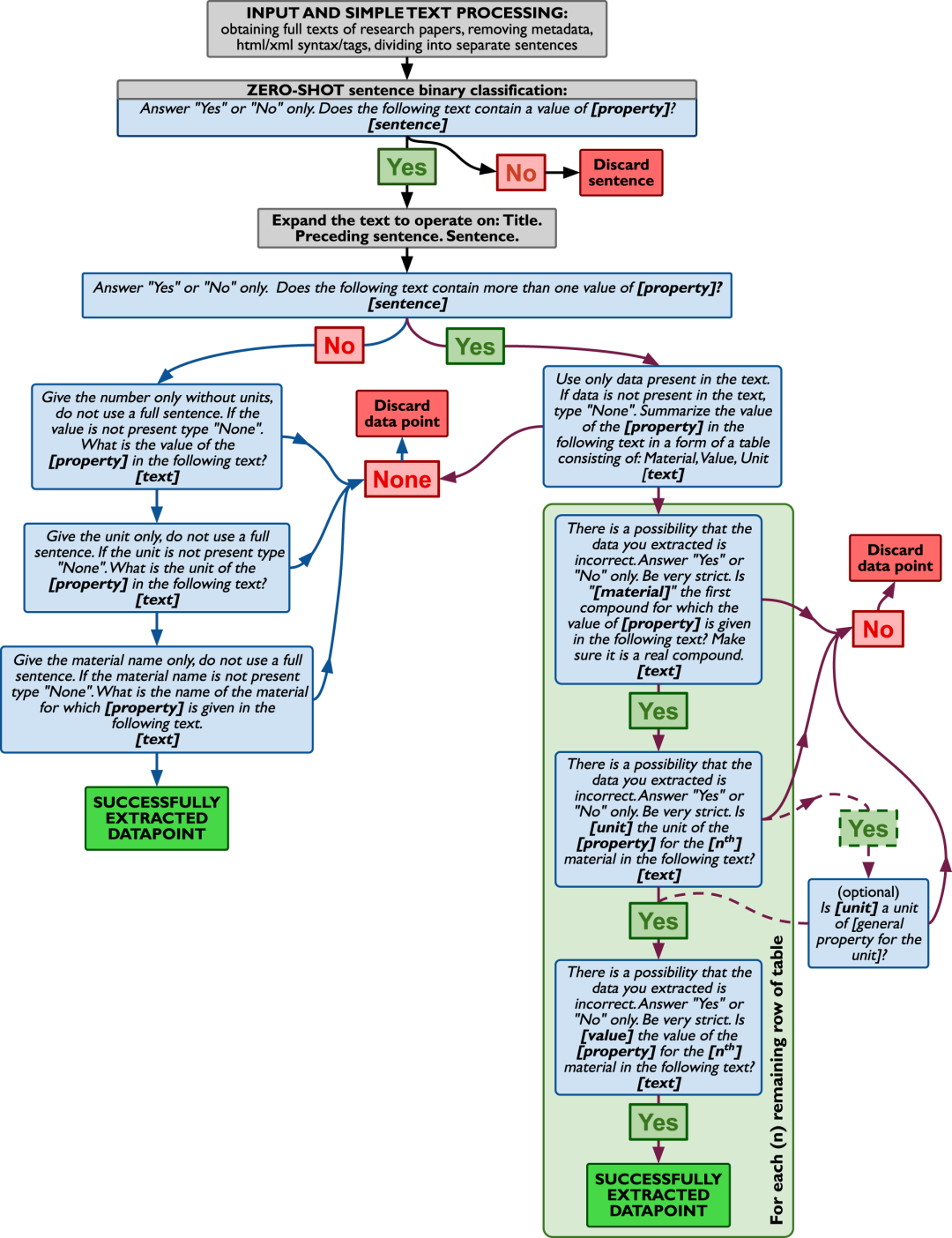
最新发表在Nature Communications的一项研究,提出了名为ChatExtract的方法,以最少的初始工作和背景,进行完全自动化的精准数据提取。ChatExtract由一组应用于会话式大模型的工程提示组成,这些提示既可以识别带有数据的句子,从而提取该数据,又可以通过一系列后续问题确保数据的正确性。作者通过一系列精心设计的提示(问题和指令)实现了材料属性的高效提取,表现为材料、值、单位的三元组形式。通过识别相关句子、要求模型提取数据详情,然后通过提出一系列后续问题来检查提取的详情,在数据提取任务中实现了高精确度(模型提取数据中有多少是准确)和高召回率(模型从所有应该提取的数据中成功提取的比例)。这种方法在测试数据集上达到了90.8%的精确度和87.7%的召回率,在实际数据库构建示例中达到了91.6%的精确度和83.6%的召回率。
ChatExtract框架可以结合任意的大模型使用,同时会受益于大模型的改进。因此,大模型的快速迭代,可能进一步支持ChatExtract和类似数据提取方法。该研究表明,大模型中的信息保留结合有目的的冗余,并通过后续提示引入不确定性,可以实现卓越的自动化数据提取能力。
图1 ChatExtract方法流程图。蓝色框代表给模型的提示,灰色框是给用户的指示,“是”、“否”和“无”框是模型的响应。“[]”中的粗体文本将替换为命名项的适当值。

点击“阅读原文”,报名读书会